实例1:京东商品页面的爬取
1.锁定网址
在京东页面找到一款手机复制网址
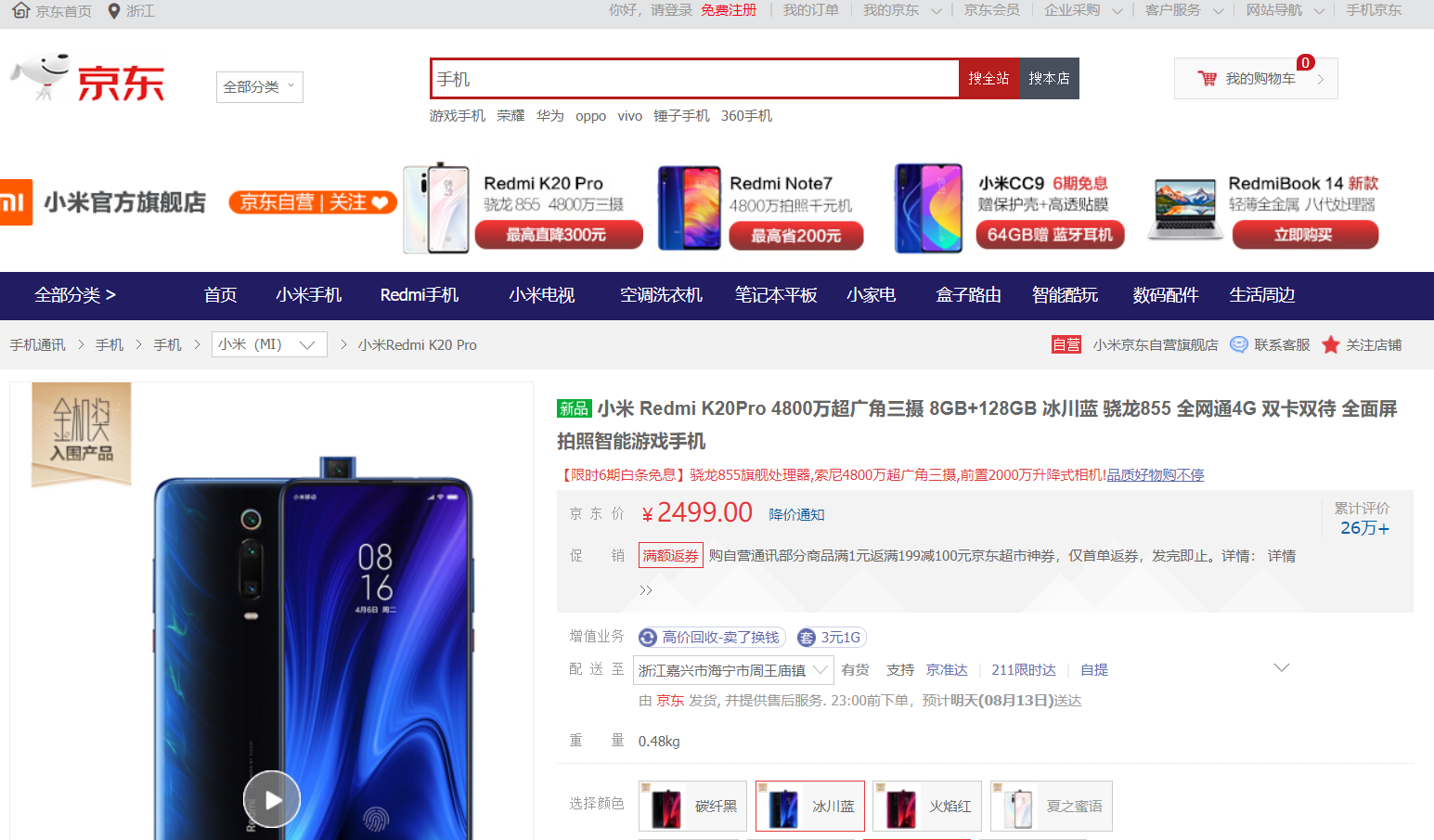
2. 进行爬取
2.1) 爬取代码
import requests url = "https://item.jd.com/100003534811.html" r = requests.get(url) print(r.status_code) #返回值为200,访问正常 print(r.text[:1000])#仅打印需要内容
2.2) 返回信息
<!DOCTYPE HTML>
<html lang="zh-CN">
<head>
<!-- shouji -->
<meta http-equiv="Content-Type" content="text/html; charset=gbk" />
<title>【小米Redmi K20 Pro】小米 Redmi K20Pro 4800万超广角三摄 8GB+128GB 冰川蓝 骁龙855 全网通4G 双卡双待 全面屏拍照智能游戏手机【行情 报价 价格 评测】-京东</title>
<meta name="keywords" content="MIRedmi K20 Pro,小米Redmi K20 Pro,小米Redmi K20 Pro报价,MIRedmi K20 Pro报价"/>
<meta name="description" content="【小米Redmi K20 Pro】京东JD.COM提供小米Redmi K20 Pro正品行货,并包括MIRedmi K20 Pro网购指南,以及小米Redmi K20 Pro图片、Redmi K20 Pro参数、Redmi K20 Pro评论、Redmi K20 Pro心得、Redmi K20 Pro技巧等信息,网购小米Redmi K20 Pro上京东,放心又轻松" />
<meta name="format-detection" content="telephone=no">
<meta http-equiv="mobile-agent" content="format=xhtml; url=//item.m.jd.com/product/100003534811.html">
<meta http-equiv="mobile-agent" content="format=html5; url=//item.m.jd.com/product/100003534811.html">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<link rel="canonical" href="//item.jd.com/100003534811.html"/>
<link
3. 全代码
import requests
url = "https://item.jd.com/100003534811.html"
try:
r = requests.get(url)
# 返回值为200则不会产生异常
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
实例2:亚马逊商品页面的爬取
1.锁定网址
在亚马逊页面找到一本书复制网址
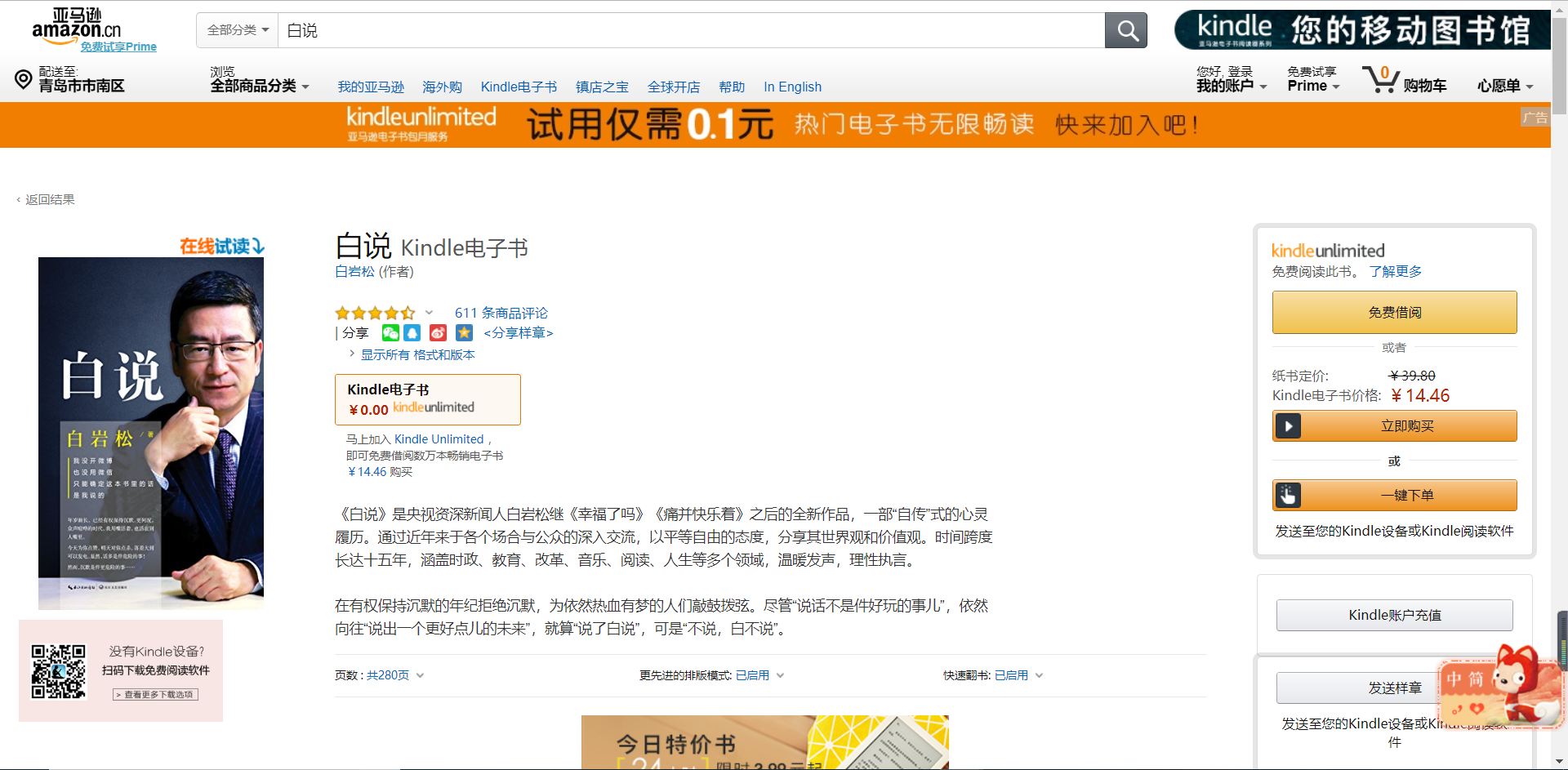
2.进行爬取
2.1) 爬取代码
import requests url = "https://www.amazon.cn/dp/B01H36S9MO/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E7%99%BD%E8%AF%B4&qid=1565584830&s=gateway&sr=8-1" r = requests.get(url) print(r.status_code)
2.2) 状态码反思
状态码返回值是503,不是200,说明访问出错
2.3) 打印文本内容


<!DOCTYPE html> <!--[if lt IE 7]> <html lang="zh-CN" class="a-no-js a-lt-ie9 a-lt-ie8 a-lt-ie7"> <![endif]--> <!--[if IE 7]> <html lang="zh-CN" class="a-no-js a-lt-ie9 a-lt-ie8"> <![endif]--> <!--[if IE 8]> <html lang="zh-CN" class="a-no-js a-lt-ie9"> <![endif]--> <!--[if gt IE 8]><!--> <html class="a-no-js" lang="zh-CN"><!--<![endif]--><head> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <title dir="ltr">Amazon CAPTCHA</title> <meta name="viewport" content="width=device-width"> <link rel="stylesheet" href="https://images-na.ssl-images-amazon.com/images/G/01/AUIClients/AmazonUI-3c913031596ca78a3768f4e934b1cc02ce238101.secure.min._V1_.css"> <script> if (true === true) { var ue_t0 = (+ new Date()), ue_csm = window, ue = { t0: ue_t0, d: function() { return (+new Date() - ue_t0); } }, ue_furl = "fls-cn.amazon.cn", ue_mid = "AAHKV2X7AFYLW", ue_sid = (document.cookie.match(/session-id=([0-9-]+)/) || [])[1], ue_sn = "opfcaptcha.amazon.cn", ue_id = '7M7370PKHPW590MJV57S'; } </script> </head> <body> <!-- To discuss automated access to Amazon data please contact api-services-support@amazon.com. For information about migrating to our APIs refer to our Marketplace APIs at https://developer.amazonservices.com.cn/index.html/ref=rm_c_sv, or our Product Advertising API at https://associates.amazon.cn/gp/advertising/api/detail/main.html/ref=rm_c_ac for advertising use cases. --> <!-- Correios.DoNotSend --> <div class="a-container a-padding-double-large" style="min-350px;padding:44px 0 !important"> <div class="a-row a-spacing-double-large" style=" 350px; margin: 0 auto"> <div class="a-row a-spacing-medium a-text-center"><i class="a-icon a-logo"></i></div> <div class="a-box a-alert a-alert-info a-spacing-base"> <div class="a-box-inner"> <i class="a-icon a-icon-alert"></i> <h4>请输入您在下方看到的字符</h4> <p class="a-last">抱歉,我们只是想确认一下当前访问者并非自动程序。为了达到最佳效果,请确保您浏览器上的 Cookie 已启用。</p> </div> </div> <div class="a-section"> <div class="a-box a-color-offset-background"> <div class="a-box-inner a-padding-extra-large"> <form method="get" action="/errors/validateCaptcha" name=""> <input type=hidden name="amzn" value="3vXJDVQq+SKJ44y9xdfMeA==" /><input type=hidden name="amzn-r" value="/dp/B01H36S9MO/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E7%99%BD%E8%AF%B4&qid=1565584830&s=gateway&sr=8-1" /> <div class="a-row a-spacing-large"> <div class="a-box"> <div class="a-box-inner"> <h4>请输入您在这个图片中看到的字符:</h4> <div class="a-row a-text-center"> <img src="https://images-na.ssl-images-amazon.com/captcha/xzqdsmvh/Captcha_ngaflmibnn.jpg"> </div> <div class="a-row a-spacing-base"> <div class="a-row"> <div class="a-column a-span6"> <label for="captchacharacters">输入字符</label> </div> <div class="a-column a-span6 a-span-last a-text-right"> <a onclick="window.location.reload()">换一张图</a> </div> </div> <input autocomplete="off" spellcheck="false" id="captchacharacters" name="field-keywords" class="a-span12" autocapitalize="off" autocorrect="off" type="text"> </div> </div> </div> </div> <div class="a-section a-spacing-extra-large"> <div class="a-row"> <span class="a-button a-button-primary a-span12"> <span class="a-button-inner"> <button type="submit" class="a-button-text">继续购物</button> </span> </span> </div> </div> </form> </div> </div> </div> </div> <div class="a-divider a-divider-section"><div class="a-divider-inner"></div></div> <div class="a-text-center a-spacing-small a-size-mini"> <a href="https://www.amazon.cn/gp/help/customer/display.html/ref=footer_claim?ie=UTF8&nodeId=200347160">使用条件</a> <span class="a-letter-space"></span> <span class="a-letter-space"></span> <span class="a-letter-space"></span> <span class="a-letter-space"></span> <a href="https://www.amazon.cn/gp/help/customer/display.html/ref=footer_privacy?ie=UTF8&nodeId=200347130">隐私声明</a> </div> <div class="a-text-center a-size-mini a-color-secondary"> © 1996-2015, Amazon.com, Inc. or its affiliates <script> if (true === true) { document.write('<img src="https://fls-cn.amaz'+'on.cn/'+'1/oc-csi/1/OP/requestId=7M7370PKHPW590MJV57S&js=1" />'); }; </script> <noscript> <img src="https://fls-cn.amazon.cn/1/oc-csi/1/OP/requestId=7M7370PKHPW590MJV57S&js=0" /> </noscript> </div> </div> <script> if (true === true) { var elem = document.createElement("script"); elem.src = "https://images-cn.ssl-images-amazon.com/images/G/01/csminstrumentation/csm-captcha-instrumentation.min._V" + (+ new Date()) + "_.js"; document.getElementsByTagName('head')[0].appendChild(elem); } </script> </body></html>
根据打印文本内容中包含Marketplace APIs 判断该次访问出错由于API造成,事实上,如果我们能够从服务器获得网页信息,那么这个错误不再是网络错误。
2.4) 打印头部信息
# 打印发给亚马逊网站的头部信息
print(r.request.headers)
# 头部信息内容
{'User-Agent': 'python-requests/2.21.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
根据打印的头部信息我们可以看出我们的爬虫忠实的告诉了服务器我们的访问是一个python-requests库程序发起的,如果亚马逊服务器启动了来源审查,则此类访问会产生错误。
2.5) 修改头部信息
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url, headers = kv)
print(r.status_code)
print(r.request.headers)
打印内容
200
{'user-agent': 'Mozilla/5.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
2.6) 与京东爬取的区别
修改header字段,模拟浏览器向亚马逊服务器申请访问。
3.全代码
import requests
url = "https://www.amazon.cn/dp/B01H36S9MO/ref=sr_1_1?__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&keywords=%E7%99%BD%E8%AF%B4&qid=1565584830&s=gateway&sr=8-1"
try:
kv = {'user-agent':'Mozilla/5.0'}
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print("爬取失败")
实例3:百度/360搜索关键字提交
1. 搜索引擎关键词提交接口
百度的关键词接口 http://www.baidu.com/s?wd=keyword
360的关键词接口 https://www.so.com/s?q=keyword
2. 百度搜索引擎爬取信息
2.1) 百度关键字提交
import requests
url = "http://www.baidu.com/s"
kv = {'wd':'Python'}
r = requests.get(url, params=kv)
print(r.status_code) # 打印状态码
print(r.request.url) # 打印访问链接
print(r.text) # 打印文本内容
print(len(r.text)) # 打印文本长度
2.2) 百度关键字提交打印内容
# 状态码 200 # 访问链接打印 http://www.baidu.com/s?wd=Python # 文本内容打印 <!DOCTYPE html><html><body style="display:none"><script>function ii(a,t){var r=Math.floor(Math.random()*100);t=t||"baidu";for(var i in a){if(a.hasOwnProperty(i)){if(a[i]>r){t=i;break}else{r-=a[i]}}};return t;}var D=document,N=navigator||{},U=N.userAgent,L=location||{},H=L.hash||'#',S=L.search||'?',M=0,W='',I='',E='',P='',R='',X=RegExp;!function(){function d(a,n){var e="; expires=Mon,01-Jan-1973 00:00:01 GMT",c=a.length,b=a[c-1];var f=e+"; path=/";if(n){D.cookie=n+"="+e;D.cookie=n+"="+f;for(var i=c-2;i>=0;i--){b=a[i]+"."+b;D.cookie=n+"=; domain="+b+e;D.cookie=n+"=; domain="+b+f;D.cookie=n+"=; domain=."+b+e;D.cookie=n+"=; domain=."+b+f}}}(function(){var a=D.cookie.split("; ");for(var i=0;i<a.length;i++){d(location.hostname.split("."),a[i].split("=")[0])}})()}();if(/AppleWebKit.*Mobile/i.test(U)||(/MIDP|SymbianOS|NOKIA|SAMSUNG|LG|NEC|TCL|Alcatel|BIRD|DBTEL|Dopod|PHILIPS|HAIER|LENOVO|MOT-|Nokia|SonyEricsson|SIE-|Amoi|ZTE|Android/.test(U)))M=1;if(/iPad/i.test(U))M=0;var a=S.split("?"),b=a[1].split("&"),c,i,p,q;for(i=0;i<b.length;i++){c=b[i].split("=");p=c[0];q=c[1];if(/^(w|wd|word)=/.test(b[i]))W=q;if(b[i]=='ms=1'||b[i]=='mobile_se=1')M=1;if(p=="ie")E=q;if(p=="pn")P=q;if(p=="rn")R=q;}if(/[^a-zA-Z0-9]wd=([^&]+)/.test(H))W=X.$1;var t,u="https://www.baidu.com/";if(M){u="https://m.baidu.com/";t=ii({"1015467z":100});if(W)u=u+"from="+t+"/s?word="+W;else u=u+"?from="+t;}else{u=u+'s?wd='+W+'&tn='+ii({"90757376_hao_pg":100});}if(E)u=u+'&ie='+E;if(P)u=u+'&pn='+P;if(R)u=u+'&rn='+R;j=!1;if(/firefox/i.test(U)){j=!0;D.write('<meta http-equiv="Refresh" target="_top" Content="0; Url='+u+'" >')}if(/msie 9|msie 10|rv:11/i.test(U)){j=!0;try{top.navigate(u)}catch(_){j=!1}}if(/applewebkit/i.test(U)){j=!0;var h=D.createElement('a');h.rel='noreferrer';h.href=u;h.target='_top';D.body.appendChild(h);var e=D.createEvent('MouseEvents');e.initEvent('click',true,true);h.dispatchEvent(e);}</script><iframe src='javascript:"<html><head><script>function init(){D=document;A=D.getElementById("aa");u=parent.u||"https://www.baidu.com/?tn=dsp";A.href=u;j=parent.j||!1;if(!j)try{A.click();}catch(_){setTimeout(function(){top.location.replace(u)},100)}}</script></head><body onload="init()"><a id="aa" rel="noreferer" target="_top"></a></body></html>"'></iframe></body></html> # 文本内容长度 2279
params字段的使用方法参见网络爬虫_Requests库入门中Requests库主要方法解析
2.3) 百度关键字提交全代码
import requests
url = "http://www.baidu.com/s"
keyword = "Python"
try:
kv = {'wd':keyword}
r = requests.get(url, params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
3. 360搜索引擎爬取信息
3.1) 360关键字提交
import requests
url = "http://www.so.com/s"
kv = {'q':'Python'}
r = requests.get(url, params=kv)
print(r.status_code) # 打印状态码
print(r.request.url) # 打印访问链接
print(r.text) # 打印文本内容
print(len(r.text)) # 打印文本长度
3.2) 360关键字提交全代码
import requests
url = "http://www.so.com/s"
keyword = "Python"
try:
kv = {'q':keyword}
r = requests.get(url, params=kv)
print(r.request.url)
r.raise_for_status()
print(len(r.text))
except:
print("爬取失败")
实例4:网络图片的爬取和存储
1. 网络图片的格式
网络图片链接的格式 http://www.example.com/picture.jpg
图片地址:
http://image.ngchina.com.cn/userpic/103315/2019/08121402011033159713.jpeg
2. 网络图片爬取代码
import requests
path = "D://abc.jpg" # 图片存储地址
url = "http://image.ngchina.com.cn/userpic/103315/2019/08121402011033159713.jpeg"
r = requests.get(url)
print(r.status_code) # 打印状态码
with open(path, 'wb') as f:
f.write(r.content) # content 字段包含二进制信息
f.close()
3. 网络图片爬取全代码
import requests
import os
url = "http://image.ngchina.com.cn/userpic/103315/2019/08121402011033159713.jpeg"
root = "F://picture//"
path = root + url.split('/')[-1] # 代表最后一个/之后的内容
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
实例5:IP地址归属地的自动查询
利用ip138网站的查询功能
import requests
url = "http://m.ip138.com/ip.asp?ip="
ipadress = '202.204.80.112'
try:
r = requests.get(url+ipadress)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
爬取内容打印
value="查询" class="form-btn" /> </form> </div> <div class="query-hd">ip138.com IP查询(搜索IP地址的地理位置)</div> <h1 class="query">您查询的IP:202.204.80.112</h1><p class="result">本站主数据:北京市海淀区 北京理工大学 教育网</p><p class="result">参考数据一:北京市 北京理工大学</p> </div> </div> <div class="footer"> <a href="http://www.miitbeian.gov.cn/" rel="nofollow" target="_blank">沪ICP备10013467号-1</a> </div> </div> <script type="text/javascript" src="/script/common.js"></script></body> </html>
本节重点
以爬虫视角看待网络内容。(网络内容为url网络连接所指内容)
爬虫规则部分测试题
1 下面哪个不是Python Requests库提供的方法?
-
A.
.head()
-
B.
.get()
-
C.
.post()
-
D.
.push()
Requests库中,下面哪个是检查Response对象返回是否成功的状态属性?
-
A.
.status
-
B.
.raise_for_status
-
C.
.headers
-
D.
.status_code
Requests库中,下面哪个属性代表了从服务器返回HTTP协议头所推荐的编码方式?
-
A.
.apparent_encoding
-
B.
.encoding
-
C.
.headers
-
D.
.text
Requests库中,下面哪个属性代表了从服务器返回HTTP协议内容部分猜测的编码方式?
-
A.
.text
- B..encoding
-
C.
.headers
- D..apparent_encoding
- A.requests.ConnectionError
-
B.
requests.URLRequired
- C.requests.HTTPError
-
D.
requests.Timeout
以下哪个是不合法的HTTP URL?
- A.https://223.252.199.7/course/BIT-1001871002#/
- B.
https://210.14.148.99/
-
C.
https://dwz.cn/hMvN8
- D.news.sina.com.cn:80
在Requests库的get()方法中,能够定制向服务器提交HTTP请求头的参数是什么?
- A.data
-
B.
ookies
- C.headers
-
D.
json
在Requests库的get()方法中,timeout参数用来约定请求的超时时间,请问该参数的单位是什么?
- A.秒
-
B.
微秒
- C.毫秒
-
D.
分钟
下面哪个不是网络爬虫带来的负面问题?
-
A.
商业利益
-
B.
法律风险
- C.隐私泄露
-
D.
性能骚扰
下面哪个说法是不正确的?
- A.Robots协议告知网络爬虫哪些页面可以抓取,哪些不可以。
-
B.
Robots协议是互联网上的国际准则,必须严格遵守。
- C.Robots协议可以作为法律判决的参考性“行业共识”。
-
D.
Robots协议是一种约定。
如果一个网站的根目录下没有robots.txt文件,下面哪个说法是不正确的?
- A.网络爬虫可以不受限制的爬取该网站内容并进行商业使用。
-
B.
网络爬虫可以肆意爬取该网站内容。
- C.网络爬虫的不当爬取行为仍然具有法律风险。
-
D.
网络爬虫应该以不对服务器造成性能骚扰的方式爬取内容。
12
百度的关键词查询提交接口如下,其中,keyword代表查询关键词:
https://www.baidu.com/s?wd=keyword
请问,提交查询关键词该使用Requests库的哪个方法?
- A..get()
-
B.
.post()
- C..put()
-
D.
.patch()
获取网络上某个URL对应的图片或视频等二进制资源,应该采用Response类的哪个属性?
- A..head
-
B.
.content
- C..text
-
D.
.status_code
Requests库中的get()方法最常用,下面哪个说法正确?
- A.网络爬虫主要进行信息获取,所以,get()方法最常用。
-
B.
HTTP协议中GET方法应用最广泛,所以,get()方法最常用。
- C.服务器因为安全原因对其他方法进行限制,所以,get()方法最常用。
-
D.
get()方法是其它方法的基础,所以最常用。
下面哪些功能网络爬虫做不到?
- A.持续关注某个人的微博或朋友圈,自动为新发布的内容点赞。
-
B.
爬取某个人电脑中的数据和文件。
- C.分析教务系统网络接口,用程序在网上抢最热门的课。
-
D.
爬取网络公开的用户信息,并汇总出售。
- try:
- r = requests.get(url)
- r.__________________()
- r.encoding = r.apparent_encoding
- print(r.text)
- except:
- print("Error")
请在上述网络爬虫通用代码框架中,填写空格处的方法名称。
在HTTP协议中,能够对URL进行局部更新的方法是什么?
- >>> kv = {'k': 'v', 'x': 'y'}
- >>> r = requests.request('GET', 'https://python123.io/ws', params=kv)
- >>> print(r.url)
上述代码的输出结果是什么?
某一个网络爬虫叫NoSpider,编写一个Robots协议文本,限制该爬虫爬取根目录下所有.html类型文件,但不限制其它文件。请填写robots.txt中空格内容:
- User-agent:NoSpider
- Disallow:___________
20
- >>>import requests
- >>>r = requests.get(url)
请填写下面语句的空格部分,使得该语句能够输出向服务器提交的url链接。
-
>>>print(r.____________)
爬虫_规则测试题参考答案
- D
- D
- B
- D
- A
- D
- C
- A
- A
- B
- A
- A
- B
- C
- B
- raise_for_status
- patch
- https://python123.io/ws?k=v&x=y
- /*.html
- request.url