去年热情高涨的时候心血来潮做了个简易的查询脚本,限于当时技术水平(菜),实现得不是很好,这几天终于想起来填坑了。环境依赖:
brew install python3 pip3 install requests pip3 install tkinter pip3 install fuzzywuzzy pip3 install xlrd
首先,CUP教务处考试安排通知一般是发布在网站的“考试通知”专栏里的。比如:
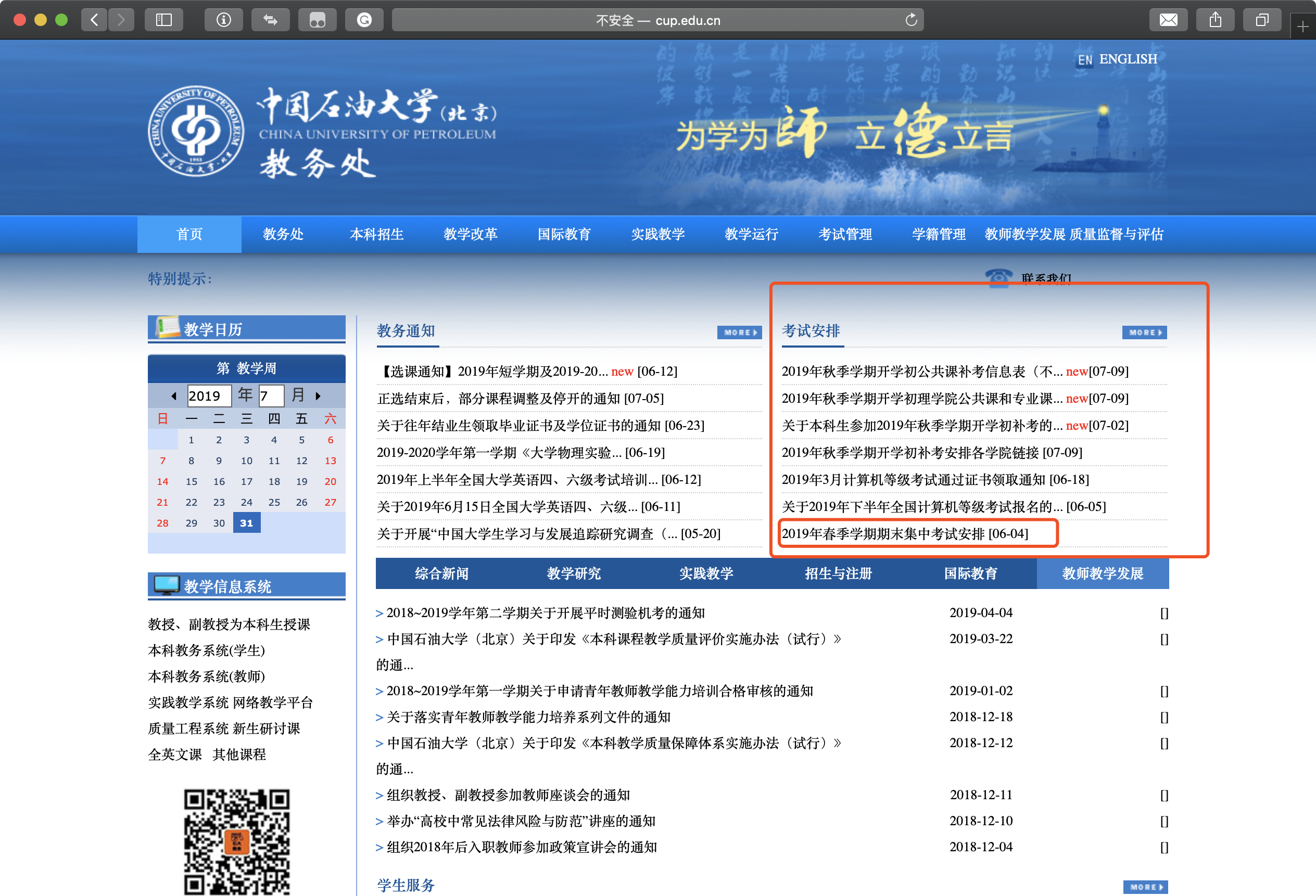
这样的一个通知,通常内部会有一个考试通知的xls表格文件。
打开以后:
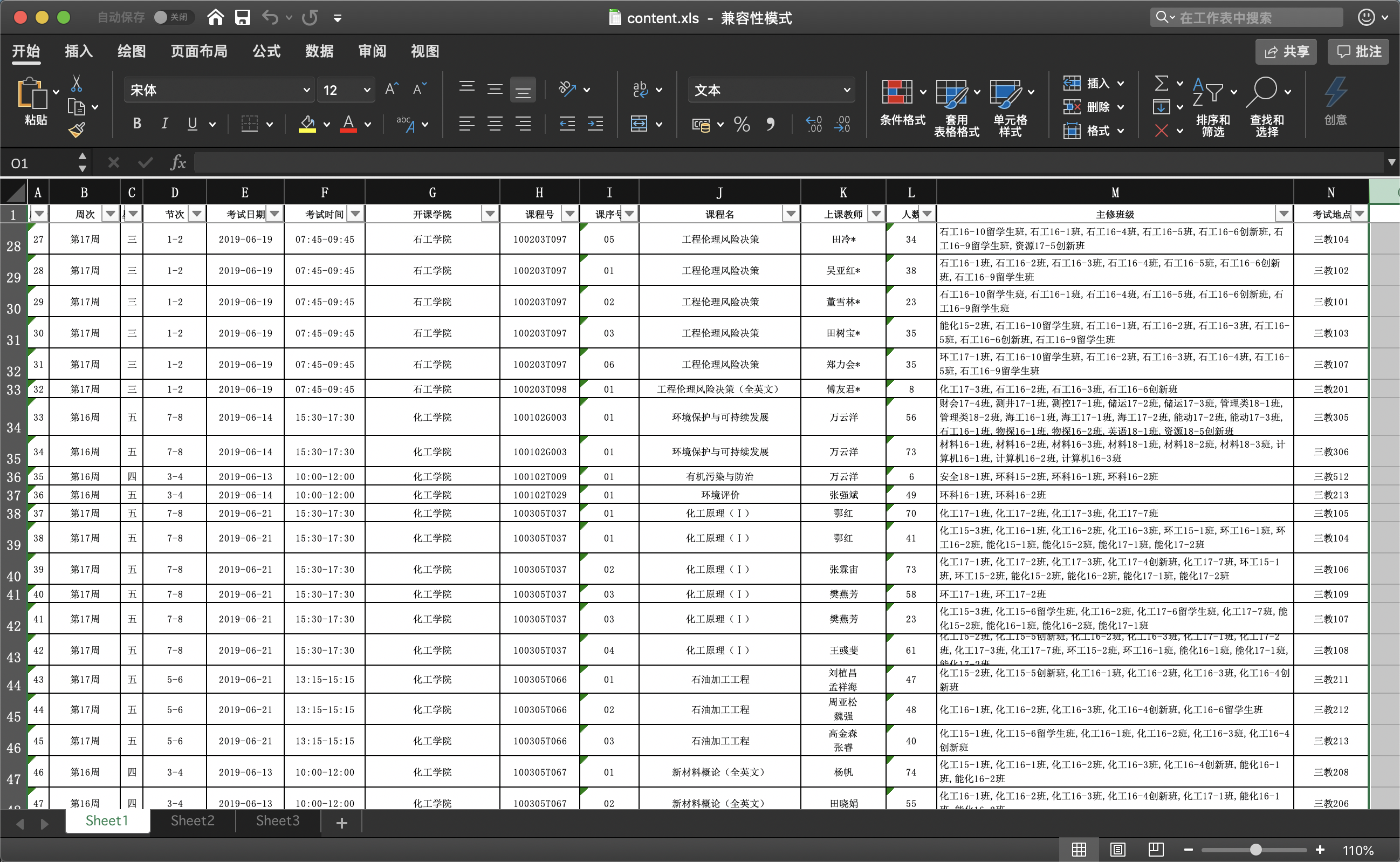
每次考试通知的格式都是一致的。
基于此,思路就来了,先输入考试通知发布网页的地址,然后程序自动获取到文件的下载地址,再自动将文件下载下来,得到考试安排信息。
代码:
def get_one_page(url, headers): try: response = requests.get(url, headers=headers) if response.status_code == 200: response.encoding = response.apparent_encoding return response.text return None except RequestException: return None def countPoint(UrlPart): cnt = 0 for i in UrlPart: if i != '.': break cnt += 1 return cnt def getNewXls(url): html = get_one_page(url, headers=headers) if not html: return False als = re.findall('<a.*?href="(.*?)"', html, re.S) for a in als: if a.endswith('xls'): cnt = countPoint(a) url = '/'.join(url.split('/')[:-cnt]) + a[cnt:] break content = requests.get(url, headers).content with open('content.xls', 'wb') as f: f.write(content) return True
在得到考试安排信息后,我分析可以通过“课程&教师&班级”三种条件可以比较精确的搜索到要查询的考试安排。
通过这三个列名,可以建立一个简易的搜索字典:
data = {'课程名': {}, '上课老师': {}, '主修班级': {}}
def init(): xls = xlrd.open_workbook('content.xls') global name_col, teacher_col, sc_col, sheet sheet = xls.sheet_by_index(0) keys = sheet.row_values(0) for i in range(len(keys)): if keys[i] == '课程名': name_col = i elif keys[i] == '上课教师': teacher_col = i elif keys[i] == '主修班级': sc_col = i if not name_col or not teacher_col or not sc_col: exit('Unknown xls layout') ls = sheet.col_values(name_col) for i in range(1, len(ls)): if ls[i] not in data['课程名']: data['课程名'][ls[i]] = set() data['课程名'][ls[i]].add(i) ls = sheet.col_values(teacher_col) for i in range(1, len(ls)): if ls[i] not in data['上课老师']: data['上课老师'][ls[i]] = set() data['上课老师'][ls[i]].add(i) ls = sheet.col_values(sc_col) for i in range(1, len(ls)): cls = ls[i].split(',') for cl in cls: if cl not in data['主修班级']: data['主修班级'][cl] = set() data['主修班级'][cl].add(i)
而考虑查询方便,必然不可能让用户(我)每次都输入精准的信息才能查到结果,这太不酷了。
所以我考虑间隔匹配+模糊匹配的方式来得到搜索结果。
间隔匹配:
def fm(string, ls): res = [] match = '.*?'.join([i for i in string]) for i in ls: if re.findall(match, i): res.append((i, 100)) return res
模糊匹配:(这里使用了一个叫fuzzywuzzy的第三方库,只有间隔匹配失败后才会使用模糊匹配)
res = fm(aim, data[keys[i]].keys()) if not res: res = process.extract(aim, data[keys[i]].keys(), limit=3)
那么如果用户提供了多个搜索条件怎么处理呢?答案是利用集合的并交运算来处理。
比如搜索表达式: xx&yy&zz。显然我们通过搜索算法可以得到三个独立集合分别为xx,yy和zz的结果,那么对这三个集合取交即可得到正解。
def search(exp): if not pre_check(): return None keys = ['课程名', '上课老师', '主修班级'] res_set = set() flag = False for i in range(len(exp)): if i < 3: aim = exp[i].strip() if not aim: continue res = fm(aim, data[keys[i]].keys()) if not res: res = process.extract(aim, data[keys[i]].keys(), limit=3) ts = set() for mth in res: if mth[1]: ts = ts.union(data[keys[i]][mth[0]]) if flag: res_set = res_set.intersection(ts) else: res_set = res_set.union(ts) flag = True else: break res = '' for line_num in res_set: line = sheet.row_values(line_num) res += '-' * 50 + ' ' res += '课程名称:' + line[name_col] + ' ' res += '授课教师:' + line[teacher_col].replace(' ', ',') + ' ' cls = line[sc_col].split(',') linkstr = '' for i in range(len(cls)): linkstr += cls[i] if i + 1 == len(cls): break elif (i + 1) % 5 == 0: linkstr += ' ' + ' ' * 9 else: linkstr += ',' res += '主修班级:' + linkstr + ' ' day = "%04d年%02d月%02d日" % xldate_as_tuple(line[4], 0)[:3] res += '考试时间:' + day + '(周%s) ' % line[2] + line[5] + ' ' res += '考试地点:' + line[-1].replace(' ', ',') + ' ' return res
到这,脚本的硬核部分就结束了~
然后我们基于这份代码,撸一个GUI出来。
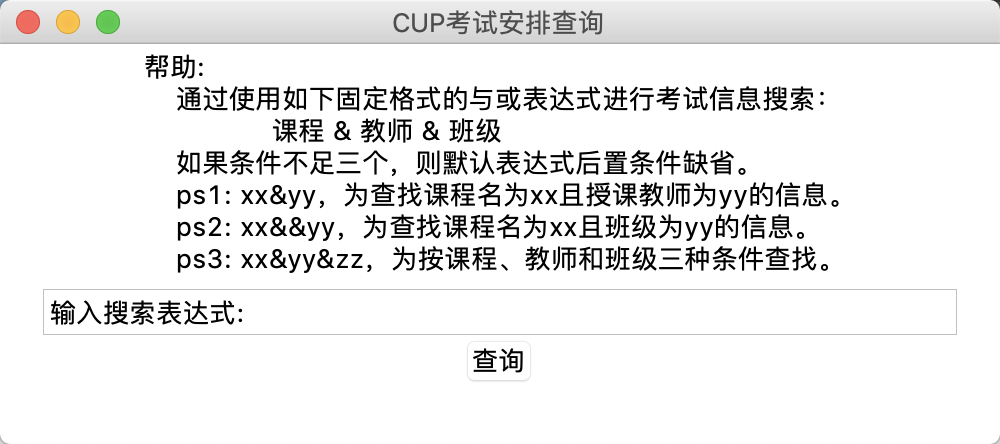
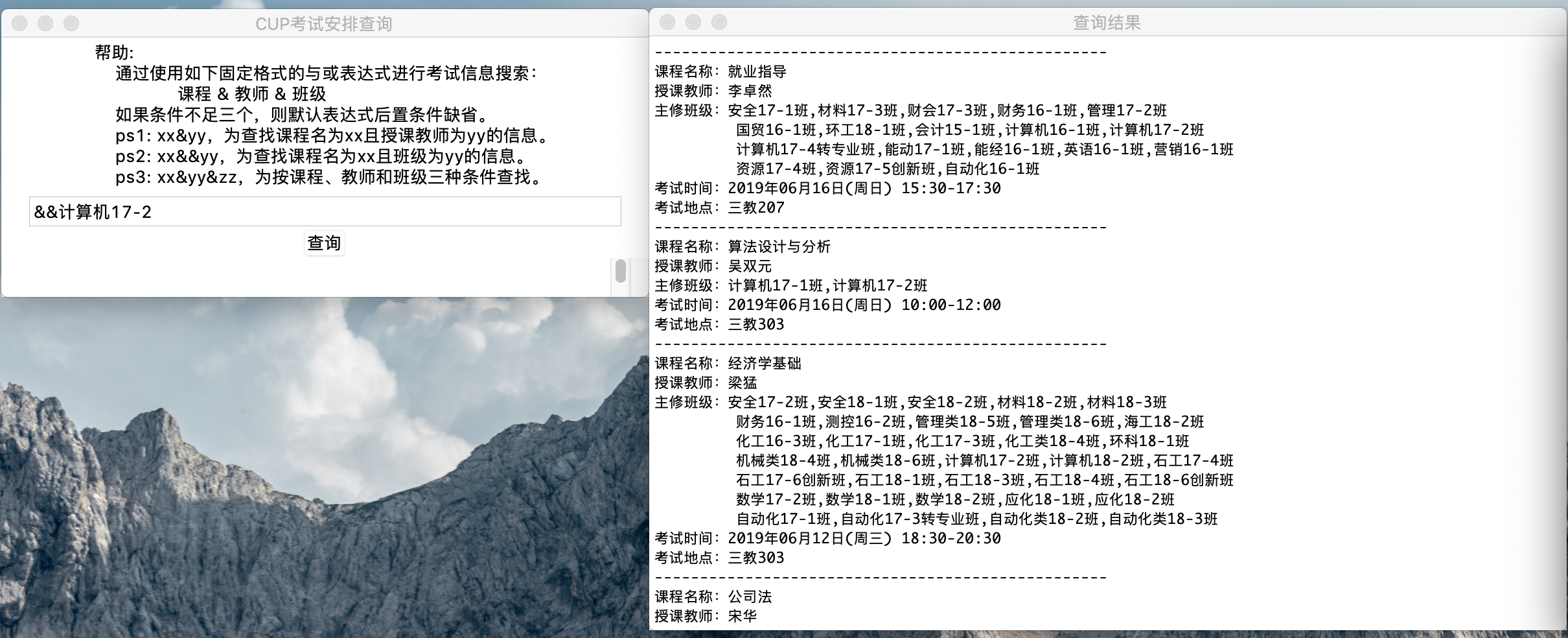
大功告成~!
GitHub开源地址:https://github.com/Rhythmicc/CUP_EXAM