numpy产生随机数
一、总结
一句话总结:
*、np.random.rand(2,3) #产生2行三列均匀分布随机数组
*、有正有负:np.random.randn(3,3) #三行三列正态分布随机数据
*、np.random.randint(1,100,[5,5]) #(1,100)以内的5行5列随机整数
*、只有正数:np.random.random(10) #(0,1)以内10个随机浮点数
1、numpy.random模块分为四个部分,对应四种功能?
1、简单随机数: 产生简单的随机数据,可以是任何维度
2、排列:将所给对象随机排列
3、分布:产生指定分布的数据,如高斯分布等
4、生成器:种随机数种子,根据同一种子产生的随机数是相同的
二、numpy产生随机数
转自或参考:numpy产生随机数
https://blog.csdn.net/pengge0433/article/details/79470459
在数据分析中,数据的获取是第一步,numpy.random 模块提供了非常全的自动产生数据API,是学习数据分析的第一步。
总体来说,numpy.random模块分为四个部分,对应四种功能:
1. 简单随机数: 产生简单的随机数据,可以是任何维度
2. 排列:将所给对象随机排列
3. 分布:产生指定分布的数据,如高斯分布等
4. 生成器:种随机数种子,根据同一种子产生的随机数是相同的
以下是详细内容以及代码实例:(以下代码默认已导入numpy:import numpy as np )
1. 生成器
电脑产生随机数需要明白以下几点:
(1)随机数是由随机种子根据一定的计算方法计算出来的数值。所以,只要计算方法一定,随机种子一定,那么产生的随机数就不会变。
(2)只要用户不设置随机种子,那么在默认情况下随机种子来自系统时钟(即定时/计数器的值)
(3)随机数产生的算法与系统有关,Windows和Linux是不同的,也就是说,即便是随机种子一样,不同系统产生的随机数也不一样。
numpy.random 设置种子的方法有:
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| RandomState | 定义种子类 | RandomState是一个种子类,提供了各种种子方法,最常用seed |
| seed([seed]) | 定义全局种子 | 参数为整数或者矩阵 |
代码示例:
np.random.seed(1234) #设置随机种子为1234
2. 简单随机数
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| rand(d0, d1, …, dn) | 产生均匀分布的随机数 | dn为第n维数据的维度 |
| randn(d0, d1, …, dn) | 产生标准正态分布随机数 | dn为第n维数据的维度 |
| randint(low[, high, size, dtype]) | 产生随机整数 | low:最小值;high:最大值;size:数据个数 |
| random_sample([size]) | 在[0,1)内产生随机数 | size:随机数的shape,可以为元祖或者列表,[2,3]表示2维随机数,维度为(2,3) |
| random([size]) | 同random_sample([size]) | 同random_sample([size]) |
| ranf([size]) | 同random_sample([size]) | 同random_sample([size]) |
| sample([size])) | 同random_sample([size]) | 同random_sample([size]) |
| choice(a[, size, replace, p]) | 从a中随机选择指定数据 | a:1维数组 size:返回数据形状 |
| bytes(length) | 返回随机位 | length:位的长度 |
代码示例
>>> import numpy as np
>>> print(np.random.rand(2,3)) #产生2行三列均匀分布随机数组
[[ 0.00764233 0.3830022 0.55875737]
[ 0.33188605 0.63720051 0.69983149]]
>>> print(np.random.randn(3,3)) #三行三列正态分布随机数据
[[-2.25581993 0.28401035 -0.39071727]
[ 0.3554526 -0.79093564 -0.31146916]
[ 1.02469652 0.12776135 2.28273697]]
>>> print(np.random.randint(1,100,[5,5])) #(1,100)以内的5行5列随机整数
[[ 3 8 17 93 18]
[49 88 24 74 90]
[31 49 36 20 33]
[ 6 10 91 82 18]
[26 8 76 90 55]]
>>> print(np.random.random(10)) #(0,1)以内10个随机浮点数
[ 0.68046894 0.99589507 0.55610842 0.28758456 0.7304742 0.5175079
0.06014449 0.58060165 0.03519808 0.77347185]
3. 分布
numpy.random模块提供了产生各种分布随机数的API:
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| beta(a, b[, size]) | 贝塔分布样本,在 [0, 1]内。 | |
| binomial(n, p[, size]) | 二项分布的样本。 | |
| chisquare(df[, size]) | 卡方分布样本。 | |
| dirichlet(alpha[, size]) | 狄利克雷分布样本。 | |
| exponential([scale, size]) | 指数分布 | |
| f(dfnum, dfden[, size]) | F分布样本。 | |
| gamma(shape[, scale, size]) | 伽马分布 | |
| geometric(p[, size]) | 几何分布 | |
| gumbel([loc, scale, size]) | 耿贝尔分布。 | |
| hypergeometric(ngood, nbad, nsample[, size]) | 超几何分布样本。 | |
| laplace([loc, scale, size]) | 拉普拉斯或双指数分布样本 | |
| logistic([loc, scale, size]) | Logistic分布样本 | |
| lognormal([mean, sigma, size]) | 对数正态分布 | |
| logseries(p[, size]) | 对数级数分布。 | |
| multinomial(n, pvals[, size]) | 多项分布 | |
| multivariate_normal(mean, cov[, size]) | 多元正态分布。 | |
| negative_binomial(n, p[, size]) | 负二项分布 | |
| noncentral_chisquare(df, nonc[, size]) | 非中心卡方分布 | |
| noncentral_f(dfnum, dfden, nonc[, size]) | 非中心F分布 | |
| normal([loc, scale, size]) | 正态(高斯)分布 | |
| pareto(a[, size]) | 帕累托(Lomax)分布 | |
| poisson([lam, size]) | 泊松分布 | |
| power(a[, size]) | Draws samples in [0, 1] from a power distribution with positive exponent a - 1. | |
| rayleigh([scale, size]) | Rayleigh 分布 | |
| standard_cauchy([size]) | 标准柯西分布 | |
| standard_exponential([size]) | 标准的指数分布 | |
| standard_gamma(shape[, size]) | 标准伽马分布 | |
| standard_normal([size]) | 标准正态分布 (mean=0, stdev=1). | |
| standard_t(df[, size]) | Standard Student’s t distribution with df degrees of freedom. | |
| triangular(left, mode, right[, size]) | 三角形分布 | |
| uniform([low, high, size]) | 均匀分布 | |
| vonmises(mu, kappa[, size]) | von Mises分布 | |
| wald(mean, scale[, size]) | 瓦尔德(逆高斯)分布 | |
| weibull(a[, size]) | Weibull 分布 | |
| zipf(a[, size]) | 齐普夫分布 |
代码示例
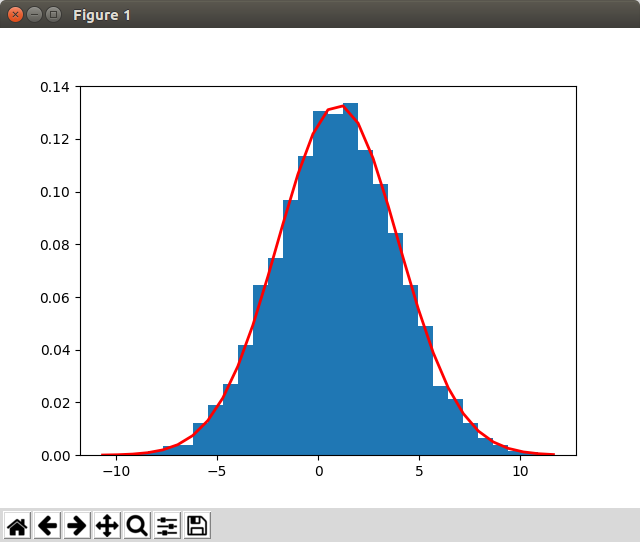
>>> import numpy as np>>> import matplotlib.pyplot as plt
>>> mu=1 #数学期望:1
>>> sigma=3 #标准差:3
>>> num=10000 #个数:10000
>>> rand_data = np.random.normal(mu, sigma, num)
>>> count, bins, ignored = plt.hist(rand_data, 30, normed=True)
>>> plt.plot(bins, 1/(sigma * np.sqrt(2 * np.pi)) *np.exp( - (bins - mu)**2 / (2 * sigma**2)), linewidth=2, color='r')
[<matplotlib.lines.Line2D object at 0x7f29dc3d9128>]
>>> plt.show()
4. 排列
| 函数名称 | 函数功能 | 参数说明 |
|---|---|---|
| shuffle(x) | 打乱对象x(多维矩阵按照第一维打乱) | 矩阵或者列表 |
| permutation(x) | 打乱并返回该对象(多维矩阵按照第一维打乱) | 整数或者矩阵 |
代码示例
>>> import numpy as np>>> rand_data=np.random.randint(1,10,(3,4))
>>> print(rand_data)
[[4 4 6 9]
[3 4 2 2]
[3 9 3 3]]
>>> np.random.shuffle(rand_data)
>>> print(rand_data)
[[4 4 6 9]
[3 9 3 3]
[3 4 2 2]]