Es相比关系型数据库在数据检索方面有着极大的优势,在处理亿级数据时,可谓是毫秒级响应,我们在使用Es时不仅仅进行简单的查询,有时候会做一些数据统计与分析,如果你以前是使用的关系型数据库,那么Es的数据统计跟关系型数据库还是有很大的区别的,所以,这篇内容,为了更好的理解,我简单对比了Es中统计的写法与关系型数据库的写法。
首先,先了解一下Es中关于聚合的概念:
1:桶(Buckets)满足特定条件的文档的集合;
2:指标(Metrics)对桶内的文档进行统计计算
这两个概念是什么意思?先看下面一段T-SQL统计代码:
SELECT Color,SUM(1) as Nums【2】 FROM #Cars GROUP BY Color 【1】
桶:满足特定条件的集合,这个很好理解,比如可以把蓝色的放到蓝色的桶里,绿色的放到绿色的桶里,桶是用来存放不同类型的集合。SQL代码中【1】就可以理解对桶进行分组,有多少种颜色,就会有几种不同的桶。桶类似于SQL中GROUP BY;
指标:对桶内的数据进行统计计算。SQL代码中【2】就可以理解为指标,每个桶里有多少条记录。指标类似于SQL中各种汇总,如Count(),Sum(),Max(),Min();
概念了解之后,对比来了, 我们来做一组数据:
1. 创建表结构并填充数据
1.1创建SQLSERVER结构与数据
CREATE TABLE #Cars ( ID int IDENTITY(1,1) NOT NULL, --创建自增序列 Price int, --价格 Color varchar(50), --颜色 Make varchar(50), --品牌 Sold datetime, --销售日期 Primary key(ID) --定义ID为临时表#Cars的主键 ); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (10000,'红色','汉兰达','2014-10-28'); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (20000,'红色','汉兰达','2014-11-05'); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (30000,'绿色','福特','2014-05-18'); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (15000,'蓝色','丰田','2014-11-05'); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (12000,'绿色','丰田','2014-07-02'); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (20000,'红色','汉兰达','2014-11-05'); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (80000,'红色','宝马','2014-01-01'); INSERT INTO #Cars(Price,Color,Make,Sold) VALUES (25000,'蓝色','福特','2014-02-12');
1.2创建Elastsearch 结构与数据
POST /testindex/cars/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "红色", "make" : "汉兰达", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "红色", "make" : "汉兰达", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "绿色", "make" : "福特", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "蓝色", "make" : "丰田", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "绿色", "make" : "丰田", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "红色", "make" : "汉兰达", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "红色", "make" : "宝马", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "蓝色", "make" : "福特", "sold" : "2014-02-12" }
2. 统计查询对比
上面的代码中,分别创建了Es与SQLSERVER的数据结构,并且填充了一些数据。接下来,我们来举几个统计的例子,来看看他们两个之间的统计代码分别怎么写。
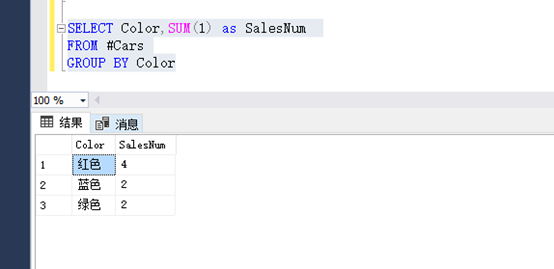
2.1 统计哪个颜色的销量最好?
【SQLSERVER实现】
SELECT Color,SUM(1) as SalesNum FROM #Cars GROUP BY Color
结果如下图:
【Elasticsearch 实现】
GET testindex/cars/_search { "size": 0, 【3】 "aggs": {【1】 "SalesNum": { 【2】 "terms": {【4】 "field": "color.keyword", "size": 10 } } } }
结果如下图:
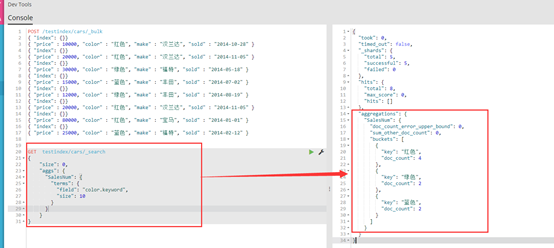
【1】:如果想要进行统计分析,统计代码需要写在aggs中,aggs是aggregations 的简称,也可以写作 aggregations。
【2】:是指定的列的名称,作用同SQLSERVER统计中as 重命名。
【3】:这里设置了返回值为0,因为这个查询不仅仅返回了我们的统计的内容,还返回了搜索结果的内容,这里我们并不需要搜索结果的内容,所以设置为0.
【4】:这里定义了桶的类型,如果需要不同的统计内容,这些需要使用不同的统计类型。
2.2 按颜色统计出平均价格?
【SQLSERVER实现】
SELECT Color,AVG(Price) as '平均价格' FROM #Cars GROUP BY Color
【Elasticsearch 实现】
GET testindex/cars/_search { "size": 0, "aggs": { "s": { "terms": { "field": "color.keyword", "size": 10 }, "aggs": { "avg_price": { "avg": { "field": "price" } } } } } }
2.3 按照颜色统计出平均价格、最高价格、最低价格?
【SQLSERVER实现】
SELECT Color,AVG(Price) as '平均价格',MIN(Price) as MinPrice,MAX(Price) as MaxPrice FROM #Cars GROUP BY Color
【Elasticsearch 实现】
参考:https://elasticsearch.cn/question/4799
2.4 统计每一个企业品牌的最低价格和最高价格?
【SQLSERVER实现】
SELECT Make,MIN(Price) as MinPrice,MAX(Price) as MaxPrice FROM #Cars GROUP BY Make
【Elasticsearch 实现】
GET testindex/cars/_search { "size": 0 ,"aggs": { "make": { "terms": { "field": "make.keyword" } ,"aggs": { "price_age": { "avg": { "field": "price" } }, "min_price": { "min": { "field": "price" } } ,"max_price":{ "max": { "field": "price" } } } } } }
通过上面的几个示例,我简单总结了几个SQLSever 中汇总函数与Es 的对比,看下面的表格:
|
SQLSERVER函数 |
Agg_Type |
功能说明 |
|
GROUP BY 字段名称 |
Terms (避免使用分词字段用来分组) |
分组、Es划分桶 |
|
Max()函数 |
Max |
求最大值 |
|
Min()函数 |
Min |
求最小值 |
|
Avg()函数 |
Avg |
求平均值 |
今天就先对比下简单的聚合汇总、求平均值统计,明天再对比下其他的,比如日期的聚合以及聚合的排序等。