此为之前偶尔在社区看到的优秀作业“链家2011-2016北京二手房成交数据分析”,在此为了工作简历上的项目巩固复习练习一次。
环境准备
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline
插入数据
#数据读取
f=open(r'D:DocumentsTencent Files2698968530FileRecv日月光华链家成交数据lianjia1.csv') data=pd.read_csv(f)
观察数据
data.head()
合并
数据源一共是7个csv文件,文件名是“lianjia+1到7”,可以使用循环语句将七个文件写入到一个列表dataR中
dataR=[] for i in range(1,8): f=open(r'D:DocumentsTencent Files2698968530FileRecv日月光华链家成交数据lianjia{}.csv'.format(i)) data=pd.read_csv(f) dataR.append(data)
出现了error
UnicodeDecodeError: 'gbk' codec can't decode byte 0x97 in position 154: illegal multibyte sequence
这说明7个文件的编码类型还不一样,部分数据不能用gbk类型解码。那我们就需要使用try except方法,先try gbk编码,不行就except使用我们默认的utf-8编码
dataY=[] for i in range(1,8): try: f=open(r'D:DocumentsTencent Files2698968530FileRecv日月光华链家成交数据lianjia{}.csv'.format(i),encoding='gbk') data=pd.read_csv(f) except: f=open(r'D:DocumentsTencent Files2698968530FileRecv日月光华链家成交数据lianjia{}.csv'.format(i),encoding='utf-8') data=pd.read_csv(f) dataY.append(data)
输出列表长度看是否是7
len(dataY)
随便取一个的几行看看
dataY[2].tail()

数据正常显示,说明并没有问题。但是这是一个list,我们怎么把7个数据合并到一起呢?这就需要使用到pandas包里面的concat函数。
data=pd.concat(dataY)
对他进行描述性统计分析
data.shape

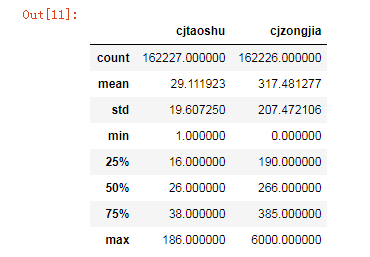
data.describe()
data.info()

data.head()
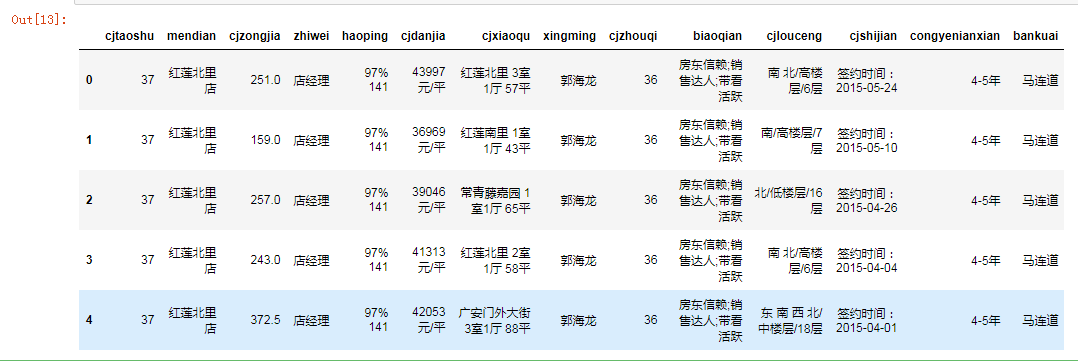
这个数据集一共有141140条数据,14个属性值,只有“套数”和“总价”是数值类型,其他的都是字符串类型,再取他的前3行进行观察,发现成交单价是字符串类型,因为它写的是xxx元/平。后期还需要再对成交单价进行数据的处理操作。
接下来我们要对数据进行预处理了,但是首先要想到的是,数据有没有缺失值,通过对结果是否报错来判断是否有缺失值
data.isnull()
...
对这些布尔值进行sum运算,可以得出有多少缺失值
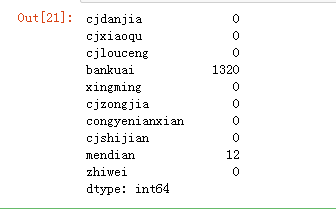
(data.isnull()).sum()

结果得出版块(bankuai)数据缺失值为1321,门店(mendian)缺失值为13条,其他的数据缺失值都是1条。
data[data.cjdanjia.isnull()]
data.dropna(how='all',inplace=True)
data.isnull().sum()

发现第57119条数据缺失是很多属性一起缺失的,使用drop_duplicates把这条数据删除,在此之前,因为这个函数是删除重复的下一条数据,因此需要将数据按照地区排序,将空值放在后位进行删除,最后进行检查。
用duplicated的subset参数指定重复的列,查找出来这些列重复的数据。然后再排序
(data.duplicated(subset=['cjdanjia','cjxiaoqu','cjlouceng','bankuai'])).sum()
data.sort_values(by='bankuai',inplace=True)
再使用drop_duplicates函数,就可以去掉这些重复值了,同时能保留板块的有效信息
data.drop_duplicates(subset=['cjdanjia','cjxiaoqu','cjlouceng'],inplace=True)
数据类型转换,异常值处理,数据离散化
我们想对成交单价进行分析,这列数据非常重要。但是它是字符串形式,我们要把单价和'元/平'分开来。首先我们先看一下是不是所有数据包含了'元/平'。波浪号~放在语句前面表示否定。
data.head()
(~data.cjdanjia.str.contains('元/平')).sum()
得出结果为0。 得出不包含'元/平'的数据数量为0 ,则就是都有'元/平'。那我们定义一个lambda x函数,把这里数据进行转换,把'元/平'替换为空字符串
data.cjdanjia.map(lambda x:round(float(x.replace('元/平',''))/10000,2))
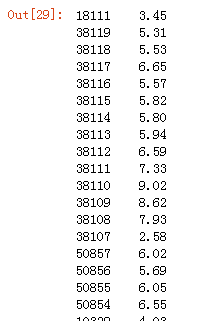
把元/平变成了空字符串,那么数据就只留下了单价数值。然后我们把这个单价从字符串object类型,astype变成float类型,便于后面的计算。然后除以10000,用round函数保留2位小数点。这样得出来的结果就是3.45万,5.31万的类型。
看成交单价的最大最小值
data.cjdanjia.min()
data.cjdanjia.max()
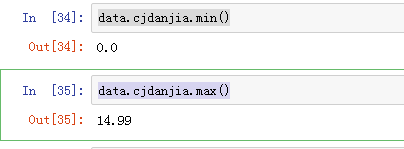
发现最小值为0,去掉0的数据,再看最小值
data=data[data.cjdanjia>0]
data.cjdanjia.min()
此时最小值为0.01,还是不正常,为了处理这样的异常值,我们需要设置一个范围,比如5000元一平,往上的数据才算有效数据
data=data[data.cjdanjia>0.5]
data.cjdanjia.min()
此时最小值为0..51,单价数据是我们想要的数据类型了,我们想把这些数据进行离散化,分成多个区间,看成交单价的分布,这个时候就需要使用到bins和cut函数
bins=[0,1,2,3,4,5,7,9,11,13,15]
pd.cut(data.cjdanjia,bins)
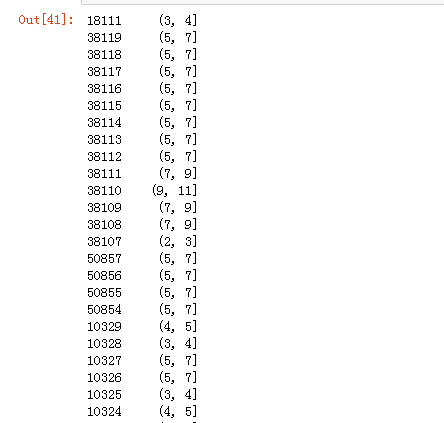
再对这份数据进行value_counts,看看落在各个区间上的数据都有多少
pd.cut(data.cjdanjia,bins).value_counts()
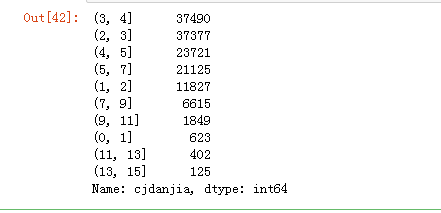
画出点图
pd.cut(data.cjdanjia,bins).value_counts().plot()

然后直接画个柱状图看看。rot是让x轴标签倾斜20度,不然会挤在一起。
pd.cut(data.cjdanjia,bins).value_counts().plot.bar(rot=20)
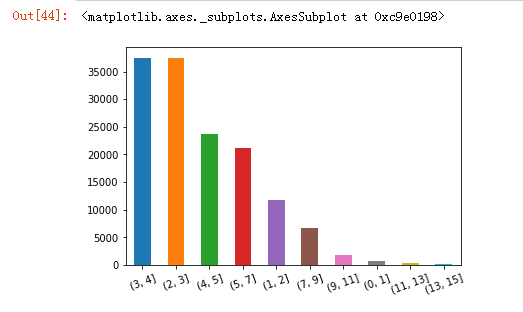
也可以画出饼图
pd.cut(data.cjdanjia,bins).value_counts().plot.pie(figsize=(8,8))
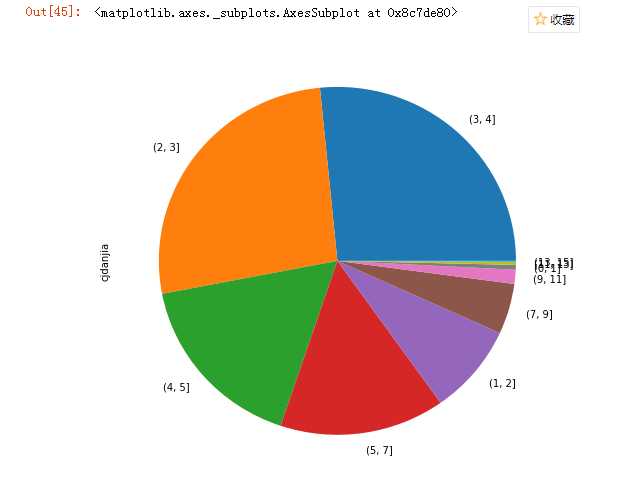
字符串的处理
首先,我们看看是不是所有数据都包含这三个数据,也就是用/分开之后,是不是都是三个数据,以免套用函数报错
(data.cjlouceng.str.split('/').map(len)!=3).sum()
0
data.cjlouceng

可以把朝向这个数据单独取出来之后,单独给原表增加一列'chaoxiang
data.cjlouceng.map(lambda x:x.split('/')[0])
data['chaoxiang']=data.cjlouceng.map(lambda x:x.split('/')[0])
楼层这列也这样处理
data['louceng']=data.cjlouceng.map(lambda x:x.split('/')[1])
data
对楼层取unique,可以看出还有未知这个数据,我们把未知这类数据去掉。(原始数据还有空字符串' ',之前处理的时候已经查找出来了,但是没有记录在此)
data.louceng.unique()

还有未知和空字符串的部分数据也需要处理
data[data.louceng=='']
data[data.louceng=='未知']
data=data[(data.louceng!='未知')&(data.louceng!='')]
data
pd.get_dummies(data.louceng)
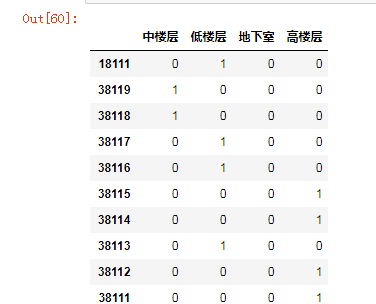
然后我们可以使用get_dummies对楼层的这几个类别进行one-hot处理,这样就能非常方便离散化处理,然后得出各个类别的counts。
然后再使用join函数,把这个结果直接插入到原表后面去
data.join(pd.get_dummies(data.louceng))
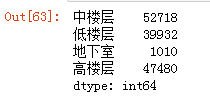
再进行sum,得出各个类别的数量
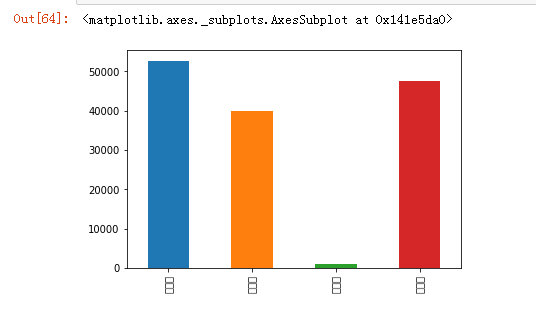
pd.get_dummies(data.louceng).sum()
他的柱形图
pd.get_dummies(data.louceng).sum().plot.bar()
把数据导出成csv文件。为了防止index变成乱码,添加用utf_8_sig编码的参数。
(pd.get_dummies(data.louceng).sum()).to_csv('loucengfenbu3.csv',encoding='utf_8_sig')
分组运算、布尔过滤和数据透视
首先,对于成交时间进行处理,仅取出中间的年
data['cjshijian']=data.cjshijian.map(lambda x:x.split(':')[1])
先进行分隔,取后面的时间,再再按照-进行分隔,取年份
data['year']=data.cjshijian.map(lambda x:x.split('-')[0])
data.groupby(['year','xingming'])['xingming'].value_counts()
分析每一年的经纪人数量。按照年份,经纪人姓名分组
data.groupby(['year','xingming'])['xingming'].count()

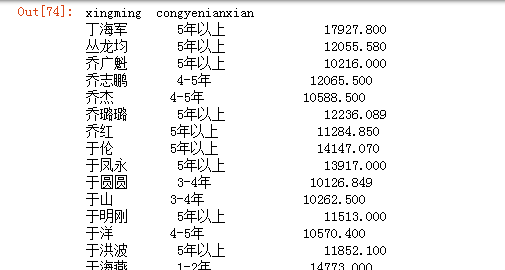
研究成交总价大于1亿的经纪人的工作年限。我们可以先分组,然后再sum,查出大于1亿的数据
data_group=data.groupby(['xingming','congyenianxian'])['cjzongjia'].sum()
data_group[data_group>10000]
等等也可以研究其他的问题。