变分自编码器
一、总结
一句话总结:
【将概率图跟深度学习结合起来的一个非常棒的案例】:总的来说,VAE的思路还是很漂亮的。倒不是说它提供了一个多么好的生成模型(因为事实上它生成的图像并不算好,偏模糊),而是它提供了一个将概率图跟深度学习结合起来的一个非常棒的案例,这个案例有诸多值得思考回味的地方。
1、VAE和GAN其实都是风格变换?
【构建一个从隐变量Z生成目标数据X的模型】:通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量Z生成目标数据X的模型,但是实现上有所不同。
【训练一个模型X=g(Z)】:更准确地讲,它们是假设了Z服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型X=g(Z),这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
2、生成模型的难题?
【生成分布与真实分布的相似度】:生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
3、KL散度?
【KL散度是根据两个概率分布的表达式来算它们的相似度的】:得有概率分布的表达式才能算相似度
4、生成式网络中我们怎么判断 生成的图像和数据集真实图像的分布是不一样的?
【GAN的思路很直接粗犷:既然没有合适的度量,那我干脆把这个度量也用神经网络训练出来吧。就这样,WGAN就诞生了】:详细过程请参考《互怼的艺术:从零直达WGAN-GP》。
【而VAE则使用了一个精致迂回的技巧】。
5、在整个VAE模型中,我们用的是假设p(Z|X)(后验分布)是正态分布?
其实,在整个VAE模型中,我们并没有去使用p(Z)(隐变量空间的分布)是正态分布的假设,我们用的是假设p(Z|X)(后验分布)是正态分布!!
6、VAE的本质是什么?
【一个用来计算均值,一个用来计算方差】:在VAE中,它的Encoder有两个,一个用来计算均值,一个用来计算方差,这已经让人意外了:Encoder不是用来Encode的,是用来算均值和方差的,这真是大新闻了,还有均值和方差不都是统计量吗,怎么是用神经网络来算的?
【它本质上就是在我们常规的自编码器的基础上,对encoder的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”】:使得结果decoder能够对噪声有鲁棒性;而那个额外的KL loss(目的是让均值为0,方差为1),事实上就是相当于对encoder的一个正则项,希望encoder出来的东西均有零均值。
7、VAE似乎也有对立过程?
【重构的过程是希望没噪声的,而KL loss则希望有高斯噪声的,两者是对立的】:所以,VAE跟GAN一样,内部其实是包含了一个对抗的过程,只不过它们两者是混合起来,共同进化的。
二、变分自编码器
转自或参考:变分自编码器(一):原来是这么一回事
https://www.spaces.ac.cn/archives/5253
过去虽然没有细看,但印象里一直觉得变分自编码器(Variational Auto-Encoder,VAE)是个好东西。于是趁着最近看概率图模型的三分钟热度,我决定也争取把VAE搞懂。于是乎照样翻了网上很多资料,无一例外发现都很含糊,主要的感觉是公式写了一大通,还是迷迷糊糊的,最后好不容易觉得看懂了,再去看看实现的代码,又感觉实现代码跟理论完全不是一回事啊。
终于,东拼西凑再加上我这段时间对概率模型的一些积累,并反复对比原论文《Auto-Encoding Variational Bayes》,最后我觉得我应该是想明白了。其实真正的VAE,跟很多教程说的的还真不大一样,很多教程写了一大通,都没有把模型的要点写出来~于是写了这篇东西,希望通过下面的文字,能把VAE初步讲清楚。
分布变换 #
通常我们会拿VAE跟GAN比较,的确,它们两个的目标基本是一致的——希望构建一个从隐变量ZZ生成目标数据XX的模型,但是实现上有所不同。更准确地讲,它们是假设了ZZ服从某些常见的分布(比如正态分布或均匀分布),然后希望训练一个模型X=g(Z)X=g(Z),这个模型能够将原来的概率分布映射到训练集的概率分布,也就是说,它们的目的都是进行分布之间的变换。
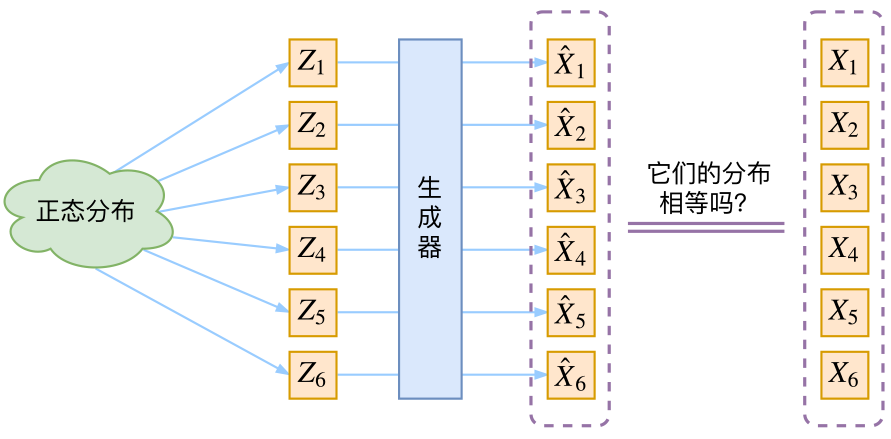
生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式
那现在假设ZZ服从标准的正态分布,那么我就可以从中采样得到若干个Z1,Z2,…,ZnZ1,Z2,…,Zn,然后对它做变换得到X^1=g(Z1),X^2=g(Z2),…,X^n=g(Zn)X^1=g(Z1),X^2=g(Z2),…,X^n=g(Zn),我们怎么判断这个通过gg构造出来的数据集,它的分布跟我们目标的数据集分布是不是一样的呢?有读者说不是有KL散度吗?当然不行,因为KL散度是根据两个概率分布的表达式来算它们的相似度的,然而目前我们并不知道它们的概率分布的表达式,我们只有一批从构造的分布采样而来的数据{X^1,X^2,…,X^n}{X^1,X^2,…,X^n},还有一批从真实的分布采样而来的数据{X1,X2,…,Xn}{X1,X2,…,Xn}(也就是我们希望生成的训练集)。我们只有样本本身,没有分布表达式,当然也就没有方法算KL散度。
虽然遇到困难,但还是要想办法解决的。GAN的思路很直接粗犷:既然没有合适的度量,那我干脆把这个度量也用神经网络训练出来吧。就这样,WGAN就诞生了,详细过程请参考《互怼的艺术:从零直达WGAN-GP》。而VAE则使用了一个精致迂回的技巧。
VAE慢谈 #
这一部分我们先回顾一般教程是怎么介绍VAE的,然后再探究有什么问题,接着就自然地发现了VAE真正的面目。
经典回顾 #
首先我们有一批数据样本{X1,…,Xn}{X1,…,Xn},其整体用XX来描述,我们本想根据{X1,…,Xn}{X1,…,Xn}得到XX的分布p(X)p(X),如果能得到的话,那我直接根据p(X)p(X)来采样,就可以得到所有可能的XX了(包括{X1,…,Xn}{X1,…,Xn}以外的),这是一个终极理想的生成模型了。当然,这个理想很难实现,于是我们将分布改一改
这里我们就不区分求和还是求积分了,意思对了就行。此时p(X|Z)p(X|Z)就描述了一个由ZZ来生成XX的模型,而我们假设ZZ服从标准正态分布,也就是p(Z)=N(0,I)p(Z)=N(0,I)。如果这个理想能实现,那么我们就可以先从标准正态分布中采样一个ZZ,然后根据ZZ来算一个XX,也是一个很棒的生成模型。接下来就是结合自编码器来实现重构,保证有效信息没有丢失,再加上一系列的推导,最后把模型实现。框架的示意图如下:
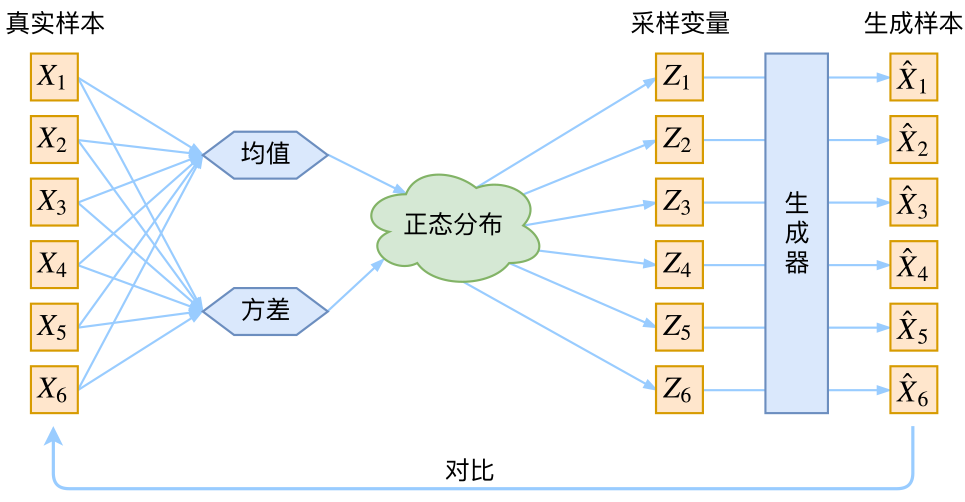
vae的传统理解
看出了什么问题了吗?如果像这个图的话,我们其实完全不清楚:究竟经过重新采样出来的ZkZk,是不是还对应着原来的XkXk,所以我们如果直接最小化D(X^k,Xk)2D(X^k,Xk)2(这里DD代表某种距离函数)是很不科学的,而事实上你看代码也会发现根本不是这样实现的。也就是说,很多教程说了一大通头头是道的话,然后写代码时却不是按照所写的文字来写,可是他们也不觉得这样会有矛盾~
VAE初现 #
其实,在整个VAE模型中,我们并没有去使用p(Z)p(Z)(隐变量空间的分布)是正态分布的假设,我们用的是假设p(Z|X)p(Z|X)(后验分布)是正态分布!!
具体来说,给定一个真实样本XkXk,我们假设存在一个专属于XkXk的分布p(Z|Xk)p(Z|Xk)(学名叫后验分布),并进一步假设这个分布是(独立的、多元的)正态分布。为什么要强调“专属”呢?因为我们后面要训练一个生成器X=g(Z)X=g(Z),希望能够把从分布p(Z|Xk)p(Z|Xk)采样出来的一个ZkZk还原为XkXk。如果假设p(Z)p(Z)是正态分布,然后从p(Z)p(Z)中采样一个ZZ,那么我们怎么知道这个ZZ对应于哪个真实的XX呢?现在p(Z|Xk)p(Z|Xk)专属于XkXk,我们有理由说从这个分布采样出来的ZZ应该要还原到XkXk中去。
事实上,在论文《Auto-Encoding Variational Bayes》的应用部分,也特别强调了这一点:
In this case, we can let the
variational approximate posterior be a multivariate Gaussian with a diagonal covariance structure:logqϕ(z|x(i))=logN(z;μ(i),σ2(i)I)(9)(9)logqϕ(z|x(i))=logN(z;μ(i),σ2(i)I)(注:这里是直接摘录原论文,本文所用的符号跟原论文不尽一致,望读者不会混淆。)
论文中的式(9)(9)是实现整个模型的关键,不知道为什么很多教程在介绍VAE时都没有把它凸显出来。尽管论文也提到p(Z)p(Z)是标准正态分布,然而那其实并不是本质重要的。
回到本文,这时候每一个XkXk都配上了一个专属的正态分布,才方便后面的生成器做还原。但这样有多少个XX就有多少个正态分布了。我们知道正态分布有两组参数:均值μμ和方差σ2σ2(多元的话,它们都是向量),那我怎么找出专属于XkXk的正态分布p(Z|Xk)p(Z|Xk)的均值和方差呢?好像并没有什么直接的思路。那好吧,那我就用神经网络来拟合出来吧!这就是神经网络时代的哲学:难算的我们都用神经网络来拟合,在WGAN那里我们已经体验过一次了,现在再次体验到了。
于是我们构建两个神经网络μk=f1(Xk),logσ2k=f2(Xk)μk=f1(Xk),logσk2=f2(Xk)来算它们了。我们选择拟合logσ2klogσk2而不是直接拟合σ2kσk2,是因为σ2kσk2总是非负的,需要加激活函数处理,而拟合logσ2klogσk2不需要加激活函数,因为它可正可负。到这里,我能知道专属于XkXk的均值和方差了,也就知道它的正态分布长什么样了,然后从这个专属分布中采样一个ZkZk出来,然后经过一个生成器得到X^k=g(Zk)X^k=g(Zk),现在我们可以放心地最小化D(X^k,Xk)2D(X^k,Xk)2,因为ZkZk是从专属XkXk的分布中采样出来的,这个生成器应该要把开始的XkXk还原回来。于是可以画出VAE的示意图
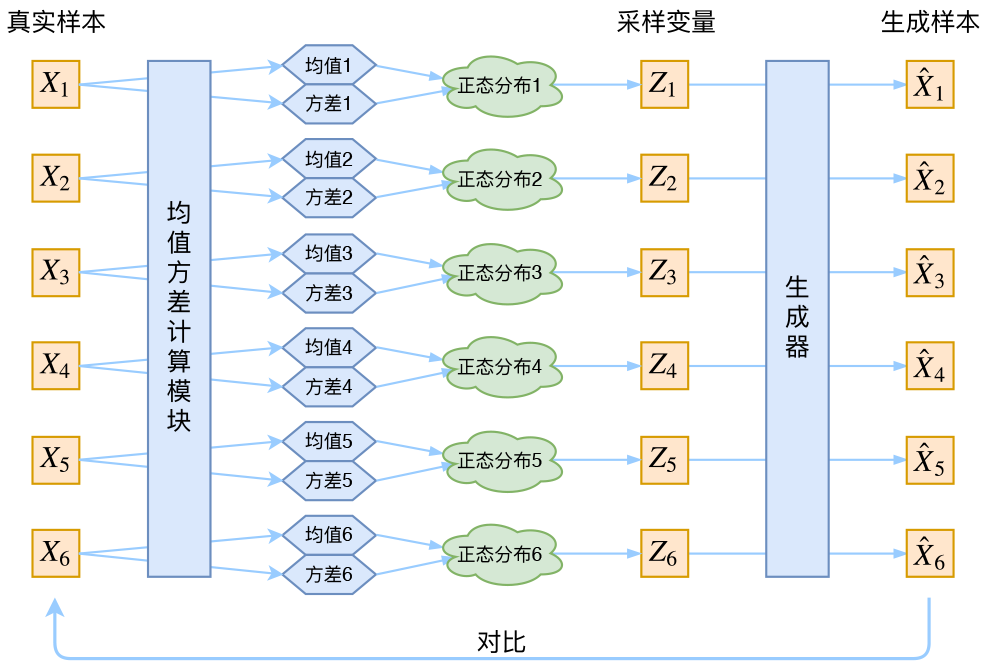
事实上,vae是为每个样本构造专属的正态分布,然后采样来重构
分布标准化 #
让我们来思考一下,根据上图的训练过程,最终会得到什么结果。
首先,我们希望重构XX,也就是最小化D(X^k,Xk)2D(X^k,Xk)2,但是这个重构过程受到噪声的影响,因为ZkZk是通过重新采样过的,不是直接由encoder算出来的。显然噪声会增加重构的难度,不过好在这个噪声强度(也就是方差)通过一个神经网络算出来的,所以最终模型为了重构得更好,肯定会想尽办法让方差为0。而方差为0的话,也就没有随机性了,所以不管怎么采样其实都只是得到确定的结果(也就是均值),只拟合一个当然比拟合多个要容易,而均值是通过另外一个神经网络算出来的。
说白了,模型会慢慢退化成普通的AutoEncoder,噪声不再起作用。
这样不就白费力气了吗?说好的生成模型呢?
别急别急,其实VAE还让所有的p(Z|X)p(Z|X)都向标准正态分布看齐,这样就防止了噪声为零,同时保证了模型具有生成能力。怎么理解“保证了生成能力”呢?如果所有的p(Z|X)p(Z|X)都很接近标准正态分布N(0,I)N(0,I),那么根据定义
这样我们就能达到我们的先验假设:p(Z)p(Z)是标准正态分布。然后我们就可以放心地从N(0,I)N(0,I)中采样来生成图像了。
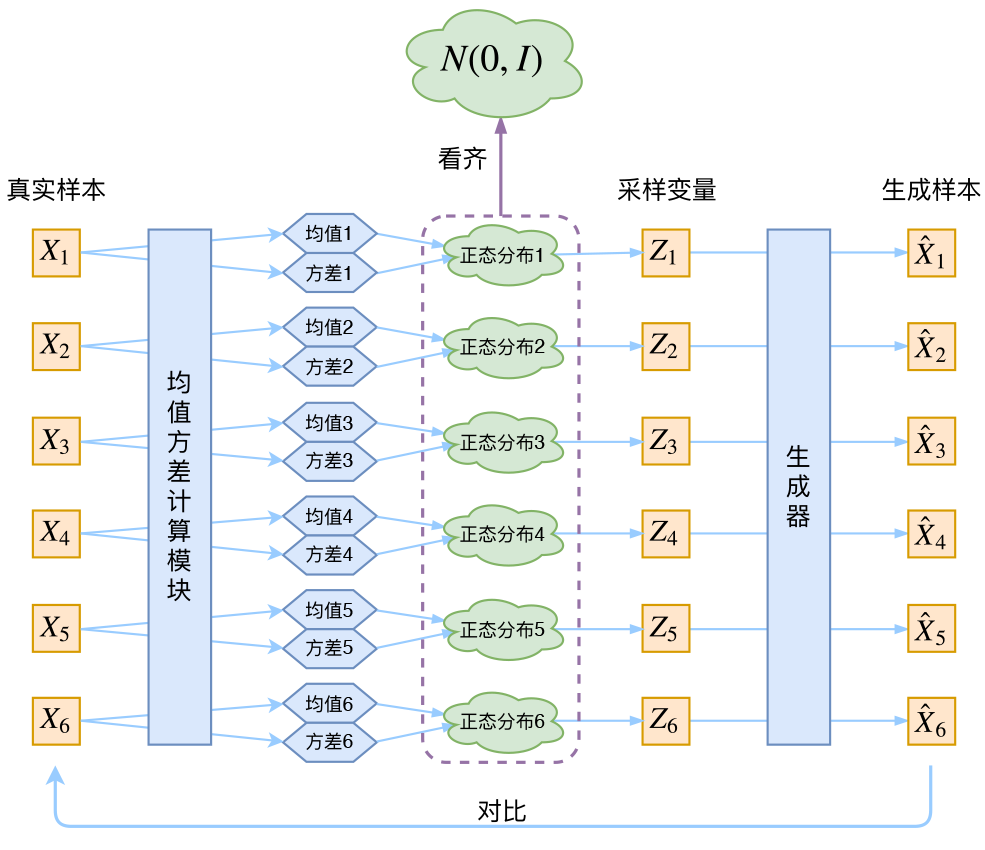
为了使模型具有生成能力,vae要求每个p(Z_X)都向正态分布看齐
那怎么让所有的p(Z|X)p(Z|X)都向N(0,I)N(0,I)看齐呢?如果没有外部知识的话,其实最直接的方法应该是在重构误差的基础上中加入额外的loss:
因为它们分别代表了均值μkμk和方差的对数logσ2klogσk2,达到N(0,I)N(0,I)就是希望二者尽量接近于0了。不过,这又会面临着这两个损失的比例要怎么选取的问题,选取得不好,生成的图像会比较模糊。所以,原论文直接算了一般(各分量独立的)正态分布与标准正态分布的KL散度KL(N(μ,σ2)∥∥N(0,I))KL(N(μ,σ2)‖N(0,I))作为这个额外的loss,计算结果为
这里的dd是隐变量ZZ的维度,而μ(i)μ(i)和σ2(i)σ(i)2分别代表一般正态分布的均值向量和方差向量的第ii个分量。直接用这个式子做补充loss,就不用考虑均值损失和方差损失的相对比例问题了。显然,这个loss也可以分两部分理解:
推导
由于我们考虑的是各分量独立的多元正态分布,因此只需要推导一元正态分布的情形即可,根据定义我们可以写出===KL(N(μ,σ2)∥∥N(0,1))∫12πσ2−−−−√e−(x−μ)2/2σ2(loge−(x−μ)2/2σ2/2πσ2−−−−√e−x2/2/2π−−√)dx∫12πσ2−−−−√e−(x−μ)2/2σ2log{1σ2−−√exp{12[x2−(x−μ)2/σ2]}}dx12∫12πσ2−−−−√e−(x−μ)2/2σ2