一、准备
在制作词云之前我们需要自行安装三个库,它们分别是:jieba, wordcloud, matplotlib
安装方法基本一致,下面我以安装wordcloud的过程为例。
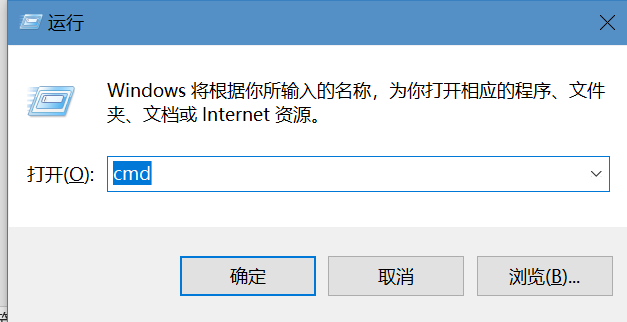
第一步,按下Win+R打开命令输入框,并输入cmd,点击确定
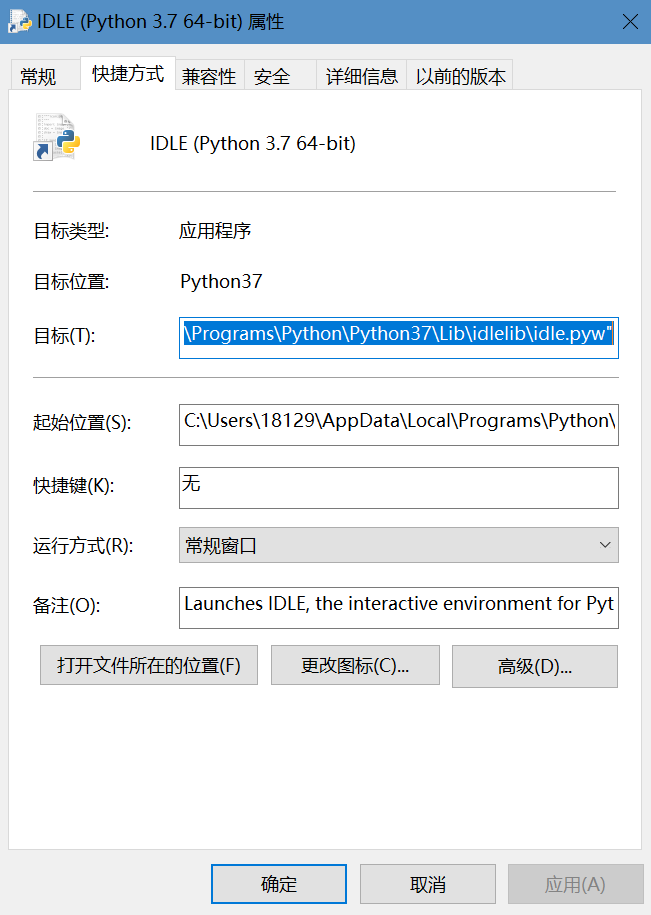
第二步,找到IDLE文件(即平时打代码的程序),右击,点击属性,得到如下界面,再点击打开文件所在的位置
打开Scripts文件,可以看到pip文件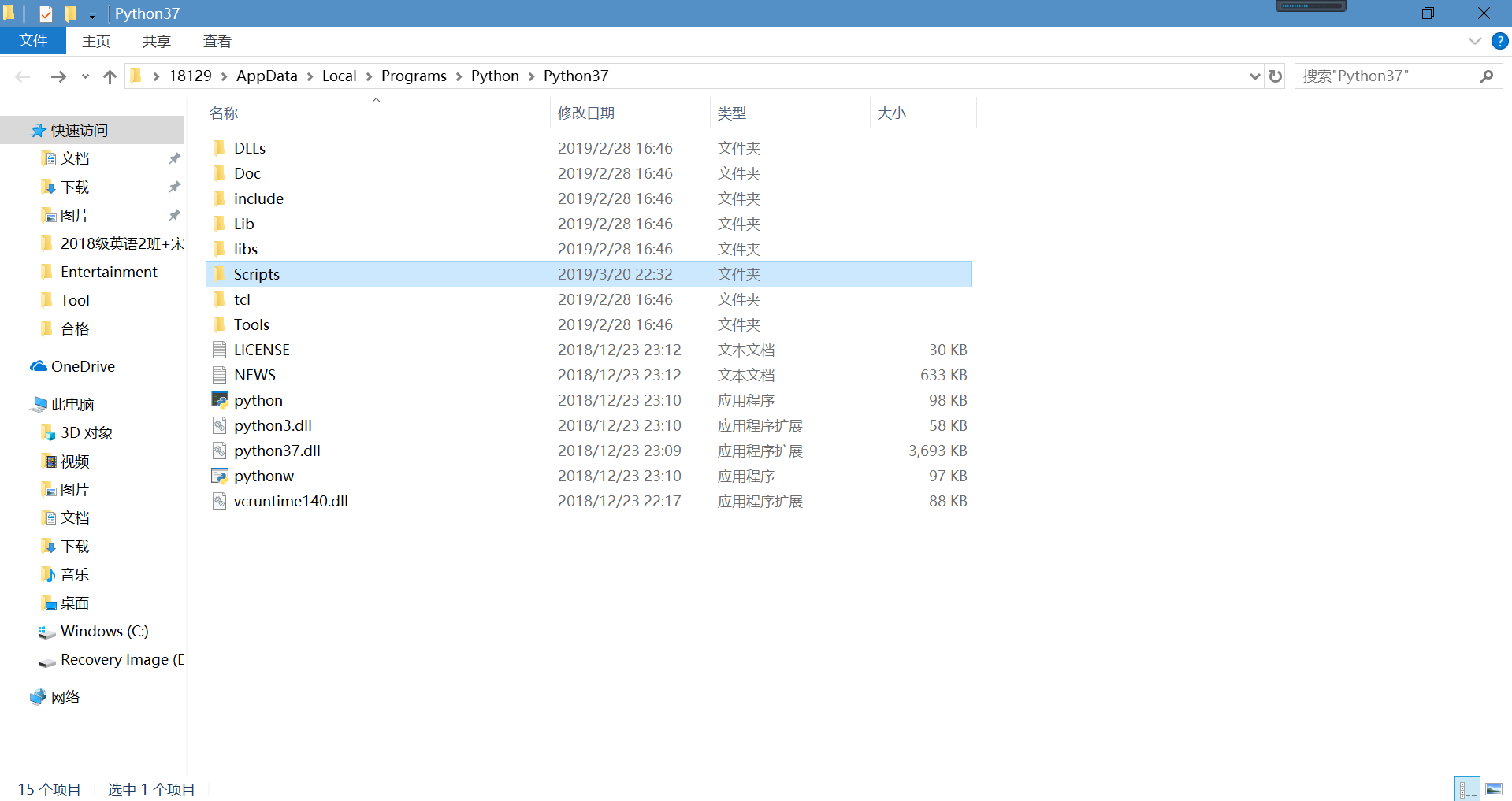

将pip文件直接拖至刚才输入cmd打开的界面
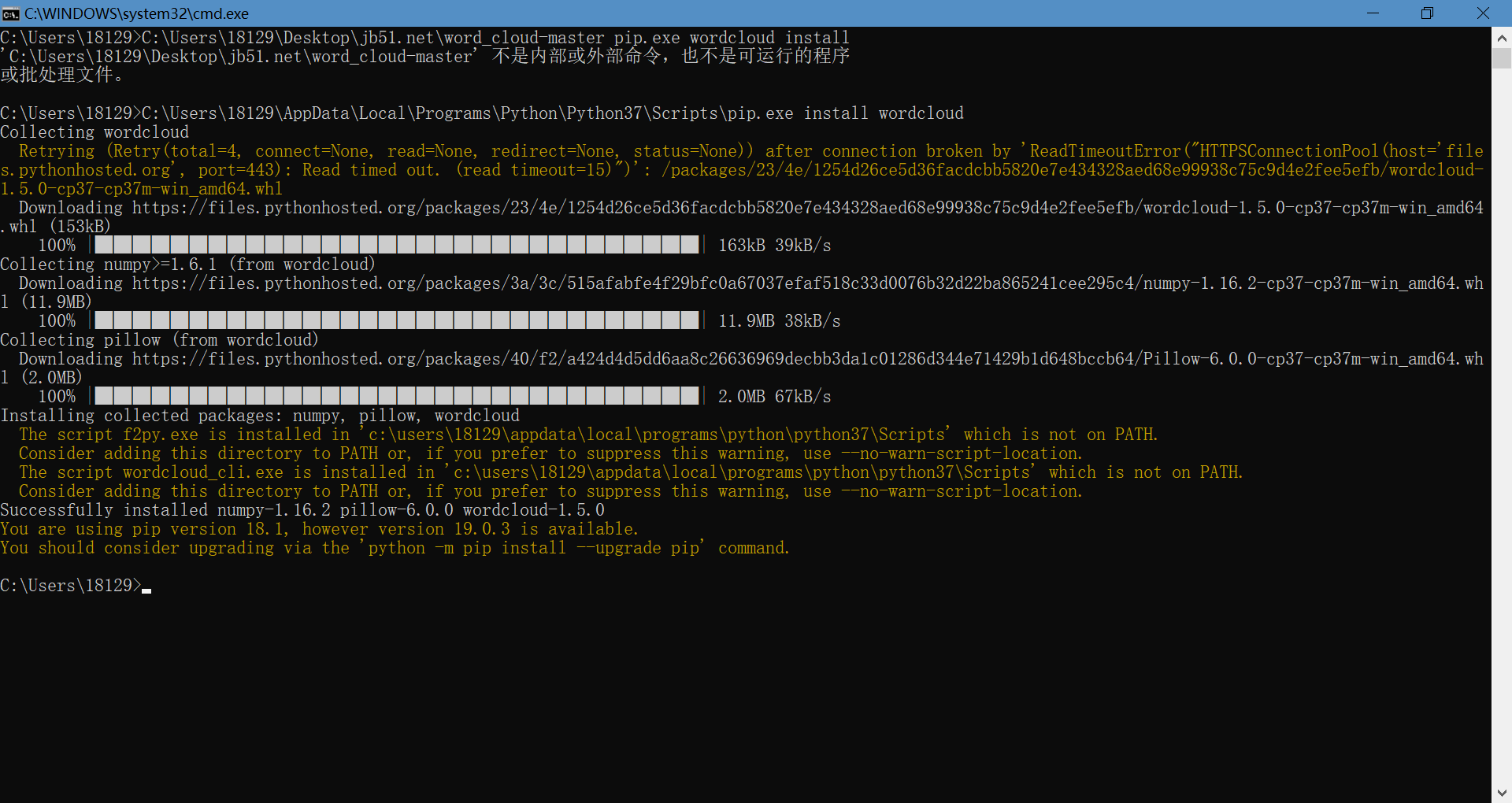
在pip.exe后方输入install wordcloud(注意以空格为间隔),然后点击回车,这样我们就安装好了wordcloud库函数
剩余两个jieba和matplotlib都是同样的操作,只需把上文中的wordcloud替换即可,这里就不再操作了
二、对文本中出现的文字频率进行统计
首先我们需要找到一篇文章,将其弄成txt格式的文件,这里我在网上下载了小说《盗墓笔记》
下载完成后需将txt文件与编写程序的文件放置在同一文件夹中
然后就是编写代码了,代码如下
1 import jieba 2 txt = open("盗墓笔记.txt", "r", encoding='utf-8').read() 3 words = jieba.lcut(txt) 4 counts = {} 5 for word in words: 6 if len(word) == 1: 7 continue 8 else: 9 counts[word] = counts.get(word,0) + 1 10 items = list(counts.items()) 11 items.sort(key=lambda x:x[1], reverse=True) 12 for i in range(10): 13 word, count = items[i] 14 print ("{0:<10}{1:>5}".format(word, count))
运行程序,为节省时间,我只让程序输出频次最高的前十个词,效果如下
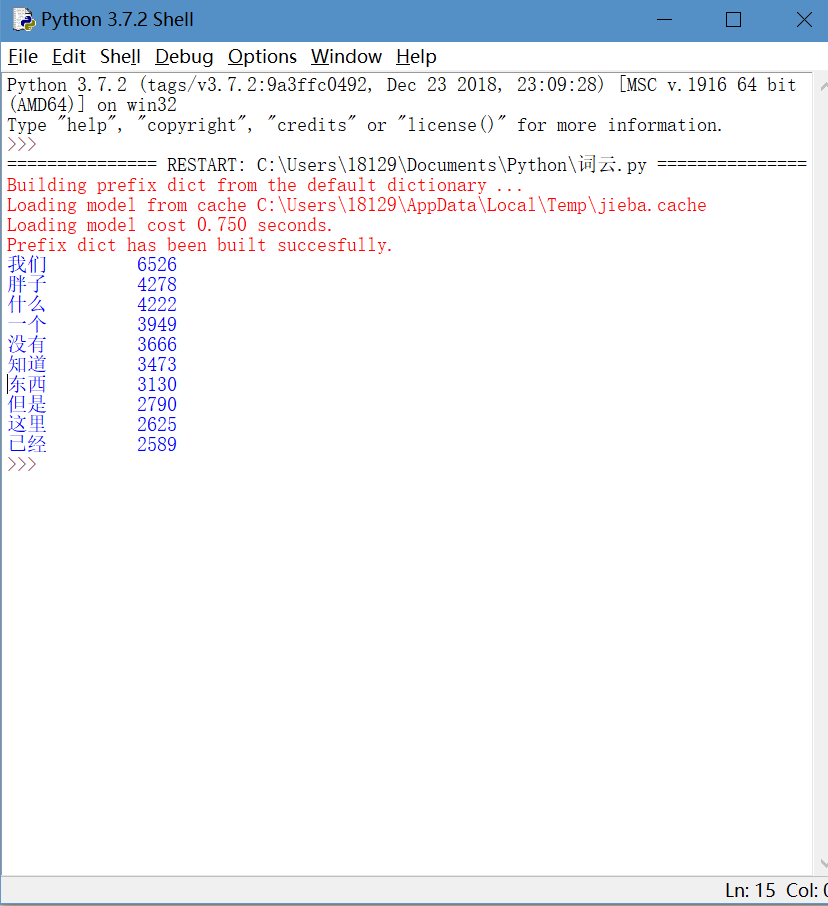
这样,统计词语频次的程序就搞定了
三、使小说中出现的词语以词云输出
这一步跟上一步统计频次一样的,我们都得将python程序与小说放置在同一文件夹中
然后就输入以下代码
1 from wordcloud import WordCloud 2 import matplotlib.pyplot as plt #绘制图像的模块 3 import jieba #jieba分词 4 5 path_txt='盗墓笔记.txt' 6 f = open(path_txt,'r',encoding='UTF-8').read() 7 8 # 结巴分词,生成字符串,wordcloud无法直接生成正确的中文词云 9 cut_text = " ".join(jieba.cut(f)) 10 11 wordcloud = WordCloud( 12 #设置字体,不然会出现口字乱码,文字的路径是电脑的字体一般路径,可以换成别的 13 font_path="C:/Windows/Fonts/simfang.ttf", 14 #设置了背景,宽高 15 background_color="white",width=1920,height=1080).generate(cut_text) 16 17 plt.imshow(wordcloud, interpolation="bilinear") 18 plt.axis("off") 19 plt.show()
运行后,会出现如下的一个窗口
点击左下方最右边的形如磁盘的键,将该图片下载下来

词云也完成了