0x00 中国最好大学排名的爬取
我们通过上海交通大学设计研发的最好大学网来进行数据的抓取
这是本次爬取的url:软科中国最好大学排名

功能描述:
输入目标url
输出大学排名信息(排名、学校、总分)
技术路线:requests-bs4
定向爬取:只对该url进行爬取
分析:
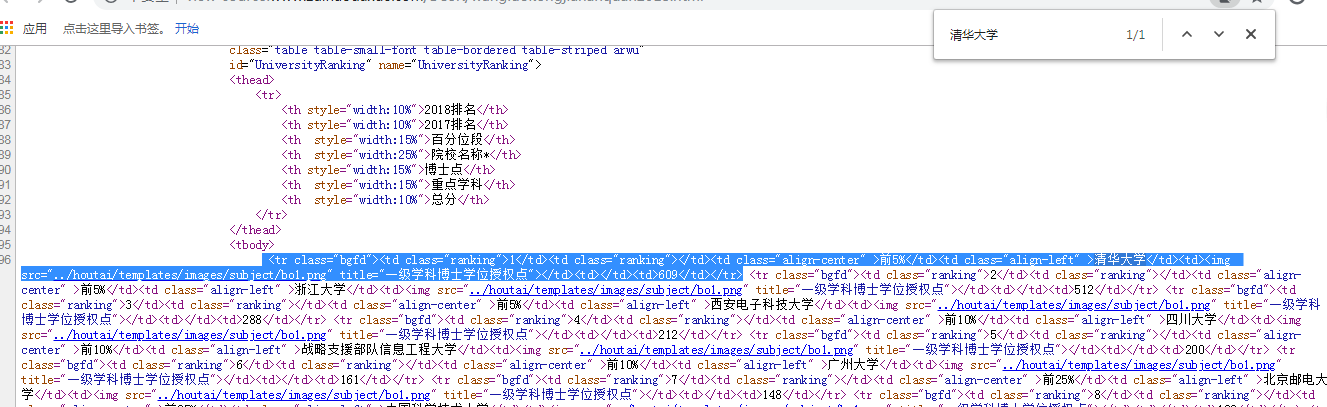
查看网页源代码,为了快速定位,可以直接在源代码页面搜索“清华大学”,就能迅速定位我们想要的代码段,确定爬取计划可行。
接下来,我们查看根目录下的robots.txt文件,确认爬取行为的合法性,经过实践,该网站根目录下并不存在robots.txt文件,因此该网站没有对爬虫进行限制。
程序结构设计:
步骤1:从url中获取网页内容
步骤2:提取网页中的信息到合适的数据结构
步骤3:利用数据结构展示并输出结果
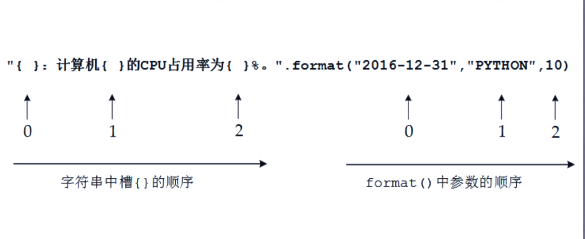
同时介绍一下print()函数中format方法,format后面的内容会按顺序替换相应的大括号
import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): #爬取页面 try: r = requests.get(url, timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def fillUnivList(ulist, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find('tbody').children: #查找tbody标签,并遍历下面的子标签 if isinstance(tr, bs4.element.Tag): #检测tr标签,若不是Tag类型则过滤 if len(tr('td') ) == 7: tds = tr('td') #将所有td标签存为列表类型 ulist.append([tds[0].string, tds[3].string, tds[6].string]) #将我们需要的td标签的内容存入列表 def printUnivList(ulist, num): print("{:^10} {:^6} {:^10}".format("排名", "学校名称", "总分")) for i in range(num): u = ulist[i] print("{:^10} {:^6} {:^10}".format(u[0], u[1], u[2])) def main(): uinfo = [] url = "http://www.zuihaodaxue.com/BCSR/wangluokongjiananquan2018.html" html = getHTMLText(url) fillUnivList(uinfo, html) printUnivList(uinfo, 10) main()