参考文章:https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html
String类型的常量池的主要使用方法有两种:
- 直接使用双引号声明出来的
String对象会直接存储在常量池中。 - 如果不是用双引号声明的
String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中
String s = new String("abc")这个语句创建了几个对象
创建了2个对象,第一个对象是”abc”字符串存储在常量池中,第二个对象在JAVA Heap中的 String 对象。
看两段代码:
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
打印结果是
- jdk6 下
false false - jdk7 下
false true
然后将s3.intern();语句下调一行,放到String s4 = "11";后面。将s.intern(); 放到String s2 = "1";后面。
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
jdk6的解释
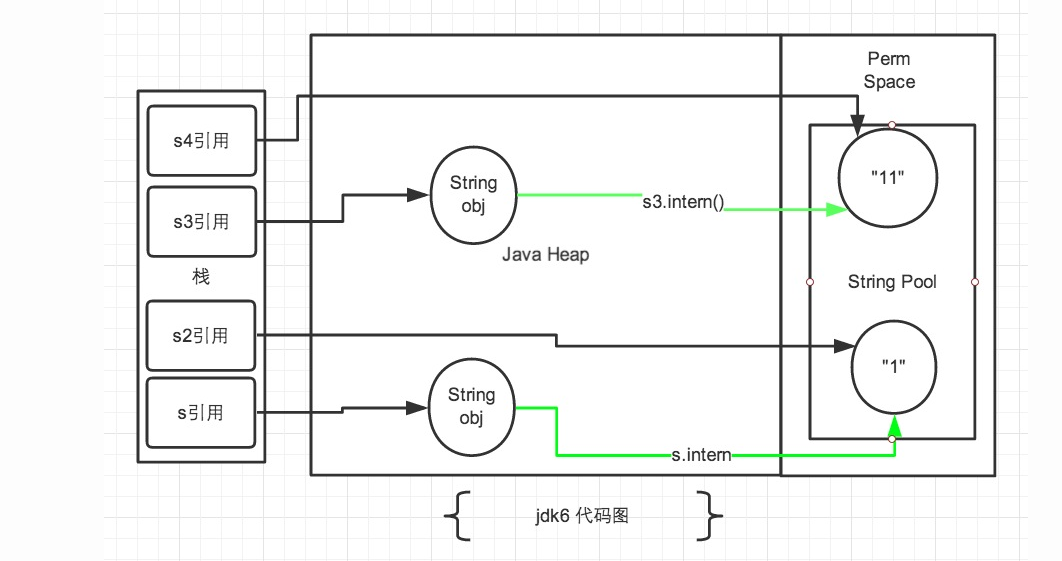
注:图中绿色线条代表 string 对象的内容指向。 黑色线条代表地址指向。
jdk6中的常量池是放在 Perm 区中的,Perm 区和正常的 JAVA Heap 区域是完全分开的。上面说过如果是使用引号声明的字符串都是会直接在字符串常量池中生成,而 new 出来的 String 对象是放在 JAVA Heap 区域。所以拿一个 JAVA Heap 区域的对象地址和字符串常量池的对象地址进行比较肯定是不相同的,即使调用String.intern方法也是没有任何关系的。
jdk7的解释
在 Jdk6 以及以前的版本中,字符串的常量池是放在堆的 Perm 区的;在 jdk7 的版本中,字符串常量池已经从 Perm 区移到正常的 Java Heap 区域了; jdk8 已经直接取消了 Perm 区域,而新建立了一个元区域。
字符串常量池移动到 JAVA Heap 区域后。针对上述第一段代码:
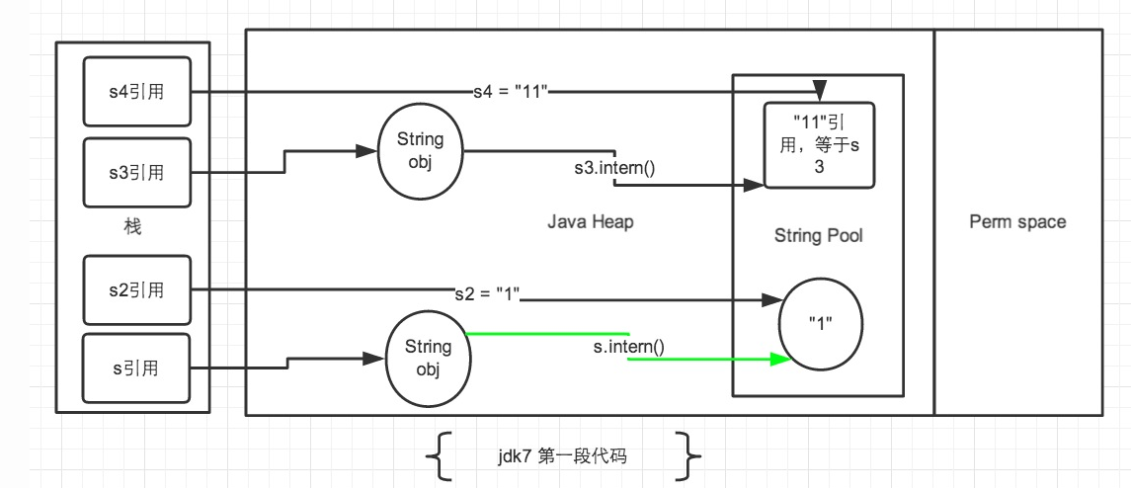
- 先看看 s 和 s2 对象。
String s = new String("1");第一句代码,生成了2个对象。常量池中的“1” 和 JAVA Heap 中的字符串对象。s.intern();这一句是 s 对象去常量池中寻找后发现 “1” 已经在常量池里了,所以直接返回在常量池中的引用了。 - 接下来
String s2 = "1";这句代码是生成一个 s2的引用指向常量池中的“1”对象。 结果就是 s 和 s2 的引用地址明显不同。 - 再看看 s3和s4字符串。
String s3 = new String("1") + new String("1");,这句代码中现在生成了2最终个对象,是字符串常量池中的“1” 和 JAVA Heap 中的 s3引用指向的对象。此时s3引用对象内容是”11”,但此时常量池中是没有 “11”对象的。 - 接下来
s3.intern();是将 s3中的“11”字符串放入 String 常量池中,因为此时常量池中不存在“11”字符串。常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用指向 s3 引用的对象。 也就是说引用地址是相同的。 - 最后
String s4 = "11";这句代码中”11”是显示声明的,因此会直接去常量池中创建,创建的时候发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。所以 s4 引用就指向和 s3 一样了。因此最后的比较s3 == s4是 true。
针对第二段代码:
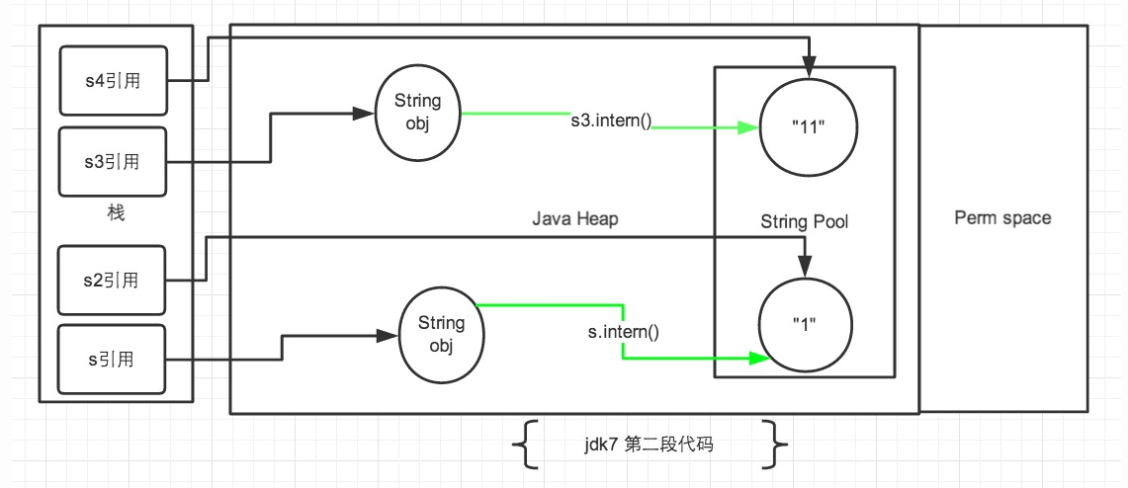
- 来看第二段代码,从上边第二幅图中观察。第一段代码和第二段代码的改变就是
s3.intern();的顺序是放在String s4 = "11";后了。这样,首先执行String s4 = "11";声明 s4 的时候常量池中是不存在“11”对象的,执行完毕后,“11“对象是 s4 声明产生的新对象。然后再执行s3.intern();时,常量池中“11”对象已经存在了,因此 s3 和 s4 的引用是不同的。 - 第二段代码中的 s 和 s2 代码中,
s.intern();,这一句往后放也不会有什么影响了,因为对象池中在执行第一句代码String s = new String("1");的时候已经生成“1”对象了。下边的s2声明都是直接从常量池中取地址引用的。 s 和 s2 的引用地址是不会相等的。
总结:
jdk7 版本对 intern 操作和常量池都做了一定的修改。主要包括2点:
- 将String常量池 从 Perm 区移动到了 Java Heap区
String#intern方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。