1、添加一个hadoop用户,并为其设置密码:
# 添加hadoop用户
sudo useradd hadoop
# 设置hadoop用户密码
passwd hadoop
注:其实也可以直接使用当前正在使用的这个普通用户而不去重新创建新用户。
2、修改主机名:(需要重启虚拟机才能看见效果)
方式一:
sudo vim /etc/hostname
清空该文件然后直接输入主机名,例如:
Master
方式二:
sudo vim /etc/sysconfig/network
在文件中输入如下代码:
NETWORKING=yes
HOSTNAME=Master
3、使安装Hadoop的节点之间能够使用主机名进行相互访问:
sudo vim /etc/hosts
在文件末尾添加如下代码(IP地址根据实际情况而变)
192.168.89.12 Master 192.168.89.14 Slave
注:若有其他节点,可照例添加。
4、配置SSH无密码登入节点:
首先需要关闭防火墙:
systemctl stop firewalld.service
注:
查看防火墙的状态:
systemctl status firewalld.service
打开防火墙:(相对于关闭而言)
systemctl start firewalld.service
禁用防火墙:
systemctl disable firewalld.service
开启防火墙:(相对于禁用而言)
systemctl enable firewalld.service
生成SSH公钥(一直回车直至显示了一个图案为止)
cd ~/.ssh # 若无该目录可先直接创建一个
ssh-keygen -t rsa
cat ./id_rsa.pub >> authorized_keys
注:在cat命令中>意思是创建,>>是追加
ssh Master
# 可能会遇到提示信息,只要输入yes即可
# 若登入成功即表示配置完成,记得使用exit命令退出登入
若登入时还是需要输入密码,则是文件权限没有配置好,输入以下代码即可:
chmod 700 ~/.ssh/ chmod 644 ~/.ssh/authorized_keys
到目前为止我们只能够无密码登入本机,现在来配置无密码登入其他节点:
将Master节点上的公钥传输到Slave节点上:
方法一:
scp ~/.ssh/id_rsa.pub hadoop@Slave:/home/hadoop/ # 另一个节点的名称根据具体情况而变
接下来进入Slave节点进行操作:
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在,则忽略本命令
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完以后就可以删掉
回到Master节点输入:
ssh Slave

方法二:
ssh-copy-id -i ~/.ssh/id_rsa.pub bruce@Slave # 节点名称根据具体实际情况而变
ssh Slave
注:若登入Slave节点时还是需要输入密码或者显示权限不够,则只需要进入Slave节点中输入以下代码即可:
chmod 700 ~/.ssh/ chmod 644 ~/.ssh/authorized_keys
5、安装JDK: (推荐使用oracle JDK)
下载网址:https://www.oracle.com/java/technologies/javase-downloads.html
百度网盘链接:https://pan.baidu.com/s/1_ATf9IwAl9oGzHiNxVQEvQ 提取码:jskx
查看之前是否安装了jdk rpm -qa |grep jdk 若安装了,则删除已有的jdk yum -y remove xxx # xxx为上一个命令的返回结果
将JDK安装包移动到/opt文件夹下,执行如下代码:
sudo tar -xzvf jdk-14.0.2_linux-x64_bin.tar.gz
注:
x : 从 tar 包中把文件提取出来
z : 表示 tar 包是被 gzip 压缩过的,所以解压时需要用 gunzip 解压
v : 显示详细信息
f xxx.tar.gz : 指定被处理的文件是 xxx.tar.gz
配置环境变量:
sudo vim /etc/profile # 在文件末尾添加如下代码 export JAVA_HOME=/opt/jdk-14.0.2 export PATH=$PATH:$JAVA_HOME/bin
重启脚本
source /etc/profile
java -version
若出现如下显示,则说明安装成功

6、安装Hadoop:
官网链接:https://hadoop.apache.org/releases.html
百度网盘:https://pan.baidu.com/share/init?surl=gbmPBXrJDCxwqPGkfvX5Xg 提取码:lnwl
将hadoop安装包移动到/opt文件夹下,执行如下代码:
cd /opt
sudo tar -zxvf hadoop-3.1.3
修改hadoop的配置文件:
sudo mv ./hadoop-3.1.3 ./hadoop # 重命名(便于操作)
cd /opt/hadoop/etc/hadoop # 进入hadoop配置文件所在的目录
ls
在hadoop-env.sh文件末尾添加环境变量:
export JAVA_HOME=/opt/jdk1.8.0_162
export HADOOP_HOME=/opt/hadoop
在core-site.xml文件中添加如下代码:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://Master:9000</value>
</property>
</configuration>
在hdfs-site.xml文件中添加如下代码:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hdfs/data</value>
</property>
</configuration>
在mapred-site.xml文件中添加如下代码:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
在yarn-site.xml文件中添加如下代码:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
将workers文件清空,然后将个其他节点的名称添加进来,例如:
Slave
配置Hadoop的环境变量,在/etc/profile文件末尾添加如下代码:
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
# 重新启动脚本
source /ect/profile
7、格式化HDFS:
# 在第一次启动Hadoop之前必须先将HDFS格式化
hadoop namenode -format
注:若格式化过程中出现格式化HDFS出现java.io.IOException: Cannot create directory /opt/hdfs/name/current错误,请参考https://www.cnblogs.com/ReturnOfTheKing/p/13542934.html
8、启动Hadoop并验证安装是否成功:
chmod +x -R /opt/hadoop/sbin
source /opt/hadoop/sbin/start-all.sh
# 在Master节点和Slave节点分别使用如下命令
jps
若在Master节点上出现了NameNode、ResourceManager、SecondaryNameNode;
且在Slave节点上出现了DataNode、NodeManager。
则表明Hadoop安装成功。
注:若ResourceManager和NodeManager没有启动,而NameNode、SecondaryNameNode、DataNode启动了,请参考https://www.cnblogs.com/ReturnOfTheKing/p/13546125.html
# 测试集群有没有成功启动
hdfs dfsadmin -report
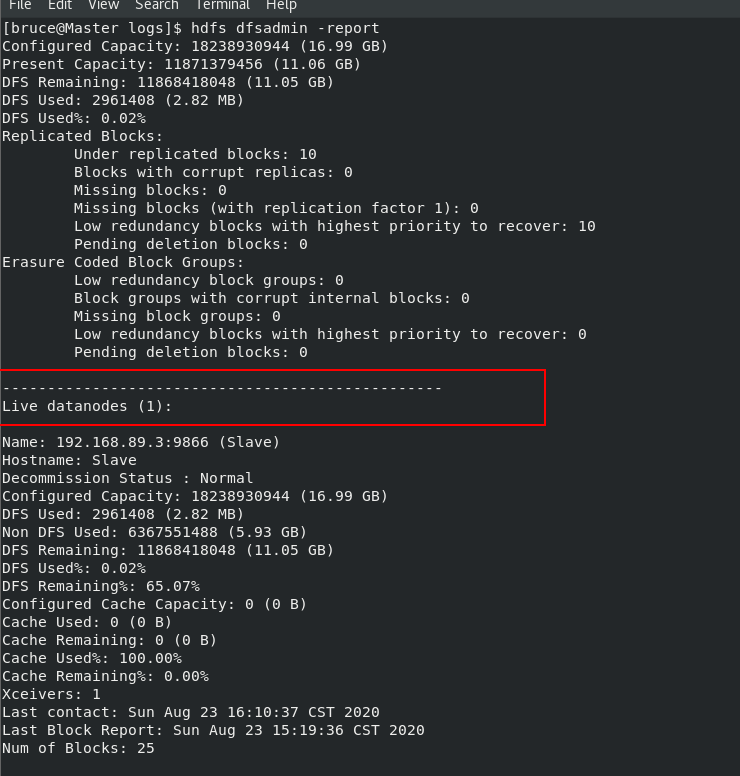
若如上图一样出现了Live datanodes,则表明hadoop集群已成功启动。
——————待续!