软件工程个人作业
单词频率统计
娄雨禛 PB16060356
作业内容: http://www.cnblogs.com/denghp83/p/8627840.html
一、项目分析
本次项目的最大难度在于单词的储存形式。因为样本量很大,如果没有找到好的储存形式,不仅搜索过程将会非常慢,也会很容易出现内存溢出的错误。
主要的存储方式有以下几种:
1. 哈希表
将每个单词哈希散列到合适的位置。由于哈希查找的效率很高,在哈希函数合理的情况下,能够获得较快的查找速度。
2. 词典树
又称单词查找树,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
3. 多重链表组
将前四个字母的所有排列组合作为链表表头,在此基础上,每读到一个单词,便把它存储到对应的链表中。由于前四个字母能较大地对所有的单词进行筛分,每个链表中的元素个数不会很多。同时,初始的链表都指向空地址,需要时再申请,这样不会占用过大的空间。
本次实验我先采用的是多重链表组的储存形式。然而在后续编程过程中发现,这个数据结构非常不适合本次实验,因为选用的文本大多数是长篇小说,英文单词的出现有明显的分布密度,导致链表的长度分布不均,在单词出现频率高的地方链表极长,当为文件很大时查找速度非常慢。
于是,后来我临时改用了哈希表的储存形式,虽然功能完成很不完善,但速度大大提升。
二、进度规划与完成情况
| 进度规划 | 计划用时 | 实际用时 |
|---|---|---|
| 建立代码框架 | 60 min | 120 min |
| 实现文件夹递归遍历 | 60 min | 180 min(之前不了解遍历的函数,摸索了半天) |
| 统计字符以及行数 | 10 min | 20 min(初步实现时,每个文件的最后一个字符没有统计,后来补上) |
| 统计单词数目 | 180 min | 200 min(单词数目仍与助教有差异) |
|
统计词组数目 TOP10 输出 |
120 min 120 min |
240 min 120 min |
| 字典格式输出 | 120 min | 60 min |
| linux性能分析 | 180 min | 逐步增加 |
| 收尾工作,测试细节 | 120 min | 120 min |
三、主要函数
遍历文件夹函数 getAllFiles
1 void getAllFiles(string path, vector<string>& files) 2 { 3 char * location; // location converts char * into string 4 long handle = 0; // File Handle 5 struct _finddata_t fileinfo; // File Information 6 string p; 7 8 if((handle = _findfirst(p.assign(path).append("\\*").c_str(), &fileinfo)) != -1) 9 { 10 do 11 { 12 if((fileinfo.attrib & _A_SUBDIR)) // to check whether it is a folder or a file 13 { 14 if(strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0) 15 { 16 files.push_back(p.assign(path).append("\\").append(fileinfo.name)); 17 getAllFiles(p.assign(path).append("\\").append(fileinfo.name), files); 18 } 19 } 20 else 21 { 22 files.push_back(p.assign(path).append("\\").append(fileinfo.name)); 23 location = (char *)p.data(); 24 OpenFile(location); 25 } 26 } 27 while(_findnext(handle, &fileinfo) == 0); 28 _findclose(handle); // close the handle 29 } 30 }
单词比较函数 WordCompare
1 char WordCompare(char *ch1, char *ch2) 2 { 3 int i = 0; 4 5 char chTemp1[100] = {0}; 6 char chTemp2[100] = {0}; 7 8 for(int i = 0; ch1[i] != '\0'; i++) 9 chTemp1[i] = ch1[i]; 10 for(int i = 0; ch2[i] != '\0'; i++) 11 chTemp2[i] = ch2[i]; 12 13 WordConvert(chTemp1, chTemp2); // convert all small letters to big letters 14 15 while(chTemp1[i] != '\0' || chTemp2[i] != '\0') 16 { 17 if(IsLetter(chTemp1[i])&IsLetter(chTemp2[i])) 18 { 19 if(chTemp1[i] < chTemp2[i]) 20 return -1; 21 else if(chTemp1[i] > chTemp2[i]) 22 return 1; 23 else 24 i++; 25 } 26 else if(IsLetter(chTemp1[i]) & !IsLetter(chTemp2[i])) 27 return 1; 28 else if(!IsLetter(chTemp1[i]) & IsLetter(chTemp2[i])) 29 return -1; 30 else 31 i++; 32 } 33 return 0; 34 }
单词搜索函数 WordSearch
1 struct Word *WordSearch(struct Word *pointer) 2 { 3 if(pointer == NULL) // if the list is empty 4 { 5 PI.InsertOrReplace = 0; // insert 6 } 7 8 else // if the list is not empty 9 { 10 while((pointer != NULL) && WordCompare(pointer->word, tempWord) != 0) 11 pointer = pointer->next; 12 13 if(pointer == NULL) 14 { 15 PI.InsertOrReplace = 0; // insert at the head 16 } 17 18 else // replace or take no action 19 { 20 if(strcmp(pointer->word, tempWord) > 0) 21 PI.InsertOrReplace = 1; // replace 22 23 else if(strcmp(pointer->word, tempWord) <= 0) 24 PI.InsertOrReplace = 2; // no action 25 } 26 } 27 return pointer; // return the right position 28 }
单词储存函数 StoreWord
1 void StoreWord() 2 { 3 struct Word *insertPointer; // insertPointer points to the position to insert 4 struct Word *tempPointer; // tempPointer puts the new word into the list 5 6 tempPointer = (struct Word*)malloc(sizeof(struct Word)); // new space 7 tempPointer->fre = 1; 8 strcpy(tempPointer->word, tempWord); 9 10 insertPointer = WordSearch(headWord); // to see whether we should insert, replace or take no action 11 12 if(PI.InsertOrReplace == 0) // insert at the head 13 { 14 tempPointer->next = headWord; 15 headWord = tempPointer; 16 } 17 18 else if(PI.InsertOrReplace == 1) // replace and increase frequency 19 { 20 strcpy((insertPointer)->word, tempPointer->word); // copy 21 insertPointer->fre++; 22 } 23 24 else if(PI.InsertOrReplace == 2) // increase frequency only 25 insertPointer->fre++; 26 }
获取TOP10单词函数 StoreMaxFreWords
1 void StoreMaxFreWords(struct Word *p) 2 { 3 short position; 4 short move; 5 6 while(p != NULL) 7 { 8 if(MaxWordFre[0].fre == 0) 9 { 10 strcpy(MaxWordFre[0].word, p->word); 11 MaxWordFre[0].fre = p->fre; 12 } 13 14 else 15 { 16 position = 0; 17 18 while(p->fre < MaxWordFre[position].fre) // find the right position to store 19 position++; 20 21 if(position < 10) 22 { 23 if(p->fre == MaxWordFre[position].fre && WordCompare(p->word, MaxWordFre[position].word) == -1) // ready to store after the position 24 { 25 for(move = 9; move >(position + 1); move--) 26 { 27 strcpy(MaxWordFre[move].word, MaxWordFre[move - 1].word); 28 MaxWordFre[move].fre = MaxWordFre[move - 1].fre; 29 } 30 strcpy(MaxWordFre[position + 1].word, p->word); 31 MaxWordFre[position + 1].fre = p->fre; 32 } 33 34 else // ready to store right in the position 35 { 36 for(move = 9; move > position; move--) // clear up the space to store 37 { 38 strcpy(MaxWordFre[move].word, MaxWordFre[move - 1].word); 39 MaxWordFre[move].fre = MaxWordFre[move - 1].fre; 40 } 41 strcpy(MaxWordFre[position].word, p->word); // store 42 MaxWordFre[position].fre = p->fre; 43 } 44 } 45 } 46 47 p = p->next; 48 } 49 }
四、简单的数据测试
我自己创建了如下几个小文件进行测试。之所以创建小文件是因为它们更方便查错。
程序运行结果
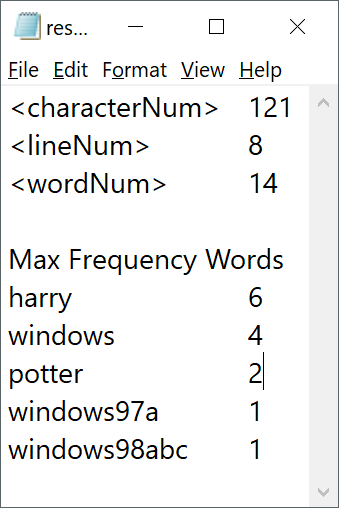
可以看到,在小文件下,有效实现了初步统计单词的功能。然而,在文件夹中内容较多时,程序运行较慢,需要进一步优化。
五、代码优化
优化 1 数据结构优化
数据结构的选择是影响本次实验结果的关键。我一开始选择了链表的数据结构。在意识到链表插入速度很慢的情况下,没有及时地更换数据结构,而是采用了“多链表”的弥补措施。这其实本身是一种哈希映射,但拙劣地搬到链表上实现之后,不仅使我编程极为困难,错误极多,还因为英文单词的不均匀分布仍然继承了单链表的特性。在之后,匆忙更换数据结构,采用哈希表的形式存储数据,效率大增。
优化 2 函数调用优化
通过编写很多的功能清晰的小函数固然在编程时便于理解和操作,但不断调用这些小函数很可能会使运行效率大大降低。其原因是,在调用函数时,新的地址压栈,如果函数调用很多,这种压栈弹栈的操作就极为频繁,拖慢程序的运行速度。为此,我总结得到,不能过于追求小功能函数的书写,而应当全局考虑,在多循环语句中尽量不要塞入很多的函数调用。
优化 3 热行优化
通过 Visual Studio 观察程序运行状况,分析出热行,进行优化。这说起来比较简单,实际操作还是很复杂的,有待进一步摸索。
第一代程序 多重链表数据结构 性能分析
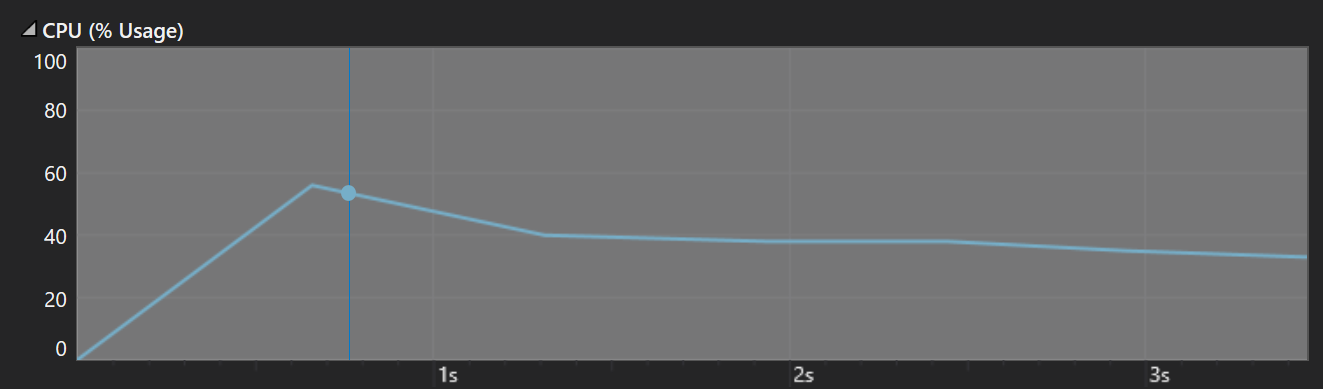
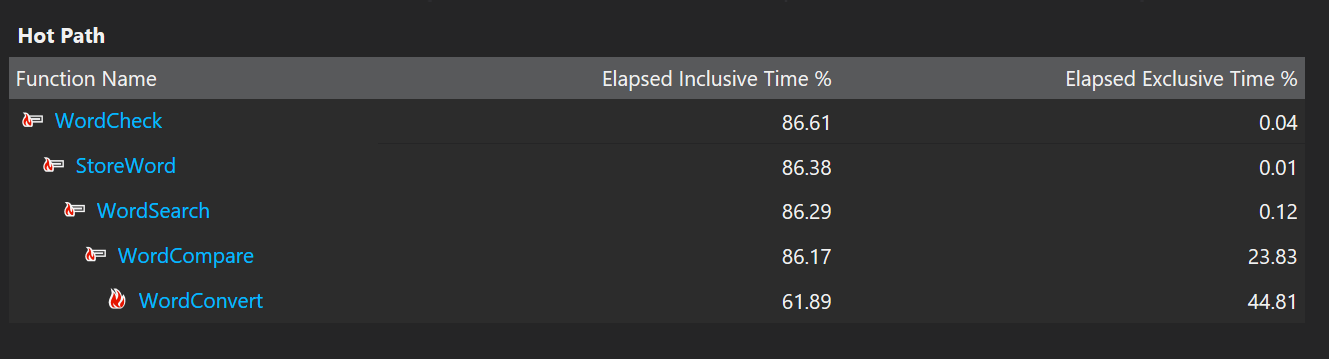
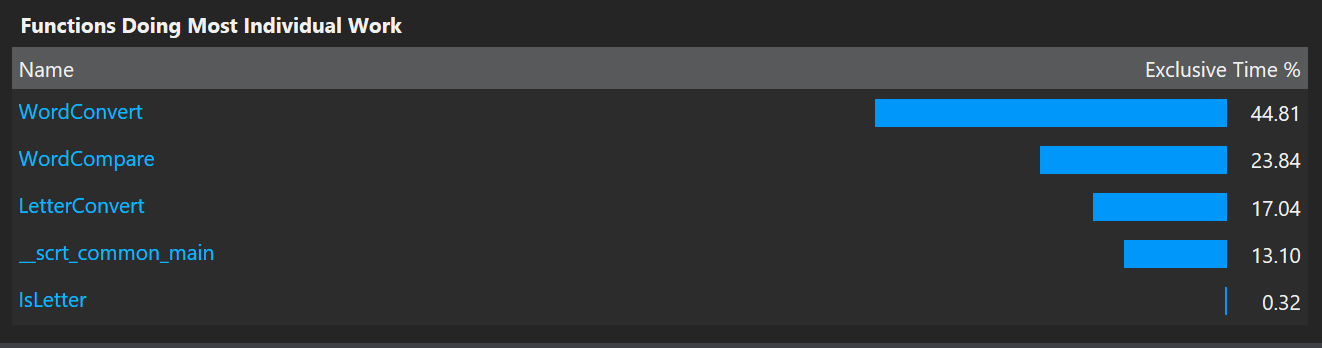
从以上三个截图可以看出,程序大部分的运行时间都消耗在了单词转换函数上。单词转换函数的作用是,将两个单词的英文部分全部转化成大写后进行比较。之所以占用频率这么高,是因为我的程序里频繁调用单词比较,而单词比较又调用了单词转化,单词转化又调用了字母转化。这样,这三个函数消耗了大部分的性能。
然而,对这部分进行优化的意义没有数据结构优化来的有效果。数据结构决定了我现在的这个程序有这样拙劣的性能表现。因为我现在是链表结构。在数据查找过程中,频繁地需要比较。如果能换一个数据结构,比如哈希表,就能较好地解决频繁比较的问题。
之后,我匆忙地将数据结构换为哈希表。
六、编程困惑与心得
在程序的编写过程中,很重要的一点就是合理分析编程过程中的各个难点,提前思考和准备。
比如,自己之前并不知道遍历文件夹内部文件的方式,也对各种储存结构孰优孰劣没有一个较好的判断。最终选择多重链表组的方式是因为自己对链表的结构还算比较熟悉。然而,在实际操作过程中,对链表中元素的查找、替换,着实费了一番功夫。现在列举几个让我困惑良久的细节。
1.在链表的插入中,最合理的就是分为两种插入:头插和非头插,实现这两种插入的区别点在于指针位置和交换顺序的差异。如果在继续细分,不仅没有必要,还会增大出错的概率。
2.不同的指针可以指向同一个地址,而我们若直接进行指针之间的赋值,则不能改变指向同一个地址的另外的指针。这一点和数学中函数的定义有点类似。它理解起来虽然很简单,但实际编程过程中总是容易搞错。比如,在“有序查找非头插”中,就要非常注意这个问题。
3.特别注意,返回值在分支语句中的使用。不要忽视编译器提出的“不是所有的分支都有一个返回值”的警告。
4.有效建立贮存相关操作信息的结构体,它有助于我们实现清晰的结构。这一点很类似于嵌入式开发中的数不胜数的标志位信息。我们也要掌握这种方法。
5.善用 Visual Studio 自带的调试工具。恰当且有效的断点能够马上发现问题所在。系统监视能够直观地查看程序运行时的资源调用情况。
6.一定要在构思的时候选择最优的数据结构,这将让我在编程时事半功倍。
七、代码跨平台解决方案
以下仅对 Windows平台 和 Linux平台 的“跨平台解决方案”做一个简短的说明,Mac OS平台 的解决方案有待以后补充。
一些比较重要的注意点归纳
(参考网上的博文 https://blog.csdn.net/benpaobagzb/article/details/50814543)
1.关于路径和头文件路径分隔符的问题
在Windows中,正斜杠和反斜杠都可以,但是在Linux中,只能是/。
在Windows中,路径大小写无所谓,在Linux中严格区分大小写。
2.char的问题
如果考虑跨平台,需要明确指定是signed或者unsigned,因为不同平台直接声明char,会导致signed或者unsigned的不确定性。
3.关于宽字符的问题。
在Windows中,wchar_t占两个字节,Linux中占四个字节,但是在Linux可以指定两个字节,这样也会造成一个问题,就是某些第三方库中wchar_t可能只指定四个字节的,这样就会导致不兼容。
4.字符串比较函数
Linux里面没有stricmp函数,在Linux下面是strcasecmp函数比较字符串。
5.平台调用
与平台相关的调用尽量用宏隔离开来,一般用不同的目录代表不同平台,BOOST、OGRE等是这样做,也可以再一个类或者文件中,这样会导致到处都是操作系统和编译器相关宏的定义。
6.头文件包含
在Windows下某些C标准库的头文件不用显式包含,但是在linux下需要显式包含。所以在.c和.cpp文件中尽量包含这个文件中需要的头文件。
7.注意机器大尾端和小尾端的区别
大小尾端对文件的读写会有很大影响,要编写跨平台c++程序,大小尾端是必须要考虑的问题。比如,你在大尾端机器上写了一个文件,然后在小尾端机器上读取,那么结果肯定是错误的,所以,我们设计文件格式时,都需要规定文件是大尾端存储还是小尾端存储,或者一个文件中规定某些部分是大尾端某些部分是小尾端。
8.尽量只使用STL较早出现的函数或类
较早出现的东西相对来说比较稳定,STL的各个实现基本上都会有实现,这样跨平台的时候可以兼容多个平台。
9.空间命名
使用std::exception时需要注意,LINUX下是不支持抛出异常的,如果继承自标准库的异常类写自己的异常类的时候,在Linux下,子类的析构函数中就需要表明不抛出异常,所以析构函数后面加上throw()就可以了。
10.当继承模板类时。需要谨慎
在自己的代码中,需要继承模板类时,如果需要访问基类模板类的成员函数或者成员变量,前面加上this->。另外,构造函数需要用到基类进行构造时。基类的类型需要需要用该类的类型参数初始化,否则在linux下会提示找不到基类的这个名字。
11.库函数习惯
尽量使用标准C和C++的函数以及STL,使用C语言中定义的类型。
12.头文件重复包含
尽量用保卫宏去实现防止头文件的重复包含,很多代码在Windows下直接用#pragma once,这不能保证跨平台需要。
13.结构体对齐
CPU为了简化内存和CPU之间的处理以及加快CPU从内存中取数据的速度,往往都会做一定的对齐,即结构体的各个成员并不是紧凑存储的,往往在成员中间填充一些字节。所以,我们一般不推荐用结构体直接读取和写入数据,这样在不同系统或者计算机之间进行移植时,会出现错误的结果。
14.注意BOM的陷阱
如果你在Windows用记事本创建一个源文件,那么Windows会在文件最前面加上一个BOM标记,即所谓的字节顺序标记,这样的源码在Windows下没问题,但是在Linux下就编译不过,所以需要用其他的文本编辑器或者直接在VS里面创建源文件。Linux下gcc/g++不认带BOM标记的源文件。
15.形参实参类型匹配
注意调用函数时的形参类型和函数声明中参数列表的类型不匹配。这里特指有无const或者是否是引用参数。在Windows下的cl编译器没问题,linux下GCC/G++会报错。
16.书写规范
注意两个尖括号不要连着写。
例如:std::vector<std::vector<int>> vec;在Windows下这么写完全没问题,那么在linux下就是编译不过,所以linux下可以在连续两个尖括号符号之间留一个空格,即std::vector<std::vector<int> > vec;
本次实验的两个个重要跨平台操作
1.预编译宏定义
不同的宏定义可以区分不同的操作系统。
1 Windows: WIN32 // windows 操作系统 2 Linux: __linux__ // linux 操作系统 3 VC: _MSC_VER // windows 编译器 4 GCC/G++: __GNUC__ // linux 编译器
2.不同库函数的引入
利用 #indef 和 #endif 语句,对不同操作系统引入不同库函数。
1 #ifdef __linux__ 2 #include <dirent.h> 3 #endif
4 #ifdef WIN32 5 #include<io.h> 6 #endif
八、代码调优法则
代码调优大致有以下六条法则。
空间换时间法则
空间换时间在很多地方都见得到。比如,求斐波那契数列时,我们为了防止递归所产生的庞大计算量拖慢运行速度,往往将之前步骤的数据存储起来,以便后次调用。空间换时间的思想在今天尤为适用。随着储存空间的大幅增加,我们更追求速度的提升。
时间换空间法则
密集储存表可以通过增加储存和检索数据所需的时间来减小存储开销。
循环法则
将代码移出循环 与其在循环的每一次迭代中都执行一次某种运算,不如将其移到循环体外,只计算一次。
循环展开 通过将循环展开,可以减少修改循环下标的开销,从而有效避免管道延迟,增加指令的并行性。
删除赋值 如果内循环中很多开销来自普通的赋值,通常可以通过重复代码并修改变量的使用来删除这些赋值。
消除无条件分支
循环合并
逻辑法则
利用等价的代数表达式。如果逻辑表达式的求值开销太大,就将其替换为开销较小的等价代数表达式。
过程法则
打破函数层次。对于调用自身的函数,通常可以将其改写为内联版本并固定传入的变量来缩短其运行时间。
表达式法则
消除公共子表达式。如果两次对同一个表达式求值时,其所有变量都没有任何改动,那么,就应当储存第一次的变量值以取代第二次的求值。