使用程序设计语言访问数据库
可通过两种方法从通用编程语言(宿主语言)中激发SQL查询:
a. 动态SQL:通用程序设计语言通过函数或方法连接数据库服务器并与之交互。可在运行时以字符串形式构建和提交SQL查询,将结果存入程序变量(每次一个元组)。
b. 嵌入式SQL:嵌入式SQL语句必须在编译时全部确定并交给预处理器,预处理程序提交SQL语句到数据库系统进行预编译和优化,然后把应用程序中的SQL语句替换成相应代码和函数,最后调用程序语言进行预编译和优化。
1. JDBC
JDBC标准:定义Java程序连接数据库服务器的应用程序接口(API)。
JDBC代码示例
import java.sql.*; public static void JDBCexample(String userid, String passwd) { try { Class.forName("oracle.jdbc.driver.OracleDriver"); Connection.conn = DriverManager.getConnection( "jdbc:oracle:thin:@db.yale.edu:1521:univdb", userid, passwd); Statement stmt = conn.createStatement(); try { stmt.executeUpdate( "insert into instructor values('77987','Kim','Phyisics',98000)"); } catch (SQLException sqle) { System.out.println("Could not insert tuple."+sqle); } ResultSet rset = stmt.executeQuery( "select dept_name, avg(salary)"+ " from instructor"+ " group by dept_name"); while(rset.next()) System.out.println(rset.getString("dept_name")+" "+rset.getFloat(2)); stmt.close(); conn.close(); } catch (Exception sqle) { System.out.println("Exception: "+sqle); } }
1)加载驱动:
每个支持JDBC的数据库都会提供一个JDBC驱动程序(JDBC driver),需要动态加载驱动程序才能实现对数据库的访问。连接数据库前必须完成驱动程序的加载。
调用Class.forName函数,通过参数指定一个实现了java.sql.Driver接口的实体类(例中oracle.jdbc.driver.OracleDriver),完成驱动程序的加载。
Java.sql.Driver接口的功能是为了实现不同层面的操作之间的转换。一边是与产品类型无关的JDBC操作,另一边是与产品相关的、在所使用的特定的DBMS中完成的操作。
2)连接到数据库
调用java.sql包中的DriverManager类的getConnection方法打开一个数据库连接,建立Connection对象句柄(例中conn)
//不同版本的getConnection方法参数不同,以下为常用的一种。
参数1:以字符串类型表示的URL,指明服务器所在主机名称(例中dbyale.edu)及可能包含的其他信息。E.g. 与数据库通信所用的协议(例中jdbc:oracle:thin:)、数据库系统用来通信的端口号(2000),服务器端使用的特定数据库(univdb)。
参数2:字符串类型的数据库用户标识。
参数3:字符串类型的密码。
注意:JDBC只指定API而不指定通信协议,用来与数据库交换信息的具体协议并没有在JDBC标准中定义,而是由驱动程序决定。一个JDBC驱动器可能支持多种协议,必须指定一个数据库和驱动器都支持的协议(例中jdbc:oracle:thin:)。
3)向数据库系统中传递SQL语句
打开一个数据库连接后,程序可利用该连接向数据库发送SQL语句用于执行。
可通过Statement类的一个实例(例中在连接变量conn上创建的Statement句柄stmt)实现可以被Java语句调用的一些方法,通过参数传递SQL语句并被数据库系统执行。
executeQuery执行SQL查询语句,返回结果集;
executeUpdate执行SQL非查询性语句,返回值为整数,表示被插入/更新/删除的元组个数。DDL语句返回值为0。
try {…} catch {…} 结构可捕捉JDBC调用产生的异常,并显示给用户适当的出错信息。
4)获取查询结果
Statement对象(例中句柄stmt)调用方法executeQuery执行一次查询,可将结果中的元组集合提取到ResultSet对象(例中rset)并每次取出一个进行处理。
next方法返回布尔变量表示是否从结果集(例中rset)中取回一个元组。(用于查看在集合中是否存在至少一个尚未取回的元组,如果存在则取出。)
一系列名字以get为前缀的方法(例中getString、getFloat)可获取元组的各个属性,不同get方法的参数用于表示所需获取属性在元组中的位置(例中a. 利用属性名dept_name提取; b. 利用属性位置2提取)。
5)预备语句
可创建预备语句,用”?”代表以后再给出的实际值,预先编译语句。每次执行该语句时用新值替换”?”,应用新值重用预先编译的语句。
优点:
同一语句编译一次设置不同参数值执行多次,使执行更加高效;
setString方法可自动完成检查插入需要的转义字符确保语法的正确性。
步骤:
使用Connection类的prepareStatement方法提交SQL语句用于编译,返回一个PreparedStatement类的对象;
使用PreparedStatement类的方法为”?”参数设定具体值。参数1:确定为哪个”?”设定值(从1开始); 参数2:要设定的值;
使用PreparedStatement类的方法executeQuery和executeUpdate执行SQL语句。【执行前必须已为参数设定具体值】
e.g.
PreparedStatement pStmt = conn.prepareStatement(“insert into instructor values(?,?,?,?)”); pStmt.setString(1,”88877”); pStmt.setString(2,”Perry”); pStmt.setString(3,”Finance”); pStmt.setInt(4,125000); pStmt.executeUpdate(); pStmt.setString(1,”88878”); /*参数设定保持不变直到特别重新设定。元组(“88878”,”Perry”,”Finance”,”125000)被插入到数据库。*/ pStmt.executeUpdate();
6)可调用语句
CallableStatement接口允许调用SQL的存储过程和函数。
e.g.
CallableStatement cStmt1 = conn.prepareCall(“{?=call some_function(?)}”);
CallableStatement cStmt2 = conn.prepareCall(“{call some_procedure(?,?)}”);
函数的返回值和郭晨的对外参数的数据类型必须先用方法registerOutParameter()注册。
7)元数据特性
因为数据库中存储的数据的声明是DDL的一部分,Java程序中不包含,所以使用JDBC的Java程序应a. 将关于数据库模式的假设硬编码到程序中 或 b. 直接在运行时从数据库系统中得到信息。(更可取)。
executeQuery方法返回一个封装了查询结果的ResultSet对象;
ResultSet的getMetaData方法返回一个包含结果集元数据的ResultSetMetaData对象;
ResultSetMetaData包含查找元数据信息的方法(如结果的列数、某个特定列的名称、某个特定列的数据类型)。
e.g. 使用JDBC打印一个结果集中所有列的名称和类型
/*rs是执行查询后所获得的一个ResultSet实例*/ ResultSetMetaData rsmd = rs.getMetaData(); for (int I = 1; I <= rsmd.getColumnCount(); i++) { System.out.println(rsmd.getColumnName(i)); System.out.println(rsmd.getColumnTypeName(i)); }
DatabaseMetaData接口提供了查找数据库元数据的机制:
Connection的getMetaData方法返回一个DatabaseMetaData对象;
DatabaseMetaData包含用于获取程序所连接的数据库和数据库系统的元数据。
e.g. 找出数据库中的关系的列(属性)信息
/*conn存储一个已经打开的数据库连接*/ DatabaseMetaData dbmd = conn.getMetaData(); /*get Columns参数1:目录名称(类别,null表示忽略);参数2:模式名称模板;参数3:表名称模板;参数4:列名称模板。 表名称和列名称模板可用于指定一个名字或一个模板,只有满足特定名称或模板的模式中的表的列被检索到。 模板可用SQL字符串匹配特殊字符,”%”匹配所有名字。 返回结果集中每行包括一个列的信息,包含一系列属性,如COLUMN_NAME, TYPE_NAME。*/ ResultSet rs = dbmd.getColumns(null, “univdb”, “department”, “%”); While (rs.next()) { System.out.println(rs.getString(“COLUMN_NAME”), rs.getString(“TYPE_NAME”); }
元数据接口可用于许多不同的任务,使这些任务的代码更通用。
8)其他特性
·可更新的结果集(updatable result sets):JDBC可从一个在数据库关系上执行选择和/或投影操作的查询中创建一个可更新的结果集,一个怼结果集中的元组的更新将引起对数据库关系中相应元组的更新。
·打开或关闭自动提交:JDBC的Connection接口的setAutoCommit()方法允许打开或关闭自动提交(每个SQL语句都被作为一个自动提交的独立事务对待)。
e.g. 如果conn是一个打开的连接,conn.setAutoCommit(false)将关闭自动提交,然后事务必须用conn.commit()显示提交或用conn.rollback()回滚;
conn.setAutoCommit(true)将打开自动提交。
·处理大对象的接口:JDBC提供处理大对象的接口,不要求在内存中创建整个大对象。
ResultSet接口提供getBlob()和getClob()方法,返回类型为Blob和Clob的对象。这些对象并不存储整个大对象,而是存储大对象的定位器(指向数据库中实际大对象的逻辑指针);
从Blob和Clob对象中获取数据与从文件或输入流获取数据类似,可采用类似getBytes和getSubString的方法实现;
反向操作(向数据库存储大对象)时,PreparedStatement类提供方法setBlob(int parameterIndex, InputStream inputStream)可将类型为二进制大对象(blob)的数据库列与一个输入流关联。执行预备语句时,数据从输入流被读取,然后被写入数据库的二进制大对象中;类似,方法setClob可设置字符大对象(clob)列,参数包括该列的序号和一个字符串流。
·行集(row set):JDBC提供行集特性,允许把结果集打包发送给其他应用程序;行集可向后/向前扫描、修改;行集一旦被下载就不再是数据库本身的内容。
9)关闭连接
因为数据库连接个数有限制,Java程序结束时语句(例中stmt)和连接都应该被关闭。
2. ODBC
ODBC:开放数据库互连,应用程序用该标准定义的API打开一个数据库连接、发送查询和更新、获取返回结果等。
e.g. C语言ODBC代码示例
void ODBCexample() { RETCODE error; HENV env; //环境参数变量 HDBC conn; //数据库连接 SQLAllocEnv(&env); SQLAllocConnect(env, &conn); SQLConnect(conn, "db.yale.edu", SQL_NTS, "avi", SQL_NTS, "avipasswd", SQL_NTS); { char deptname[80]; float salary; int lenOut1, lenOut2; HSTMT stmt; char * sqlquery = "select dept_name, sum (salary) from instructor group by dept_name"; SQLAllocStmt(conn, &stmt); error = SQLExecDirect(stmt, sqlquery, SQL_NTS); if (error == SQL_SUCCESS) { SQLBindCol(stmt, 1, SQL_C_CHAR, deptname, 80, &lenOut1); SQLBindCol(stmt, 2, SQL_C_FLOAT, &salary, 0, &lenOut2); while (SQLFetch(stmt) == SQL_SUCCESS) printf("%s %g ", deptname, salary); } SQLFreeStmt(stmt, SQL_DROP); } SQLDisconnect(conn); SQLFreeConnect(conn); SQLFreeEnv(env); }
1)分配一个SQL环境变量和一个数据库连接句柄,调用SQLConnect打开数据库连接(参数:数据库连接句柄、要连接的服务器、用户的身份和密码等。常数SQL_NTS表示前面参数是一个以null结尾的字符串);
2)建立连接后,可通过SQLExecDirect语句发送命令到数据库;
SQLBindCol可将查询结果的属性值和C语言变量绑定,
参数2: 选择属性中哪一个位置的值; 参数3: SQL应该把属性转化成什么类型的C变量; 参数4: 存放变量的地址;
对于字符数组等变长类型,最后两个参数还要给出变量的最大长度和一个位置来存放元组取回时的实际长度。如果长度域返回负值代表此值为空(null);对于整型或浮点型等定长类型,最大长度的域被忽略,如果长度域返回负值表示此值为空值;
3)SQLFetch语句取回元组,结果中相应的属性值就可放在对应的C变量里。SQLFetch在while循环中一直执行直到返回一个非SQL_SUCCESS的值,每次fetch过程中都把值存放在SQLBindCol指定的C变量中并打印;
4)检查函数结果确保没有错误,会话结束时释放句柄,断开与数据库的连接,同时释放连接和SQL环境句柄。
其他特性:
1)可创建带有参数的SQL语句。
e.g.
insert into department values(?,?,?)
该语句在数据库中先编译,然后通过为占位符(?)提供具体的值来反复执行。
2)ODBC为各种不同任务定义了函数,如查找数据库中所有关系、查找数据库中某个关系的列的名称和类型、一个查询结果的列的名称和类型等。
3)默认情况下每一个SQL语句都被认为是一个自动提交的独立事务。SQLSetConnectOption(conn, SQL_AUTOCOMMIT, 0)可关闭连接conn的自动连接,使事务必须通过显式调用SQLTransact(conn, SQL_COMMIT)提交或显式调用SQLTransact(conn, SQL_ROLLBACK)回滚。
4)ODBC定义了符合性级别(conformance level)指定标准定义的功能的子集。一个ODBC实现可以仅提供核心级特性,也可以提供更多的高级特性(level1、level2)。
3. 嵌入式SQL
SQL查询所嵌入的语言称为宿主语言,宿主语言汇总使用的SQL结构称为嵌入式SQL。
嵌入式SQL与JDBC/ODBC的主要区别:使用嵌入式SQL的程序在编译前必须由一个特殊的预处理器进行处理,用宿主语言的声明和允许运行时刻执行数据库访问的过程调用代替嵌入的SQL请求,再由宿主语言编译器编译。因此嵌入式SQL中一些SQL相关错误可在编译过程中发现;而JDBC中SQL语句是在运行时被解释的。
EXEC SQL语句使预处理器识别嵌入式SQL请求。格式:
EXEC SQL <嵌入式SQL语句>; /*确切语法依赖于宿主语言*/
在执行任何SQL与拒签程序必须首先连接到数据库。实现语句:
EXEC SQL connet to server user user-name using password; /*server标识将要建立连接的服务器*/
SQL INCLUDE SQLCA语句在应用程序中合适的地方被插入,表示预处理器应该在此处插入特殊变量以用于程序和数据库系统间的通信。
在嵌入式SQL语句中可以使用宿主语言的变量,前面要加上冒号(:)以区别于SQL变量,并且必须声明在一个DECLARE区段里。
e.g.
EXEC SQL BEGIN DECLARE SECTION; /*声明变量的语法依赖于宿主语言*/ int credit_amount; EXEC SQL END DECLARE SECTION;
嵌入式SQL语句格式和SQL语句的重要不同点
声明游标:使用声明游标(declare cursor)语句表示关系查询。此时并不计算查询结果,程序必须用open和fetch语句得到结果元组。
使用游标的方法类似JDBC中对结果集的迭代处理。虽然关系在概念上是一个集合,查询结果中的元组还是有一定的物理顺序。执行open语句后游标指向结果的第一个元组,一条单一的fetch请求只能得到一个元组。执行一条fetch语句后,游标指向结果中的下一个元组。当后面不再有待处理的元组时,SQLCA中变量SQLSTATE被置为’02000’(”不再有数据”,访问该变量的语法依赖于所使用的数据库系统)。可用循环来处理结果中的所有元组。
e.g. 找出学分高于credit_amount的所有学生的名字(credit_amount为已声明的宿主变量)
EXEC SQL declare c cursor for select ID, name from student where tot_cred > :credit_amount; /*可用该查询的游标(例中变量c)标识该查询,用open语句执行查询。 当open语句被执行时,宿主变量(例中credit_amount)的值就会被应用到查询中,数据库系统执行该查询并将执行结果存于一个临时关系中。 如果SQL查询出错,数据库系统将在SQL通信区域(SQLCA)的变量中存储一个错误诊断信息。*/ EXEC SQL open c; /*使用一系列fetch语句可将结果元组的值赋给宿主语言的变量,fetch语句要求结果关系的每一个属性都有一个宿主变量相对应(例中已在DECLARE区段中被声明的变量si存储ID的值,变量sn存储name的值)。*/ EXEC SQL fetch c into :si, :sn; /*产生结果关系中的一个元组*/ /*应用程序可用宿主语言对si和sn进行操作*/ … /*必须使用close语句告诉数据库系统删除用于保存结果的临时关系*/ EXEC SQL close c;
数据库修改请求(update、insert、delete)的嵌入式SQL表达式格式:
EXEC SQL <任何有效的update、insert和delete语句>;
前面带冒号(:)的宿主语言变量可出现在数据库修改语句的表达式中。如果语句执行过程中出错,SQLCA中将设置错误诊断信息。
可通过游标更新数据库关系。
e.g. 为音乐系每个老师的salary属性都增加100
/*声明游标*/ EXEC SQL declare c cursor for select * from instructor where dept_name = ‘Music’ for update; //利用游标上的fetch操作对元组进行迭代,每取到一个元组都执行以下代码 EXEC SQL update instructor set salary = salary+100 where current of c;
可用EXEC SQL COMMIT语句提交事务,或用EXEC SQL ROLLBACK进行回滚。
嵌入式SQL查询一般是在编写程序时被定义的,但某些罕见情况下查询需要在运行时被定义。E.g. 应用程序接口让用户指定某个关系上的一个或多个属性上的选择条件,在运行时只利用用户选择的属性的条件来构造SQL查询的where子句。可使用”EXEC SQL PREPARE <query-name> FROM: <variable>”格式的语句在运行时构造和准备查询字符,并可在查询名字上打开一个游标。
SQLJ:SQL嵌入Java中使用更接近Java固有特性的语法。SQLJ使用#sql代替EXEC SQL,并且用Java迭代器接口代替游标来获取查询结果。查询结果被存储在Java迭代器里,利用Java迭代器的next()方法遍历结果元组(类似游标中的fetch)。
必须对迭代器属性进行声明,其类型应与SQL查询结果中的个属性的类型一致。
迭代器使用方法:
#sql iterator depInfolter (String dept_name, int avgSal); deptInfolter iter = null; #sql iter = { select dept_name, avg(salary) from instructor group by dept_name }; while (iter.next()) { String deptName = iter.dept_name(); Int avgSal = iter.avgSal(); System.out.println(deptName+” ”+avgSal); } iter.close();
函数和过程
1. 声明和调用SQL函数和过程
SQL提供过程扩展允许定义函数、过程和方法(允许迭代和条件语句),存储在数据库里并在SQL语句中调用。过程和函数可通过动态SQL触发。
SQL允许多个过程同名,只要同名过程的参数个数不同。名称和参数个数用于标识一个过程。
SQL允许多个函数同名,只要同名函数的参数个数不同,或者对于有相同参数个数的函数,至少有一个参数的类型不同。
e.g. 定义函数dept_count():给定一个系的名字,返回该系的教师数目
create function dept_count(dept_name, varchar(20)) returns integer begin declare d_count integer; select count(*) into d_count from instructor where instructor.dept_name = dept_name return d_count; end --函数dept_count()可用在“返回教师数大于12的所有系的名称和预算”的查询中 select dept_name, budget from department where dept_count(dept_name)>12;
表函数(table functions):SQL标准支持的返回关系作为结果的函数。
e.g. 定义表函数返回一个包含特定系所有教师的表
/*注意:使用函数的参数时需加上函数名作为前缀(如instructor_of.dept_name)。*/ create function instructor_of (dept_name varchar(20)) returns table ( ID varchar(5), name varchar(20), dept_name varchar(20), salary numeric(8,2)) return table (select ID, name, dept_name, salary from instructor where instructor.dept_name = instructor_of.dept_name)l --函数instructor_of()可用在”返回金融系所有教师”的查询中 select * from table (instructor_of (‘Finance’));
SQL也支持定义过程,关键字in和out分别代表待赋值的参数和为返回结果而在过程中设置值的参数。
e.g. 定义过程dept_count_proc()
create procedure dept_count_proc(in dept_name varchar(20), out d_count integer) begin select count(*) into d_count from instrucot where instructor.dept_name = dept_count_proc.dept_name end --可从一个SQL过程中或从嵌入式SQL中使用call语句调用过程 declare d_count integer; call dept_count_proc(‘Physics’, d_count);
2. 支持过程和函数的语言构造
SQL标准中处理构造的部分称为持久存储模块(Persistent Storage Module, PSM)。注意:许多数据库并不严格遵照SQL定义的过程和函数的语法标准。
declare语句声明变量,可以使任意合法的SQL类型,set语句进行赋值。
一个复合语句在begin和end之间会包含复杂的SQL语句,可在复合语句中声明局部变量。形如begin atomic … end的符合语句可确保其中包含的所有语句作为单一事务来执行。
SQL:1999支持while语句和repeat语句:
while 布尔表达式 do 语句序列; end while repeat 语句序列; until 布尔表达式 end repeat
for循环允许对查询的所有结果重复执行:
/*程序每次获取查询结果的一行,并存入for循环变量(例中r)中。*/ declare n integer default 0; for r as select budget from department where dept_name = ‘Music’ do set n = n-r.budget end for
leave语句可用于退出循环,iterate表示跳过剩余语句从循环的开始进入下一个元组。
SQL支持if-then-else条件语句:
if 布尔表达式 then 语句或复合语句 elseif 布尔表达式 then 语句或复合语句 else 语句或符合语句 end if
SQL也支持case语句,类似C/C++中的case语句。
e.g. SQL过程结构化:学生注册课程的过程
/*在确保教室能容纳下的前提下注册一个学生 如果成功注册返回0,超过教室容量则返回-1 函数返回一个错误代码,>=0表示成功,负值表示出错,同时以out参数的形式返回消息说明失败原因。*/ create function registerStudent ( in s_id varchar(5), in s_courseid varchar(8), in s_secid varchar(8), in s_semester varchar(6), in s_year numeric(4, 0), out errorMsg varchar(100)) returns integer begin declare currEnrol int; select count(*) into curEnrol from takes where course_id = s_courseid and sec_id = s_secid and semester = s_semester and year = s_year; declare limit int; select capacity into limit from classroom natural join section where course_id = s_courseid and sec_id = s_secid and semester = s_semester and year = s_year; if (currEnrol < limit) begin insert into takes values (s_id, s_course_id, s_secid, s_semester, s_year, null); return (0); end --否则已达到课程容量上限 set errorMsg = ‘Enrollment limit reached for course ’ || s_courseid || ‘ section ’ || s_secid; return (-1); end;
SQL支持发信号通知异常条件(exception condition),以及声明句柄(handler)处理异常。除明确定义的条件,还有一些预定义条件,如sqlexception、squlwarning和notfound。E.g.
declare out_of_classroom_seats condition declare exit handler for out_of_classroom_seats begin /*begin和end之间的语句可以执行signal out_of_classroom_seats来引发一个异常。如果条件发生,将会采取动作终止begin end中的语句; Continue动作则将继续从引发异常语句的下一条语句开始执行。*/ sequence of statements end
3. 外部语言过程
可在一种命令式程序设计语言中定义过程,然后从SQL查询和触发器的定义中调用它。
可在一种程序设计语言中定义函数,效率高于SQL中定义的函数,执行一些无法在SQL中执行的计算。
外部过程和函数的指定:(确切语法依赖于所使用的特定数据库系统)
create procedure dept_count_proc (in dept_name varchar(20), out count integer) language C external name ‘/usr/avi/bin/dept_count_proc’ create function dept_count (dept_name varchar(20)) returns integer language C external name ‘/usr/avi/bin/dept_count’
外部语言过程通常需要处理参数和返回值中的空值,可通过额外参数指示(一个存储函数返回值的参数、一些指明每个参数/函数结果的值是否为空的指示器变量)。空值问题也可通过其他机制解决,如传递指针而不是值。具体采用哪种方法取决于数据库;
外部语言过程通常需要传递操作失败/成功的状态以便处理异常,可通过额外参数指示(一个指明失败/成功状态的sqlstate值);
如果一个函数不关注空值问题或操作失败/成功状态等情况,可在声明语句上方添加一行”parameter style general”指明外部过程/函数只是用说明的变量并且不处理空值和异常。
用程序设计语言定义并在数据库系统之外编译的函数可由数据库系统代码加载执行,具有较高的执行效率。但存在安全性问题:程序中的错误可能破坏数据库内部结构、绕过数据库系统的访问-控制功能;
关心安全性的数据库系统一般将这些代码作为单独进程的一部分来执行,通过进程间通信传入参数值、取回结果,但进程间通信的时间代价较高;
如果代码用”安全”语言(如Java或C#)书写,则可能在数据库进程本身的沙盒(sandbox)内执行代码。沙盒允许Java或C#代码访问其内存区域,但阻止代码直接在查询执行过程的内存汇总做任何读操作、更新操作或访问文件系统中的文件。避免进程间通信可大大降低函数调用的时间代价。
触发器
触发器(trigger):当对数据库作修改时被自动被系统执行的一条语句,定义了当某个事件发生而且满足相应条件时自动执行的动作。
要设置触发器机制必须满足两个要求:
·指明什么条件下执行触发器。被分解为一个引起触发器被检测的事件和一个触发器执行必须满足的条件。
·指明触发器执行时的动作。
一旦将一个触发器输入数据库,只要指定事件发生、相应条件满足,数据库系统就有责任区执行它。触发器机制可用于当满足特定条件时对用户发警报或自动开始执行某项任务,实现未被SQL约束机制指定的某些完整性约束。
触发器可应用于实现业务规则、审计日志、执行数据库系统外的操作等。
1. SQL中的触发器
e.g. 使用触发器确保关系section中属性time_slot_id的参照完整性(SQL标准定义,许多数据库实现的是非标准版本的语法。)
/*触发器1定义指明该触发器在任何一次对关系section的插入操作后被启动,确保所插入元组time_slot_id字段合法。*/ create trigger timeslot_check1 after insert on section /*referencing new row as语句建立了一个过渡变量(transition variable)nrow,用于在插入完成后存储所插入行的值。*/ referencing new row as nrow /*一个SQL插入语句可向关系插入多个元组,触发器代码中的for each row语句可显式在每个被插入的行上进行迭代。*/ for each row /*when语句指定一个条件,仅对满足条件的元组才执行触发器中的其余部分。*/ when (nrow.time_slot_id not in ( select time_slot_id from time_slot)) /*time_slot中不存在time_slot_id*/ /*begin atomic … end语句用于将多行SQL语句集成为一个符合语句。*/ begin rollback --对引起触发器被执行的事务进行回滚 /*所有违背完整性约束的事务都将被回滚,从而确保数据库中的数据满足约束条件。*/ end; /*触发器2检查time_slot表中被删除元组的time_slot_id要么还在time_slot中,要么section里不存在包含这个time_slot_id值的元组,否则将违背参照完整性。*/ create trigger timeslot_check2 after delete on time referencing old row as orow for each row when (orow.time_slot_id not in ( select time_slot_id from time_slot) /*在time_slot中刚刚被删除的time_slot_id*/ and orow.time_slot_id in ( select time_slot_id from section)) /*在section中仍含有该time_slot_id的引用*/ begin rollback end;
使用after update of …(relation) on …(column)子句,触发器可以指定哪个属性的更新使其执行(而其他属性的更新不会让它产生动作)。Referencing old row as子句可建立一个变量用于存储已经更新或删除行的旧值,refercing new row as子句也可用于更新操作。
e.g. 指定当关系takes的属性grade从空值或’F’被更新为代表课程已经完成的具体分数时才激发触发器,维护student里元组的tot_cred属性保持实时更新。
create trigger credits_earned after update of takes on (grade) referencing new row as nrow referencing old row as orow for each row when nrow.grade <> ‘F’ and nrow.grade is not null and (orow.grade = ‘F’ or orow.grade is null) begin atomic update student set tot_cred = tot_cred + (select credits from course where course.course_id = nrow.course_id) where student.id = nrow.id; end;
触发器也可以在事件之前激发,作为避免非法更新、插入或删除的额外约束。
触发器可采取措施来纠正问题,使更新、插入或删除操作合法化。 e.g. 假设所插入分数的值为空白则表明该分数发生缺失,可定义触发器用set语句执行修改,将这个值用null值代替。
create trigger setnull before update of takes referencing new row as nrow for each row when (nrow.grade = ‘ ’) begin atomic set nrow.grade = null; end;
可使用for each statement子句代替for each row子句,对引起插入、删除或更新的SQL语句执行单一动作,而不是对每个被影响的行执行一个动作。
过渡表(transition table):可用referencing old table as子句或referencing new table as子句指向包含所有被影响的行的临时表。过渡表不能用于before触发器,但可以用于after触发器(无论是语句触发器还是行触发器)。在过渡表的基础上,一个单独的SQL语句可用于执行多个动作。
触发器可被设为有效或无效(默认情况下有效)。可通过alter trigger trigger_name disable(某些数据库使用另一种语法如disable trigger trigger_name)将其设为无效,也可重新设为有效。通过命令drop trigger trigger_name可丢弃(永久移除)触发器。
2. 何时不用触发器
避免使用触发器替代级联特性来实现外码约束的on delete cascade特性,因为需要更大的工作量,而且使数据库中实现的约束集合对数据库用户来说更难以理解;
避免使用触发器来维护物化视图,因为许多数据库现在支持物化视图并由数据库系统自动维护;
避免使用触发器用于复制或备份数据库,因为现代数据库系统提供内置的数据库复制工具;
当从备份拷贝中加载数据、或将数据库更新复制到备份站点时,可能会导致触发器动作的非故意执行。应当将备份复制系统的触发器显式设为无效,在备份站点接管主系统业务后再设为有效。(一些数据库系统可将触发器定义为not for replication,保证触发器不会再数据备份时在备份站点执行;或提供系统变量用于指明该数据库是一个副本,触发器检查该变量为真则退出执行。)
一个触发器的动作可能引发另一个触发器,甚至可能导致一个无限的触发链。有些数据库系统会限制触发器链的长度,把超过此长度的触发器链看作错误;或把引用特定关系的触发器标记为错误,对该关系的修改导致了位于链首的触发器被执行。
递归查询
传递闭包等查询的计算可用迭代或递归SQL查询表示。
1. 用迭代计算传递闭包
e.g. 使用迭代,首先找到CS-347的直接先修课程,再找到第一个集合中所有课程的先修课程,持续迭代直到某次循环中没有新课程加进来。
/*关系prereq(course_id,prereq_id)指明哪一门课程是另一门课的直接先修课程。函数findAllPrereqs以课程的couse_id为参数(cid),找出该cid课程的所有(直接或间接)先修课程并返回集合。*/ create function findAllPrereqs(cid varchar(8)) returns table (course_id varchar(8)) begin /*用到三个临时表: 表c_prereq存储要返回的课程元组集合; 表new_c_prereq存储前一次迭代中发现的课程; 表temp用于对课程集合进行操作时临时存储中间结果。 Create temporary table创建临时表,临时表仅在执行查询的事务内部可用,并随事务的完成而被删除。*/ create temporary table c_prereq ( course_id varchar(8) ); create temporary table new_c_prereq ( course_id varchar(8) ); create temporary talbe temp ( course_id varchar(8) ); --repeat循环前先将课程cid的所有直接先修课程插入new_c_prereq insert into new_c_prereq select prereq_id from prereq where course_id = cid; repeat --把new_c_prereq中所有课程加入c_prereq中 insert into c_prereq select course_id from new_c_prereq; /* 从结果中筛选掉此前已经计算出是cid先修课程的课程,把剩下的存放在临时表temp中。*/ insert into temp ( select prereq.course_id from new_c_prereq, prereq where new_c_prereq.course_id = prereq.prereq_id ) --except子句保证即使先修关系中存在环时函数也能正常工作 except ( select course_id from c_prereq ); --将new_c_prereq中的内容替换成temp中的内容 delete from new_c_prereq; insert into new_c_prereq select * from temp; delete from temp; --当找不到新的(间接)先修课程时repeat循环终止。 until not exists (select * from new_c_prereq) end repeat; return table c_prereq; end
2. SQL中的递归查询:用递归视图定义计算传递闭包
递归可用递归视图或递归的with子句定义。
with recursive子句支持有限形式的递归,在递归中一个视图(或临时视图)用自身来表达自身。
e.g. 使用递归视图找到所有(cid,pre),其中pre是cid的直接或间接先修课程。
/*首先计算基查询,所有结果元组添加到初始为空的视图关系rec_prereq中。 然后用当前视图关系的内容计算递归查询,并把所有结果元组加回到视图关系中。持续重复上述步骤直至没有新的元组添加到视图关系中位置。 得到的视图关系实例称为递归视图定义的一个不动点(fixed point)。*/ with recursive rec_prereq(course_id, prereq_id) as ( select course_id, prereq_id from prereq union select rec_prereq.course_id, prereq.prereq_id from prereq, rec_prereq where prereq.course_id = rec_prereq.prereq_id ) select * from rec_prereq;
递归视图中的递归查询必须是单调的(monotonic)--如果视图关系实例V1是实例V2的超集,那么它在V1上的结果必须是它在V2上结果的超集。
直观上,如果更多的元组被添加到视图关系,则递归查询至少应返回与以前相同的元组集,并且可能返回另外一些元组。
递归查询不能用于任何下列构造(因为它们会导致查询非单调):
·递归视图上的聚集;
·在使用递归视图的子查询上的not exists语句;
·右端使用递归视图的集合差(except)运算。
SQL允许使用create recursive view子句代替with recursive来创建递归定义的永久视图。
高级聚集特性
SQL支持一些高级的聚集特性,如排名和分床查询。这些特性简化了一些聚集操作的表达方式,并提供了更高效的求值方法。
1. 排名
排名可从一个大的集合中找出某值的位置。
e.g. 假设视图student_grades(ID, GPA)给出每个学生的平均绩点,查询每个学生的排名
select ID, rank() over (order by (GPA) desc) as s_rank from student_grades; --也可使用order by子句得到排序的元组 select ID, rank() over (order by (GPA) desc) as s_rank from student_grades order by s_rank;
排名可在数据的不同分区进行。
e.g. 假设视图dept_grades(ID, dept_name, GPA),查询学生们在每个分区(系)里的排名
select ID, dept_name, rank () over (partition by dept_name order by GPA desc) as dept_rank from dept_grades order by dept_name, dept_rank; --将结果元组按系名排序,在各系内按照名次排序
一个单独的select语句可使用多个rank表达式。通过在同一个select语句中使用两个rank表达式,可得到总排名以及分区内的排名。
当排名(可能带有分区)与group by子句同时出现时,首先执行group by子句,分区和排名在group by的结果上执行。(因此得到聚集值之后可用于排名)。
将排名查询嵌入外层查询,可将排名函数用于找出排名最高/最低的n个元组。有些数据库系统提供非标准SQL扩展直接指定只需要得到前n个结果(不需要rank函数,简化了优化器的工作)。如:一些数据库允许在SQL查询后面添加limit n子句用于知名只输出前n个元组,与order by子句连用可获取排名最高的n个元组。
e.g. 以GPA大小顺序获取前10个学生的ID和GPA
select ID, GPA from student_grades order by GPA limit 10;
缺点:limit子句不支持分区;如果多个元组拥有相同的排名指定属性值,可能有的元组不能被包括进结果中。
rank函数对所有在order by属性上相等的元组赋予相同的排名,一个元组的排名就是那些比它排名靠前的元组数目再加1。(e.g. 1, 1, 3, 3, 3, 6)
dense_rank函数则不在等级排序中产生隔断。(e.g. 1, 1, 2, 2, 2, 3)
percent_rank函数以分数形式给出元组的排名。如果某个分区(或整个集合)中有n个元组且某个元组排名为r,则该元组的百分比排名定义为(r-1)/(n-1)(如果该分区中只有一个元组则定义为null)。
cume_dist(积累分布)函数对一个元组定义为p/n,p是分区中排序值小于或等于该元组排序值的元组数,n是分区中的元组数。
row_number函数对行进行行排序,按行在排序顺序中所处位置给每行一个唯一行号,具有相同排序值的不同行将按照非确定的方式得到不同的行号。
ntile(n)函数对于一个给定常数n按照给定顺序取得每个分区中的元组,并把它们分成n个具有相同元组数目的桶(如果一个分区中所有元组的数量不能被n整除,则每个桶中元组数最多相差1,具有同样排序属性值的元组可能不确定地赋予不同的桶)。对每个元组,ntile(n)给出它所在的桶号(从1开始计数)。【可用于构造基于百分比的直方图】
e.g. 根据GPA把学生分为4个等级
select ID, ntile(4) over ( order by (GPA desc) ) as quartile from student_grades;
SQL允许用户使用null first或null last指定空值在排序中出现的位置。
e.g.
select ID, rank() over ( order by GPA desc nulls last ) as s_rank from student_grades;
2. 分窗
窗口:窗口查询用于对一定范围内的元组计算聚集函数,如计算一个固定时间区间内的聚集值,这个时间区间称为一个窗口。
窗口可以重叠,一个元组可能对多个窗口都有贡献,而一个元组只对一个分区有贡献。
e.g. 假设有视图tot_credits(year, num_credits)记录每年学生选课总学分(此关系中对于每个年份最多有一个元组)。
查询计算指定顺序下的前三个元组的均值
select year, avg(num_credits) over (order by year rows 3 preceding) as avg_total_credits from tot_credits; /*对于2009年,如果关系tot_credits中含有2008年和2007年分别唯一对应的元组,结果是2007、2008、2009年的平均值,以此类推; 对于关系tot_credits中最早的一年,结果为该年本身; 对于关系tot_credits中的第二年,结果为前两年平均值。*/
e.g. 查询前面所有年份的平均总学分(回溯元组数量并不恒定)
select year, avg(num_credits) over (order by year rows unbounded preceding) as avg_total_credits from tot_credits;
可用关键字following替换preceding,则order by后属性值(例中year值)表示起始而不是结束。
e.g. 指定窗口在当前元组之前开始、之后结束
select yaer, avg(num_credits) over (order by year rows between 3 preceding and 2 following) as avg_total_credits from tot_credits;
使用关键字range可用order by后属性值的范围(而不是行的数目)来指定窗口。注意:使用关键字range可返回范围内(包括边界)的所有数据,不管范围内实际有多少元组。
e.g. 指定窗口“包含当前年以及前面4年的范围”
select year, avg(num_credits) over (order by year range between year-4 and year) as avg_total_credits from tot_credits;
e.g. 视图tot_credits_dept(dept_name, year, num_credits)记录学生在指定年份汇总选某个系开设的课程的所有学分数。
编写分窗查询,按照dept_name分区对每个系分别计算
select dept_name, year, avg(num_credits) over (partition by dept_name order by year rows between 3 preceding and current row) as avg_total_credits from tot_credits_dept;
OLAP
OLAP(联机分析处理)系统:允许分析人员查看多为数据的不同种类的汇总数据的一个交互式系统。分析人员能够提出新的汇总数据请求并在线得到相应。SQL支持OLAP的扩展。
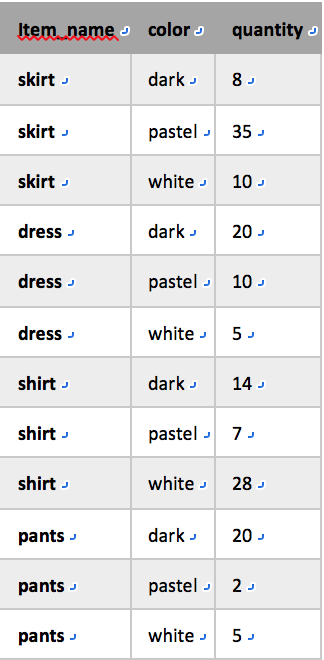
e.g. 一个关系sales,模式为sales(item_name, color, clothes_size, quantity)
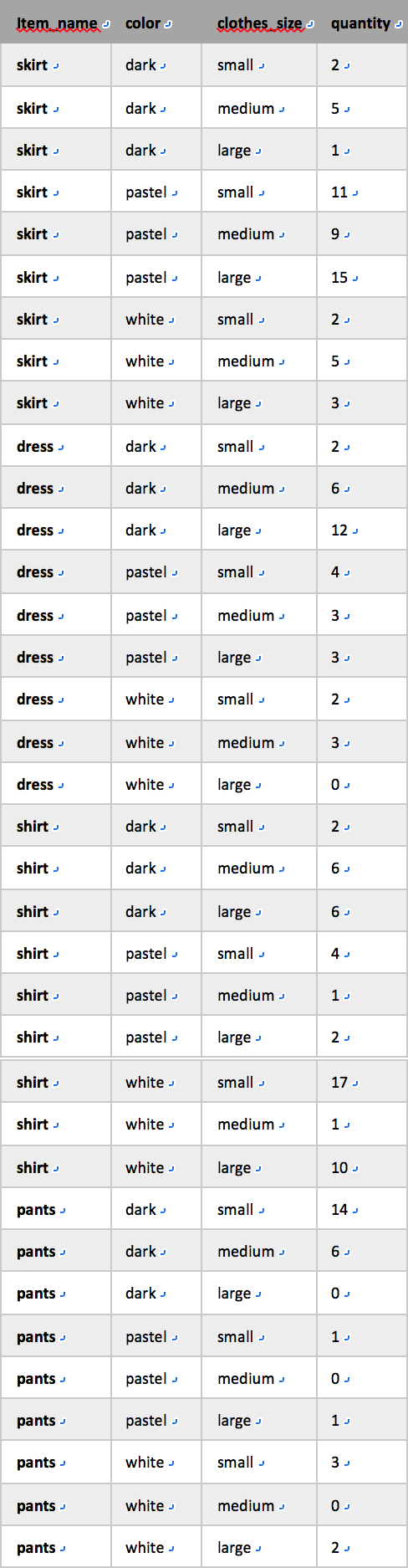
给出一个用于数据分析的关系,可将它的某些属性看作度量属性(measuare attribute),这些属性度量了某个值,可以在其上进行聚集操作。E.g. 关系sales的属性quantity,度量卖出商品的数量。关系的某些属性可看作维属性(dimension attribute),这些属性定义了度量属性以及度量属性的汇总可以在其上进行观察的各个维度。E.g. 关系sales的属性item_name、color和clothes_size。
多维属性(multidimensional data):能够模式化为维属性和度量属性的数据的统称。
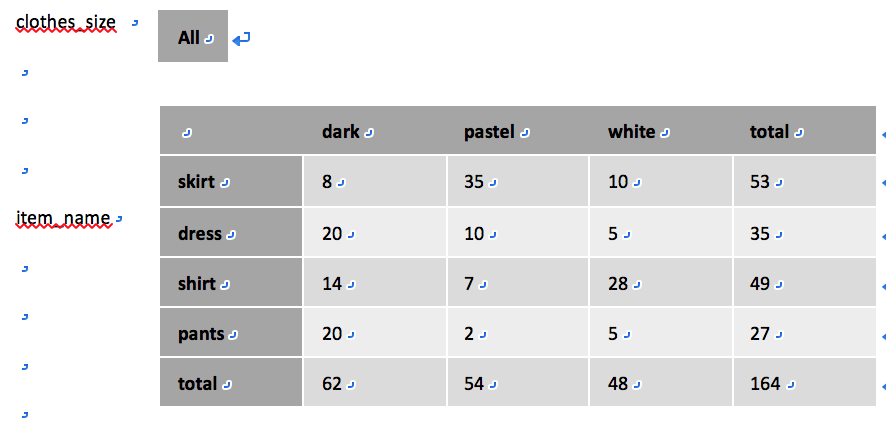
交叉表(cross-tabulation或cross-tab)/转轴表(pivot-table):一个交叉表示从一个关系R中导出,由关系R的一个属性A的值构成其行表头,关系R的另一个属性B的值构成其列表头。大多数交叉表中海另有一列汇总列和一行会汇总行,用于存储一行/列中所有单元的总和。
每个单元记为(ai, bj),ai代表A的一个取值,bj代表B的一个取值。
转轴中不同单元(ai, bj)的值从关系R中推导,可由元组的一个或多个其他属性值或由元组上的聚集得到。
e.g. 显示属性Item_name和color值之间不同组合情况下的商品数目
数据立方体(data cube):将二维的交叉表推广到n维,可视作一个n维立方体。所有单元都包含一个值。某一维的取值可以使all,该单元包含该维上所有值的汇总数据。
对于一个n维的表,可在其n个维的2n个子集上进行分组并执行聚集操作。
e.g. 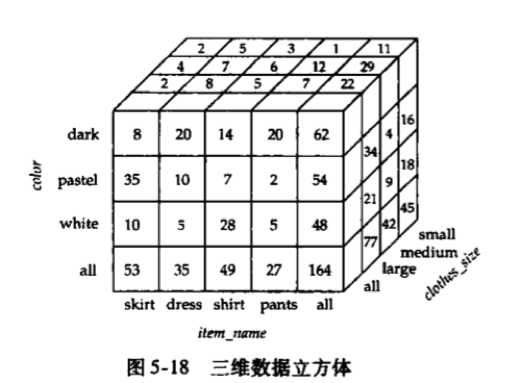
OLAP系统中数据分析人员可以交互地选择交叉表的属性从而在相同的数据上查看不同内容的交叉表,每个交叉表是一个多维数据立方体上的二维视图。改变交叉表中的维的操作称为转轴(pivoting)。
切片(slicing):OLAP系统允许分析人员对于一个固定的维属性的值查看在另外两个维属性上的交叉表(e.g. 例中对于固定的clothes_size值large,而不是所有size的总和,查看一个在item_name和color上的交叉表),可看做查看数据立方体的某一片。当有多个维的值固定时也可称作切块(dicing)。
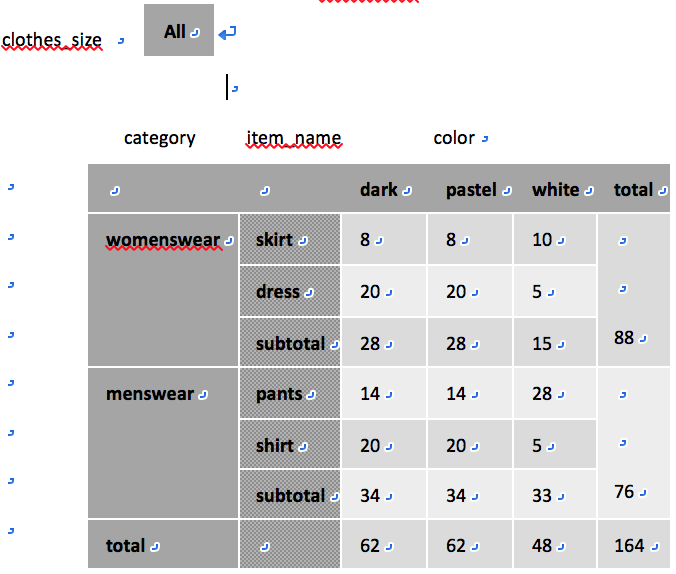
当一个交叉表用于观察一个数据立方体时,不属于交叉表部分的维属性的值显示在交叉表的上方。切片/切块仅由这些属性所选的特定值构成。E.g. 例中clothe_size: all表明交叉表中的数据是该属性所有值的汇总(所用聚集是所有不同clothes_zie上的quantity属性之和)。
OLAP系统允许用户按照期望的粒度级别观察数据。
上卷(rollup):(通过聚集)从较细粒度数据转到较粗粒度的操作。E.g. 例中从表sales上的数据立方体出发,在属性clothes_size上执行上卷操作得到交叉表。
下钻(drill down):将较粗粒度数据转化为较细粒度数据。注意:较细粒度数据不可能由较粗粒度数据产生,必须由原始数据或更细粒度的汇总数据产生。
一个属性的不同细节层次可组织成一个层次结构(hierarchy)。分层可允许分析人员根据需要沿层次下钻或沿层次上卷。
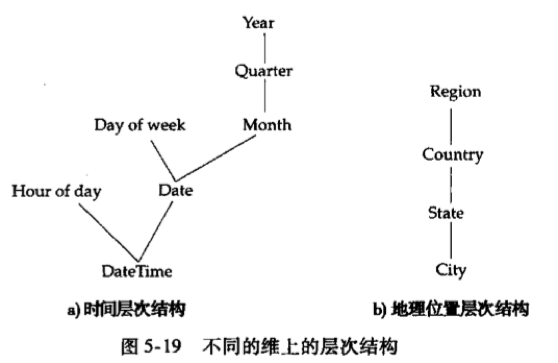
交叉表与关系表
使用关系表示交叉表:不同于关系表,交叉表中列的数目依赖于实际的数据。对于没有汇总值的交叉表,可以把它直接表示为具有固定列数的关系形式;对于有汇总行/列的交叉表,可引入一个特殊值all表示子汇总值。
e.g.
消除在列color和clothes_size上具有不同值的各个元组,将quantity的值替换成在列item_name上进行group by后进行聚集得到值(数量和)得到元组(skirt, all, all, 53)和(dress, all, all, 35);
类似,在color、clothes_size上进行group by可用于得到在item_name上取all值的元组;
不带任何属性的group by可用于得到在item_name、color和clothes_size上都取all值的元组。
交叉表:
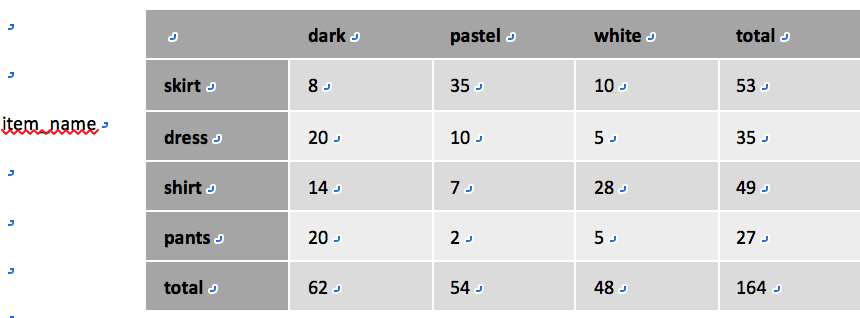
交叉表的数据表达:
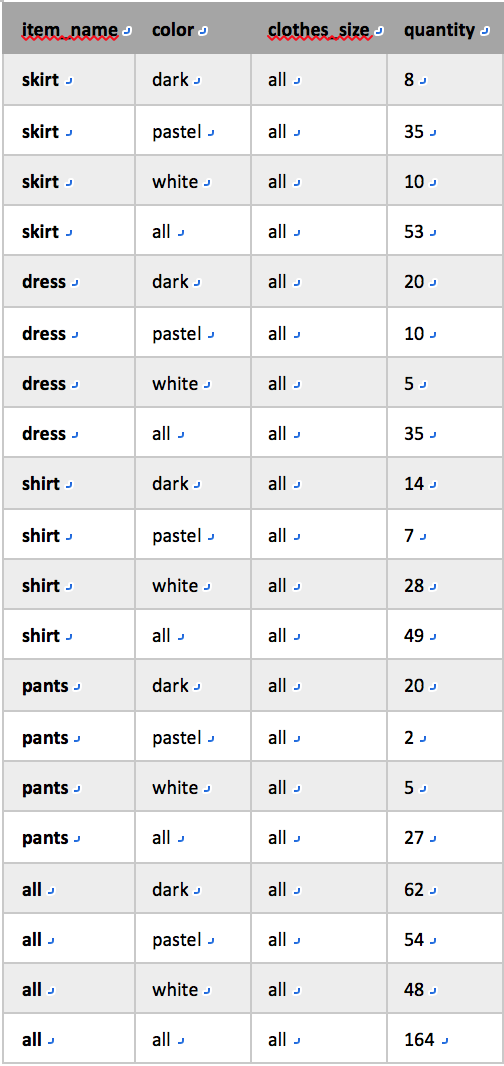
使用关系表示层次结构:
e.g. 可使用itemcategory(item_name, category)表示关系sales的层次结构,将该关系与关系sales连接可得到一个包含各个商品所属类别的关系。在该连接关系上进行聚集操作,可得到带有层次结构的交叉表。
e.g. 城市的层次结构可用单个关系city_hierarchy(ID, city, state, country, region)表示。也可用多个关系,每隔关系把结构中某层的值映射到下一层。
SQL中的OLAP
有些SQL实现支持在SQL中使用pivot子句创建交叉表。
e.g.
select * from sales pivot ( sum (quantity) for color in (‘dark’, ‘pastel’, ‘white’) ) order by item_name; /*pivot子句中for子句指定属性color的哪些值应该在转轴的结果汇总作为属性名出现,属性color本身从结果中被去除,关系sales的其他所有属性则都被保留。 在多个元组对给定单元有贡献的情况下,pivot子句中的聚集操作指定把这些值汇总的办法。(例中对quantity值求和)*/
单个SQL查询使用基本的group by结构不能生成数据立方体中的数据,所以SQL包含一些函数用来生成OLAP所需的分组。
SQL支持group by结构的泛化形式,group by子句中的cube和rollup结构允许在单个查询中运行多个group by查询,结果以单个关系的形式返回。
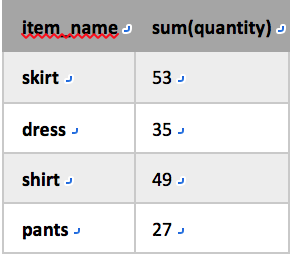
e.g. 针对关系sales编写group by查询找出每个商品名item_name所对应的销售量sum(quantity)
select item_name, sum(quantity) from sales group by item_name;
查询结果:
e.g. 针对关系sales编写group by查询找出每个商品名item_name和颜色color对应的销售量sum(quantity)
select item_name, color, sum(quantity) from sales group by item_name, color;
查询结果:
如果想以此方式生成整个数据立方体,则必须为{ (item_name, color, clothes_size), (item_name, color), (item_name, clothes_size), (color, clothes_size), (item_name), (color), (clothes_size), () }中的每个属集写一个独立查询。
可使用cube结构完成,产生全部8种实现group by查询的方法。
select item_name, color, clothes_size, sum(quantity) from sales group by cube (item_name, color, clothes_size);
查询结果为模式为(item_name, color, clothe_size, sum(quantity))的关系。对于特定分组中不出现的属性,结果元组中其值为null。如:
在clothes_size上进行分组所产生的元组模式为(clothes_size, sum(quantity)),通过在属性item_name和color上加入null,转换为模式为(item_name, color, clothes_size, sum(quantity))的元组。
rollup结构与cube结构基本一样,产生的group by查询较少。rollup中属性按照顺序不同有所区分,最后一个属性只在一个分组中出现,倒数第二个属性出现在两个分组中,以此类推第一个属性出现在除空分组外的所有分组中。
e.g. group by rollup(item_name, color, clothes_size)只产生{ (item_name, color, clothes_size), (item_name, color), (item_name), () } 4个分组。
对于层次结构,rollup结构便于为求更深的细节而设定下钻序列。
e.g. 层次结构(Region, Country, State, City)可用rollup结构设定分组(Region), (Region, Country), (Region, Country, State)和(Region, Country, State, City)。
多个rollup和cube可在一个单独的group by子句中使用。
e.g.
select item_name, color, clothes_size, sum(quantity) from sales group by rollup(item_name), rollup(color, clothes_size); /* rollup(item_name)产生2个分组:{ (item_name), () }; rollup(color, clothes_size)产生3个分组:{ (color, clothes_size), (color), () }; 以上两部分笛卡尔积得到该查询产生6个分组:{ (item_name, color, clothes_size), (item_name, color), (item_name), (color, clothes_size), (color), () }。*/
rollup和cube子句都不能完全控制分组的产生(指定只生成某些分组),可在having子句中使用grouping结构来产生限制条件的分组。
使用SQL的decode和grouping函数可将null替换为all,使关系更容易被一般用户读懂。
e.g.
/*grouping函数当参数是cube或roll up产生的null值时返回1,否则返回0。 Decode函数将值value(例中grouping结果)与匹配值match(例中1)进行比较,如果发现匹配就把属性值用相应替代值replacement(例中‘all’)替换。如果未匹配成功则替换为默认的替代值default-replacement(例中item_name)。*/ select decode(grouping(item_name), 1, ‘all’, item_name) as item_name decode(grouping(color), 1, ‘all’, color) as color sum(quantity) as quantity from sales group by cube(item_name, color);
OLAP工具帮助分析人员用不同的方式查看汇总数据,使他们能够洞察一个组织的运行。
1. OLAP工具在以维属性和度量属性为特性的多维数据之上。
2. 数据立方体由不同方式汇总的多维数据构成。预先计算数据立方体有助于提高汇总数据的查询速度。
3. 交叉表的显示允许用户一次查看多维数据的两个维及其汇总数据。
4. 下钻、上卷、切片和切块是用户使用OLAP工具时执行的一些操作。
从SQL: 1999标准开始,SQL提供一系列用于数据分析的操作符,其中包括cube和rollup操作。有些系统还支持pivot子句,方便生成交叉表。