一、网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
网络爬虫应用一般分为两个步骤:
1. 通过网络链接获取网页内容;
2. 对获得的网页内容进行处理;
这两个步骤分别使用不同的函数库:requests 和 beautifulsoup4 。
采用pip指令安装 requests 库:打开命令行窗口 → 输入cmd → 输入 pip install requests
( besutifulsoup4 库的安装也是类似的,此处不再赘述)
• Requests 库
1. Requests 库的7个方法
|
方法 |
说明 |
|
requests.request() |
构造一个请求,支撑以下各方法的基础方法 |
|
requests.get() |
获取HTML网页的主要方法,对应于HTTP的GET |
|
requests.head() |
获取HTML网页头信息的方法,对应于HTTP的HEAD |
|
requests.post() |
向HTML网页提交POST请求的方法,对应于HTTP的POST |
|
requests.put() |
向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
|
requests.patch() |
向HTML网页提交局部修改请求,对应于HTTP的PATCH |
|
requests.delete() |
向HTML页面提交删除请求,对应于HTTP的DELETE |
2. Response对象的属性
|
属性 |
说明 |
|
r.status_code |
HTTP请求的返回状态,200表示连接成功,404表示失败 |
|
r.text |
HTTP响应内容的字符串形式,即,url对应的页面内容 |
|
r.encoding |
从HTTP header中猜测的响应内容编码方式 |
|
r. apparent_encoding |
从内容中分析出的响应内容编码方式(备选编码方式) |
|
r.content |
HTTP响应内容的二进制形式 |
3. 理解 Requests 库的异常
|
属性 |
说明 |
|
r.status_code |
HTTP请求的返回状态,200表示连接成功,404表示失败 |
|
r.text |
HTTP响应内容的字符串形式,即,url对应的页面内容 |
|
r.encoding |
从HTTP header中猜测的响应内容编码方式 |
|
r. apparent_encoding |
从内容中分析出的响应内容编码方式(备选编码方式) |
|
r.content |
HTTP响应内容的二进制形式 |
|
r.raise_for_status() |
如果不是200,产生异常 requests.HTTPError |
二、用 requests 库访问百度主页
函数说明:
| 函数名称 | 函数功能 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示连接失败 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.content | HTTP响应内容的二进制形式 |
| len() | 计算文本长度 |
代码如下:
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Mon May 20 10:15:03 2019 4 5 @author: Regan_White_Lin 12 6 """ 7 8 import requests 9 def getHTMLText(url): 10 try: 11 r=requests.get(url,timeout=30) 12 r.raise_for_status() 13 r.encoding='utf-8' 14 return r 15 except: 16 return "" 17 18 for i in range(20): 19 url="http://www.baidu.com" 20 print("第",i+1,"次访问") 21 r=getHTMLText(url) 22 print("网络状态码:",r.status_code) 23 print("网页文本内容:",r.text) 24 print("text属性长度:",len(r.text)) 25 print("content属性长度:",len(r.content))
访问结果:

根据要求,循环访问了百度主页20次,由于输出结果过长,此处便不一一展示了。
可以发现的一点是多次访问同一网页,其 text, content 属性长度并未发生变化。
需要注意的一点是,当你频繁地运行此程序时,所访问的页面可能有反爬措施,导致输出结果异常,如:访问页面非我们输入的页面,访问时长过长等。
三、用 Beautifulsoup4 库提取网页源代码中的有效信息
下面是本次操作所访问的网页源代码:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <hl>我的第一个标题</hl> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> <tr> </table> </html>
注意:对于中文网页需要使用 <meta charset="utf-8"> 声明编码,否则会出现乱码。有些浏览器(如 360 浏览器)会设置 GBK 为默认编码,则你需要设置为 <meta charset="gbk">。
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Mon May 20 10:15:03 2019 4 5 @author: Regan_White_Lin 12 6 """ 7 8 from bs4 import BeautifulSoup 9 10 html='''<!DOCTYPE html> 11 <html> 12 <head> 13 <meta charset="utf-8"> 14 <title>菜鸟教程(runoob.com)</title> 15 </head> 16 <body> 17 <hl>我的第一个标题</hl> 18 <p id="first">我的第一个段落。</p> 19 </body> 20 <table border="1"> 21 <tr> 22 <td>row 1, cell 1</td> 23 <td>row 1, cell 2</td> 24 </tr> 25 <tr> 26 <td>row 2, cell 1</td> 27 <td>row 2, cell 2</td> 28 <tr> 29 </table> 30 </html>''' 31 32 soup= BeautifulSoup(html) 33 print("网页head标签内容: ",soup.head," number:12 ") 34 print("网页body标签内容: ",soup.body," ") 35 print("网页id为first的标签: ",soup.p," ") 36 print("网页中的中文字符: ",soup.title.string) 37 print(soup.hl.string) 38 print(soup.p.string," ")
输出效果如下:
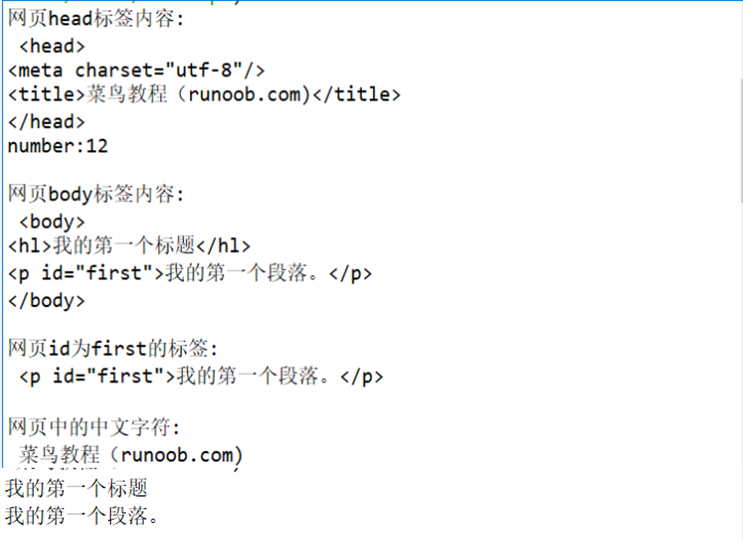
四、爬中国大学排名
以下数据均来自http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html
利用爬虫爬取2015年全国最好大学排名,代码如下:
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Sun May 19 08:50:42 2019 4 5 @author: Regan_White_Lin 12 6 """ 7 8 #e23.1CrawUnivRanking.py 9 import requests 10 from bs4 import BeautifulSoup 11 import pandas 12 allUniv = [] 13 def getHTMLText(url): 14 try: 15 r = requests.get(url, timeout=30) 16 r.raise_for_status() 17 r.encoding = 'utf-8' 18 return r.text 19 except: 20 return "" 21 def fillUnivList(soup): 22 data = soup.find_all('tr') 23 for tr in data: 24 ltd = tr.find_all('td') 25 if len(ltd)==0: 26 continue 27 singleUniv = [] 28 for td in ltd: 29 singleUniv.append(td.string) 30 allUniv.append(singleUniv) 31 def printUnivList(num): 32 print("{1:^2}{2:{0}^10}{3:{0}^7}{4:{0}^4}{5:{0}^10}{6:{0}^10}{7:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","人才培养得分","科学研究得分","社会服务得分")) 33 for i in range(num): 34 u=allUniv[i] 35 print("{1:^4}{2:{0}^11}{3:{0}^5}{4:{0}^8.1f}{5:{0}^8.1f}{6:{0}^16.1f}{7:{0}^8.1f}".format(chr(12288),u[0],u[1],u[2],eval(u[3]),eval(u[4]),eval(u[5]),eval(u[6]))) 36 37 def saveAsCsv(filename, tabel_list): 38 FormData = pandas.DataFrame(tabel_list) 39 FormData.columns = ["排名","学校名称","省市","总分","人才培养得分","科学研究得分","社会服务得分"] 40 FormData.to_csv(filename,encoding="gbk") 41 42 if __name__ == "__main__": 43 url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2015_0.html" 44 html = getHTMLText(url) 45 soup = BeautifulSoup(html, features="html.parser") 46 data = fillUnivList(soup) 47 printUnivList(10) # 输出前10行数据 48 saveAsCsv("2015中国大学排名爬虫.csv", allUniv)
输出结果如下:

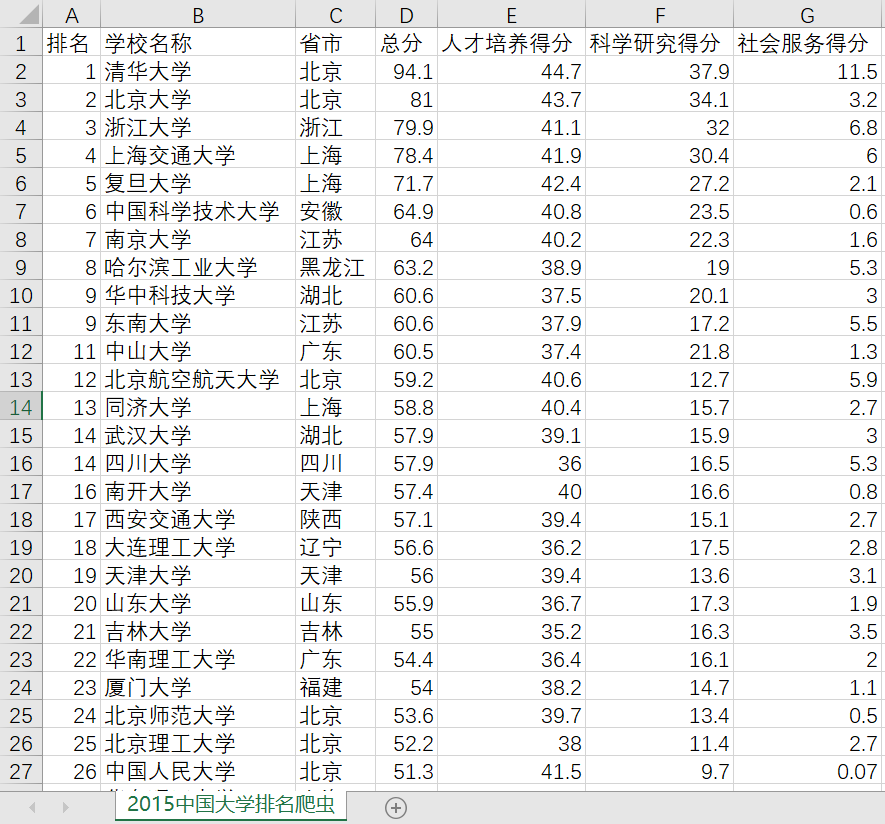
数据较长,这里就不一一展示了