神经网络激活函数softmax,sigmoid,tanh,relu总结
一、总结
一句话总结:
常见激活函数:softmax、sigmoid、tanh、relu
二、【神经网络】激活函数softmax,sigmoid,tanh,relu总结
转自或参考:【神经网络】激活函数softmax,sigmoid,tanh,relu总结
https://blog.csdn.net/weixin_42057852/article/details/84644348
激活函数使用原因
- 如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
- 如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
- 比如,在单层感知机中,分类的结果大于某个值为一类,小于某个值为一类,这样的话就会使得输出结果在这个点发生阶跃,logistic函数解决了阶跃函数的突然阶跃问题,使得输出的为0-1的概率,使得结果变得更平滑,他是一个单调上升的函数,具有良好的连续性,不存在不连续点。
1. softmax函数
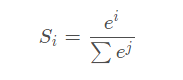
- 映射区间[0,1]
- 主要用于:离散化概率分布
| 激活函数 | Softmax | Sigmoid |
|---|---|---|
| 本质 | 离散概率分布 | 非线性映射 |
| 任务 | 多分类 | 二分类 |
| 定义域 | 某个一维向量 | 单个数值 |
| 值域 | [0, 1] | (0, 1) |
| 结果之和 | 一定为1 | 为某个正数 |
2. sigmoid函数

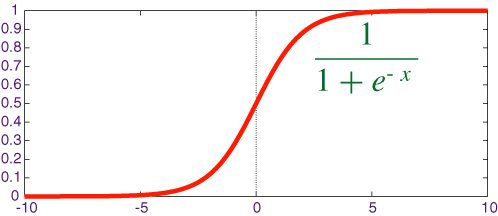
- 映射区间(0, 1)
- 也称logistic函数
在神经网络中的反向传播
- sigmoid函数求导
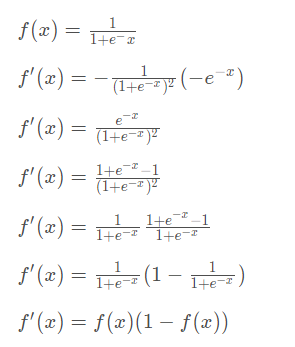
sigmoid就是极端情况(类别数为2)下的softmax
3. tanh函数
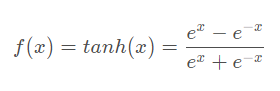
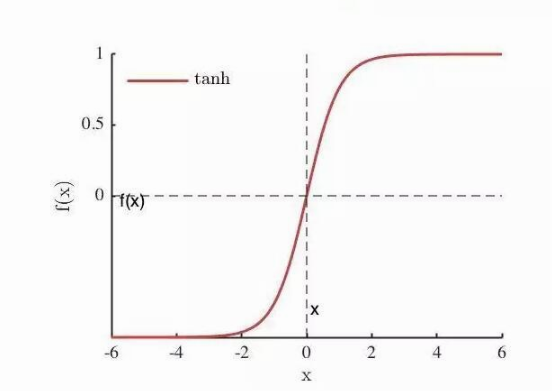
- 映射区间 (-1,1)
- 也称双切正切函数
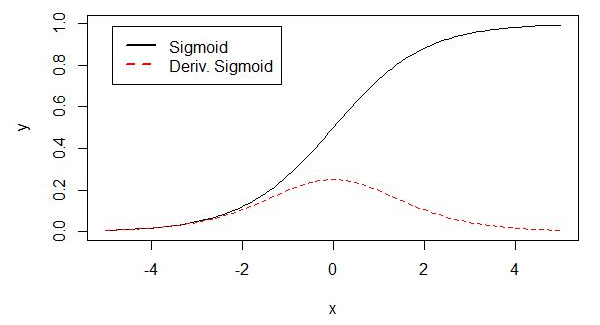
sigmoid函数和tanh函数都存在一个问题:当神经网络的层数增多的时候,由于在进行反向传播的时候,链式求导,多项相乘,函数进入饱和区(导数接近于零的地方)就会逐层传递,这种现象被称为梯度消失。
比如:sigmoid函数与其导数的函数如下,可以看出梯度消失的问题
解决办法:可以采用批标准化(batch normalization)来解决
4. ReLU函数
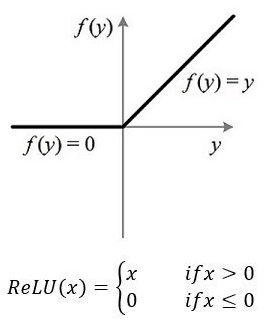
映射区间:[0,+∞)
RELU函数的优点:
- 相关大脑方面的研究表明生物神经元的信息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%-4%的神经元处于活跃状态。使用线性修正以及正则化(regularization)可以对机器神经网络中神经元的活跃度(即输出为正值)进行调试;相比之下,逻辑函数在输入为0时达到1/2 , 即已经是半饱和的稳定状态,不够符合实际生物学对模拟神经网络的期望。不过需要指出的是,一般情况下,在一个使用修正线性单元(即线性整流)的神经网络中大概有50%的神经元处于激活态;
- 更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题;
- 简化计算过程:没有了其他复杂激活函数中诸如指数函数的影响;同时活跃度的分散性使得神经网络整体计算成本下降。
RELU总结
- 虽然ReLU函数大于零的部分和小于零的部分分别都是线性函数,但是整体并不是线性函数,所以仍然可以做为激活函数,ReLU函数其实是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被成为单侧抑制。
- 在训练数据的时候,由于对于不同的任务,可能某些神经元的输出影响就比较大,有些则小,甚至有些则无,类似于人的大脑,左脑和右脑分别管理逻辑能力与想象力,当使用右脑的时候,就抑制左脑,当使用左脑的时候,抑制右脑,RELU函数正好可以实现小于0的数直接受到抑制,这就使得神经网络的激活更接近于生物学上的处理过程,给神经网络增加了生命。
总结
- 因为线性模型的表达能力不够,引入激活函数是为了添加非线性因素;
- 然后发展出了很多的激活函数适用于各种模型的训练;
- RELU函数的引入给神经网络增加了生物学特性,可以称为灵魂激活函数。