Hadoop家族成员概述
一、Hadoop简介
1.1 什么是Hadoop?
Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,用户可以在不了解分布式底层细节的情况下,开发分布式应用程序,充分利用集群的威力高速运算和存储。
1.2 Hadoop的特点
高扩容能力:能可靠地存储和处理千兆字节(PB)的数据。
成本低:可以通过普通机器组成的服务器来分发以及处理数据,这些服务器群总计可达数千个节点,同时Hadoop是开源的。
高效率:通过分发数据,Hadoop可以在数据所在的节点上并行地处理它们,这使得处理非常的快速。
高可靠性:Hadoop能自动地维护数据的多份复制,并且在任务失败后能自动地重新部署计算任务。
1.3 谁在用Hadoop?
Yahoo!、IBM、Facebook、Amazon、百度、腾讯、新浪、搜狐、淘宝等。
1.4 Hadoop家族成员
下图为Hadoop家族成员图,整个Hadoop项目由以下几个子项目构成。
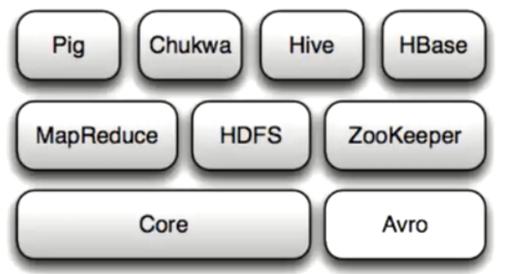
图1:Hadoop家族成员图

·Hadoop Common
Hadoop体系最底层的一个模块,为Hadoop各子项目提供各种工具,如:配置文件和日志操作等。
·Avro :
Avro是Doug cutting主持的RPC项目,有点类似Google的protobuf和Facebook的thrift。avro用来做以后hadoop的RPC,使hadoop的RPC模块通信速度更快、数据结构更紧凑。
二、分布式文件系统(HDFS)
2.1 HDFS简介
HDFS是一种用于Hadoop应用程序的主存储系统,也是一个高容错性系统,适合部署在廉价机上,同时,HDFS能提高吞吐量的数据访问,非常适合大规模数据集上的应用。
HDFS为了做到可靠性创建了多份数据块的复制,并将它们放置在服务器群的计算节点中,MapReduce就可以在它们所造的几点上处理这些数据了。
HDFS默认的最基本的存储单位是64M的数据块。
2.2 HDFS能做什么?
HDFS适合做什么?
·存储并管理PB级数据。
·处理非结构化数据。
·注重数据处理的吞吐量。
·应用模式为:write-once-read-many存取模式。
HDFS不适合做?
·存储小文件(不建议使用)。
·大量的随机读(不建议使用)。
·需要对文件的修改(不支持)。
2.3 HDFS组件的主要功能
HDFS主要由NameNode和DataNode组成, NameNode是HDFS中负责namespace管理的节点,NameNode保存了当前集群中所存储的的所有的文件的元数据信息,NameNode同时与集群中其它的节点通信,以保持元数据与系统中的文件的一致性,同时也和 client通信,以响应client对文件的需要。DataNode是文件系统的工作节点,他们根据客户端或者是DataNode的调度存储和检索数据,并且定期向DataNode发送他们所存储的块(block)的列表。
没有NameNode,HDFS就不能工作。
|
NameNode |
DataNode |
|
·存储元数据 |
·存储文件内容 |
|
·元数据保存在内存中 |
·文件内容保存在磁盘 |
|
·保存文件block和datanode之间的映射关系 |
·维护了block到datanode本地文件的映射关系 |
表1:HDFS的主要功能
基本概念:
1) 数据块(block)
·HDFS默认的最基本的存储单位是64M的数据块。
·和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。
·不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块的存储空间。
2) 元数据节点(NameNode)
元数据节点用来管理文件系统的命名空间。
3) 数据节点(DataNode)
数据节点是文件系统中挣扎存储数据的地方。
三、MapReduce
MapReduce是一种处理海量数据的并行编程模型和计算框架,主要用于大数据集的并行计算。
3.1 MapReduce基础
1) MapReduce处理数据集的过程,如下图:
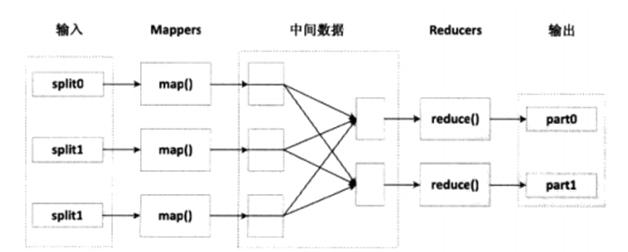
图2:MapReduce处理数据集的过程
Map阶段:
MapReduce框架将任务的输入分割成固定大小的片段(splites),随后敬爱那个每个splite进一步分解成一批键值对<K1,V1>。 Hadoop为每个split创建一个Map任务用于执行用户自定义的Map函数,并将对应split中的<K1,V1>对作为输入,得到计算的中间结果<K2,V2>,接着将中间结果按照K2进行排序,并key值相同的value放在一起形成<K2,list(V2)>元组。最后在根据key值的范围将这些远足进行分组,随影不同的Reduce任务。
Reduce阶段:
Reducer把从不同Mapper接收来的数据整合在一起并进行排序,然后调用用户自定义的reduce函数,对输入<K2,list(V2)>对进行处理,得到键值对<K3,V3>并输出到HDFS上。job.setNumReduceTask()方法设置reduce数。
3.2 MapReduce的集群行为
·任务调度与执行:有一个JobTracker和多个TaskTracker两类节点控制完成。
·本地计算:split通常应小于或等于HDFS数据块的大小,从而保证split不会跨越两台计算机存储,便于本地计算。
·shuffle过程:将Mapper的输出结果按照key值分成R份(R是设定的Reduce个数),划分时使用哈希函数,保证某一范围内的key由某个Reduce来处理。
·合并Mapper输出:在Shuffle之前先的结果进行合并(Combine过程)即将中间结果相同key值的多组<key,value>对合并成一对。可以减少中间结果数量,从而减少数据传输过程中的网络流量。
·读取中间结果:Mapper的输出结果被直接写到本地磁盘而非HDFS。
·任务管道:有时R个Reduce会产生R个结果,会将这R个结果作为另一个计算任务的输入开始。
3.2 Map/Reduce的个数
·Mappers的数目直接由splits来决定。
·Reduces的数目略小于reduce slots的总数。
所有的Reduces可以并行执行,减少排队时间。
对于未执行的reducer的slots,可以在其他reducer发生故障时立即分配给新创建的reducer。
·Reduces的个数要小于Mappers的个数。
四、Chukwa
4.1 Chukwa简介
Chukwa是由Yahoo贡献,基于Hadoop的大集群监控系统,可以用他来分析和收集系统中的数据(日志)。Chukwa运行HDFS中存储数据 的收集器和MapReduce框架之上,并继承了Hadoop的可扩展性 和鲁棒性, Chukwa使用MapReduce来生成报告,他还包括一个用于监测和分析结果显示的web-portal工具,通过web-portal工具使这个收 集数据的更佳具有灵活性。
4.2 Chukwa由那几个组件组成?
Chukwa是Yahoo开发的Hadoop之上的数据采集/分析框架,主要用于日志采集/分析。该框架提供了采集数据的Agent,由Agent采集数 据通过HTTP发送数据给Cluster的Collector,collector把数据 sink进Hadoop,然后通过定期运行Map reducer来分析数据,将结果呈现给用户。
Chukwa 有以下4个主要的组成部分:
·Agent:收集各服务器的数据
·Collectors:接收agent的数据;并写进存储
·MapReduce jobs :归档数据
· HICC :就是 Hadoop Infrastructure Care Center的四个英文单词的缩写,简单来说是个Web工程用于ChukWa的内容展示。
五、Pig
Pig是SQL-like语言,是在MapReduce上构建的一种高级查询语言,把一些运算编译进MapReduce模型的Map和Reduce中,并且用户可以定义自己的功能。
六、Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通 过类SQL语句块快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库。
七、HBase
7.1 HBase简介
HBase是Hadoop的数据库。能对大型数据提供随即、实时的读写访问。HBase的目标是存储并处理大型的数据。HBase是一个开源的、分布式的、多版本的、面向列的存储模型。它存储的是松散型数据。
HBase是Google BigTable的开源实现。Google BigTable利用 GFS 作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google 运行 MapReduce来处理BigTable中的海量数 据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google BigTable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
7.2 HBase的特点
·高可靠性
·高效性
·面向列
·可伸缩
·可在廉价PC Server上搭建大规模的结构化存储集群
7.3 HBase的使用场景
·成熟的数据分析主题,查询模式已经确立并且不轻易改变。
·传统的关系型数据库已经无法承受负荷,高速插入,大量读取。
·适合海量的,但同时也是简单的操作(例如key-value)。
八、Zookeeper
Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易 出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户