反向传播算法
一、总结
一句话总结:
【误差反向传播】:反向传播(英语:Backpropagation,缩写为BP)是“误差反向传播”的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见方法。
1、“正向传播”求损失,“反向传播”回传误差?
“正向传播”求损失,“反向传播”回传误差。同时,神经网络每层的每个神经元都可以根据误差信号修正每层的权重,
二、反向传播算法
转自或参考:反向传播算法
https://www.cnblogs.com/nevermoes/p/bp.html
在传统机器学习算法中我们会使用梯度下降算法来做权重更新:
即使用输出值构造一个损失函数,然后以权重为自变量,执行梯度下降的更新规则使得损失函数达到最小。
那么其实bp算法(之后反向传播算法都简称为bp算法,个人习惯)做了一件差不多的事情,但是又有那么些区别。这是由于神经网络的拓扑结构决定的。
我们可以对比一下神经网络和传统的机器学习算法的正向计算:
神经网络:
感知机:
所以其实从拓扑结构上来讲,感知机甚至可以看做是单层的神经网络。在这种单层的神经网络结构中,对权重求导是简单的,直接求偏导即可。但是在多层复合函数的神经网络结构中,每个节点都需要被求导,复合函数求导最容易想到的方法就是链式法则,然而链式法则会存在一些问题。
我们先使用一个简单的例子来说明链式法则,或者说正向求导为什么不好,然后引出反向求导来说明反向传播算法。
简单的例子
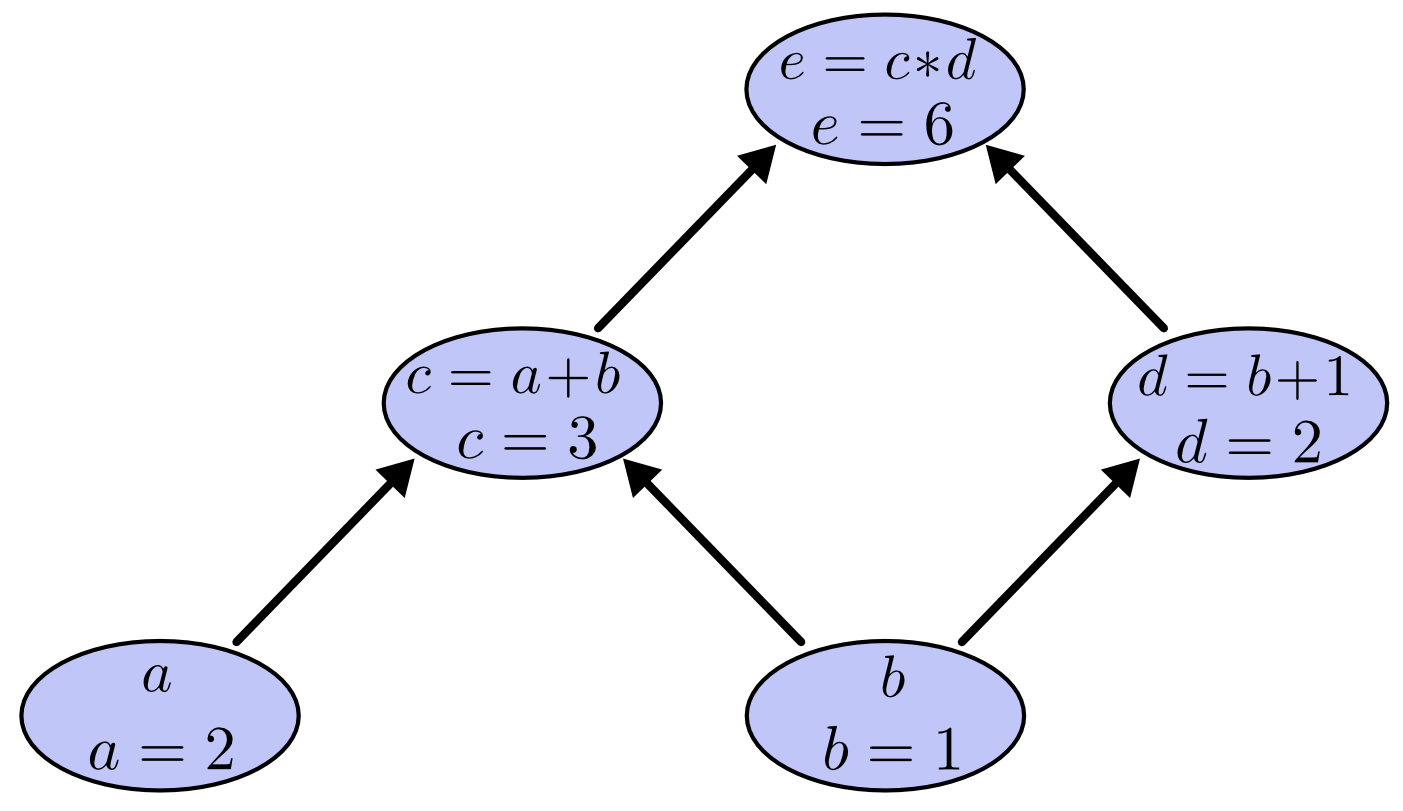
对于一个比较复杂的表达式:(e=(a+b)*(b+1)),我们可以引入两个中间变量:(c=a+b)、(d=b+1)且令(a=2)、(b=1)。
按照链式求导法则以(e)对(b)求偏导的话:
(e)对(a)求偏导:
计算图理解
我们还可以使用计算图来理解这个过程。
原式用计算图来表示就是:

前向计算:
并对每个节点单独计算偏导值:
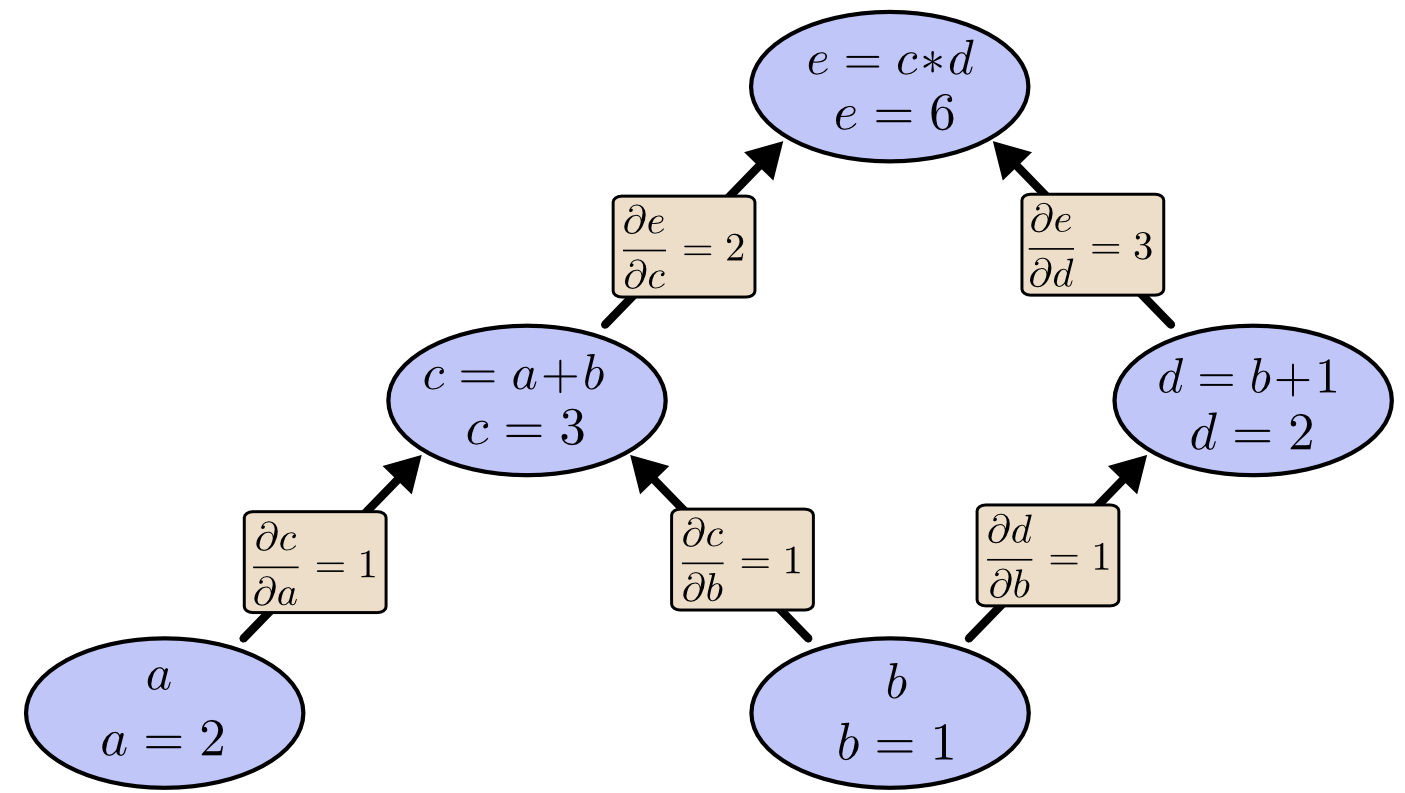
于是我们如何用这个计算图来理解复合函数求偏导的过程呢。
对于(frac { partial e } { partial a }),计算图的路径是a-c-e,相同路径节点上的值直接相乘就是:(frac { partial e } { partial a}=1cdot2)。
对于(frac { partial e } { partial b }),唯一的不同就是,这个偏导值经过两个路径,而不同路径即b-d-e和b-c-e之间的值需要相加:(frac { partial e } { partial b }=1 cdot 2 + 1 cdot 3)。
缺点
正向的链式求导法则或者在计算图上遍历路径的方法也能求复合函数的偏导数的值。那为什么要使用bp算法呢?
神经网络往往是一个非常大的网络,所以计算成本是非常高的,而上面讲解那种方法存在一个对计算成本非常致命的缺陷。我们在用(e)分别对(a)和(b)求导的过程中c-e路径被使用了两次,或者说(frac { partial e } { partial c })被计算了两次。
也就是说:正向的链式求导会存在计算冗余。
反向传播
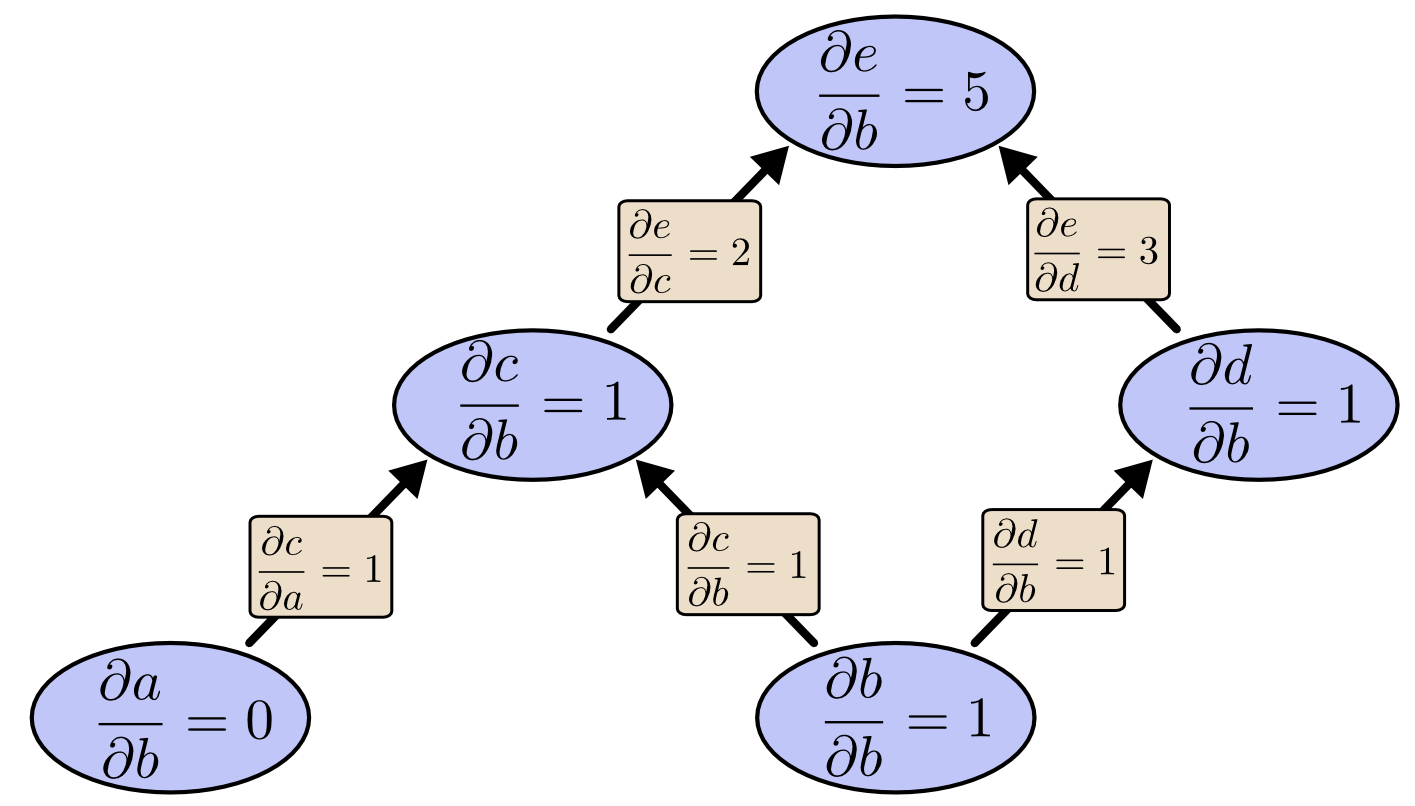
以图为例,那么其实正向的求导就是自底向上地求导,本图显示了各个节点对于b的偏导值,所以遍历了所有节点只能求得对应单个输入的偏导值。
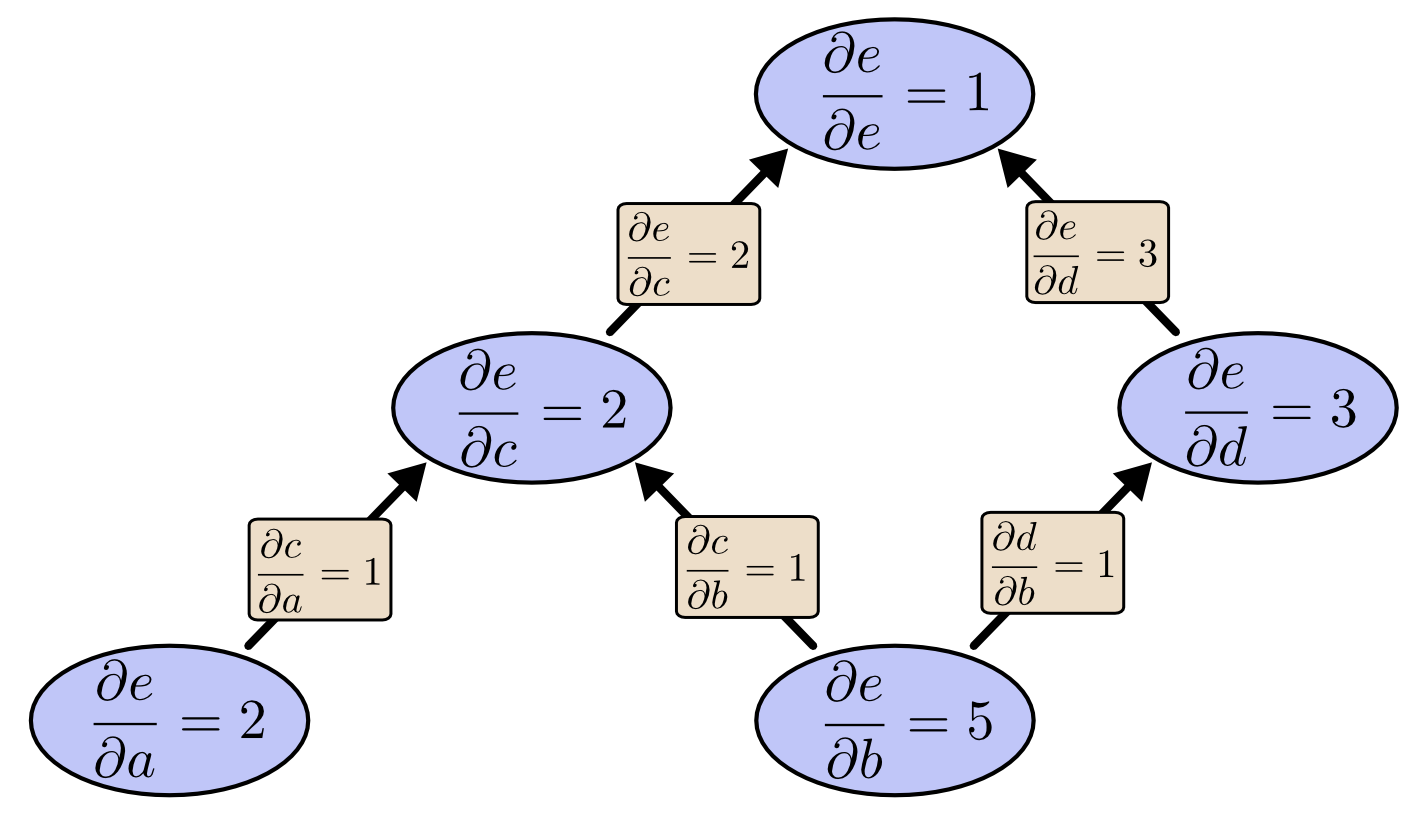
反向求导就是自顶向下地求导,这里看出遍历完所以节点之后,对应所有输入的偏导值都可以求出来。
但是,世界上并没有免费的午餐,反向传播虽然在时间复杂度上比正向传播要快,但是反向传播在计算之前必须要先前向计算一遍,其实也就是反向传播比起正向传播在算法复杂度上利用了空间复杂度换取了时间复杂度。
算法复杂度分析
复杂度分析参考引用2。
神经网络中的反向传播

我们以本图为例具体说明一下神经网络中bp算法的计算过程。
上一节我省略使用sigmoid函数的理由,这里说明一下,因为sigmod导数的性质非常好,sigmod的导数可以用函数自身来表示,即:
我们以均方误差作为损失函数,训练样本为((vec{x},vec{t})):
要使损失函数最小:
对输出层节点(i)求误差:
那么带入节点,比如节点8:
对于隐层节点有:
随便带入一个节点4:
以上就是误差项的求法,将误差项带入梯度下降就得到了权重的更新式子:
这里的(x_ji)就是节点(i)传递给节点(j)的值。
那么比如权重(w_{84})的更新方式就是: