首先先创建一个目标文件words,将其保存至/home/hadoop目录下:
cd /home/hadoop
vim words
# 向新文件中添加内容,例如:data mining on data warehouse
# 在HDFS创建一个目录
hdfs dfs -mkdir /user/hadoop/input
# 将刚创建的words文件上传到刚创建的HDFS目录中
hdfs dfs -put /home/hadoop/words /user/hadoop/input
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /user/hadoop/input /user/hadoop/output

注:1表示的是测试用例名;
2表示的是输入的文件;
3表示的是输出目录;
4表示的是程序所在位置(Hadoop安装目录下的share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar) ;
# 查看运行结果
hdfs dfs -cat /user/hadoop/output/part-r-00000
结果示例如下:
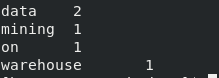
注:
若在此过程中遇到了Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster这样的错误,
解法的方法是找到hadoop安装目录下的etc/hadoop/mapred-site.xml,增加以下代码:
<property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property>