php爬虫最最最最简单教程
一、总结
一句话总结:用的爬虫框架,却是用的自己的例子(因为网站结构的变化,作者的例子不一定好用)
爬虫框架 自己例子
1、发现自己的运行效果和作者的不一样怎么办?
耐下性子快速阅读全部文档
作者的文档很有可能是之前写的,不一样正常,但是看文档的时候尽量全部文档都看一下,否则只看前面几个因为各种原因(比如例子年久失修)例子可能运行不出来
二、爬虫使用流程
1、下载爬虫框架
owner888/phpspider: 《我用爬虫一天时间“偷了”知乎一百万用户,只为证明PHP是世界上最好的语言 》所使用的程序
https://github.com/owner888/phpspider

2700+Star,用用不亏
我下载的发布版2.1.6
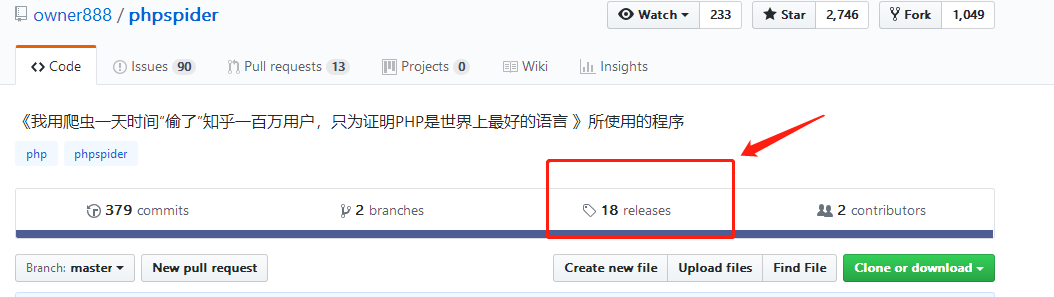
点开
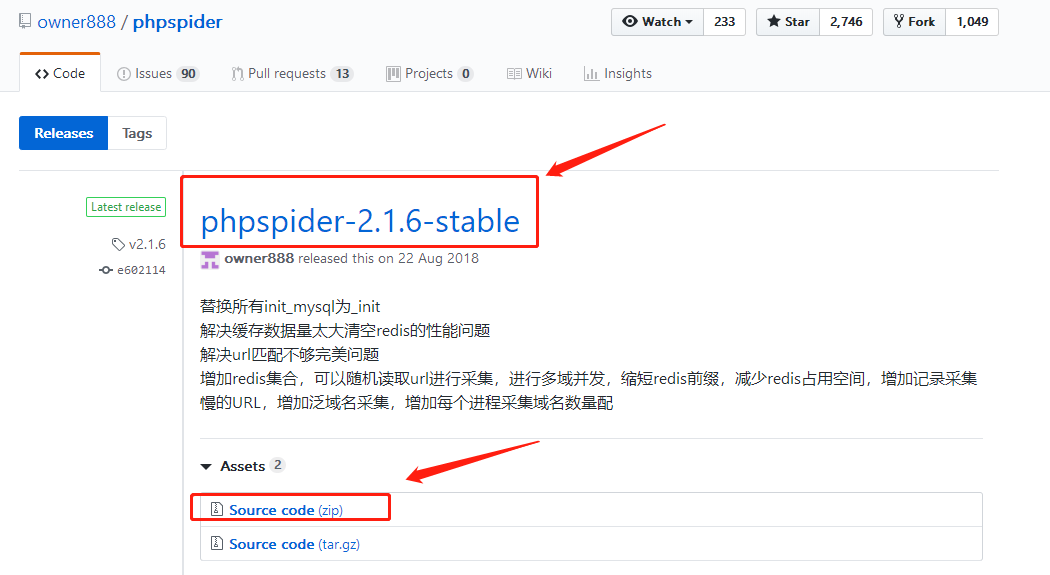
下载好的
然后解压
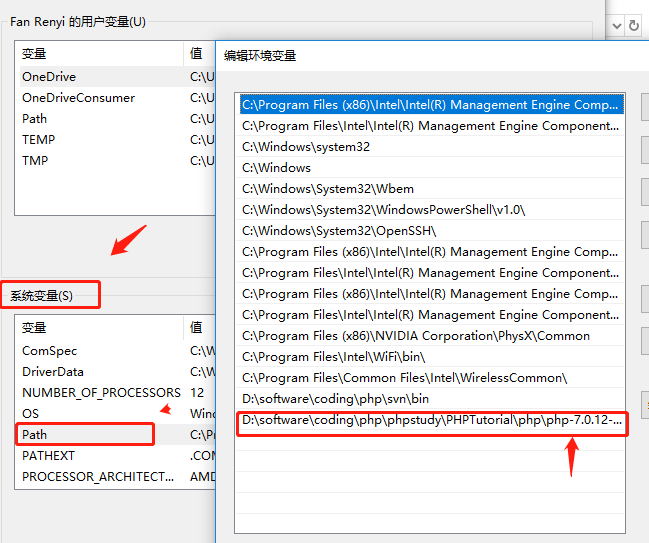
2、配置php环境(非必须,为了方便)
在电脑的系统环境变量配置里面,在path变量里面添加了一条php,可以发现我的php版本是7.0.12
不会配置电脑系统变量的自己百度去,和配置java的jdk类似
3、用我的例子(例子的功能是获取博客园里面文章的标题)
在demo文件夹下新建一个名为firstDemo_2.php的php文件
如下
文件里面的代码如下:例子的功能是获取博客园里面文章的标题
1 <?php 2 // composer下载方式 3 // 先使用composer命令下载: 4 // composer require owner888/phpspider 5 // 引入加载器 6 //require './vendor/autoload.php'; 7 8 // GitHub下载方式 9 require_once __DIR__ . '/../autoloader.php'; 10 use phpspidercorephpspider; 11 12 /* Do NOT delete this comment */ 13 /* 不要删除这段注释 */ 14 15 $configs = array( 16 'name' => '博客园', 17 'log_show' => false, 18 'domains' => array( 19 'www.cnblogs.com' 20 ), 21 'scan_urls' => array( 22 'https://www.cnblogs.com/Renyi-Fan/p/10570492.html' 23 ), 24 'fields' => array( 25 // 抽取内容页的文章标题 26 array( 27 'name' => "article_title", 28 'selector' => "//*[@id="cb_post_title_url"]", 29 'required' => true 30 ) 31 ), 32 'export' => array( 33 'type' => 'sql', 34 'file' => './data/cnblog_fry.sql', 35 'table' => '数据表', 36 ), 37 38 ); 39 40 $spider = new phpspider($configs); 41 $spider->start();
具体代码什么意思看官方文档:地址如下:
概述 · phpspider开发文档
https://doc.phpspider.org/
4、具体运行例子过程
在刚刚下载好的phpspider-2.1.6demo的文件夹下打开命令行
运行:php -f firstDemo_2.php

运行效果:
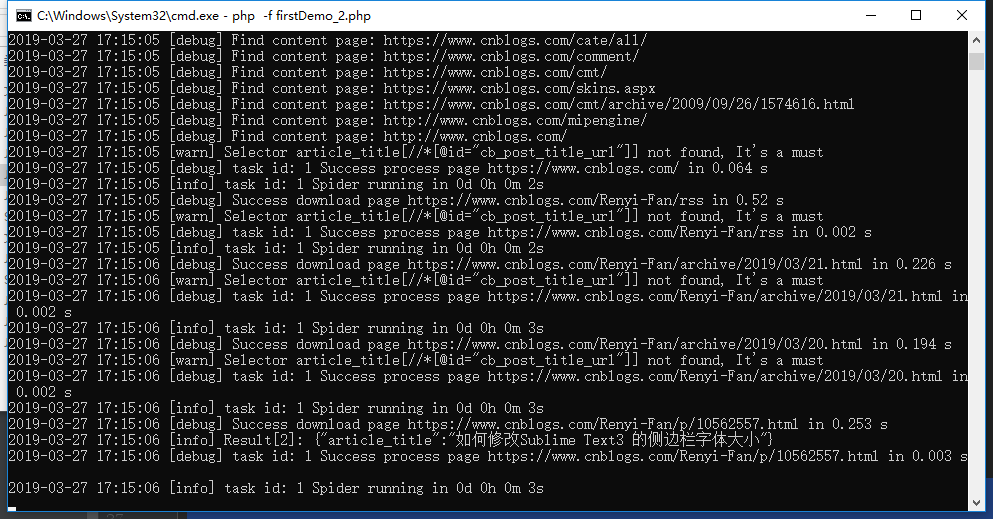
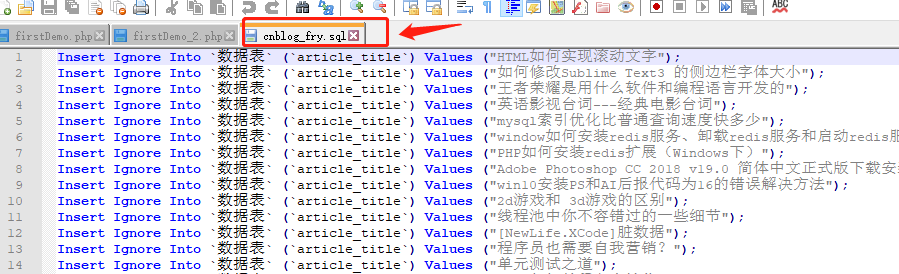
5、运行的结果
在如下路径下打开cnblog_fry.sql即可查看爬虫效果
效果如下: