执行引擎:JVM运行Java程序的一套子系统。
如何理解Java是半编译半解释型语言?
1. javac编译,java执行;
2. 字节码解释器解释执行,模板解释器编译执行。
两种解释器 -- a) 字节码解释器; b) 模板解释器
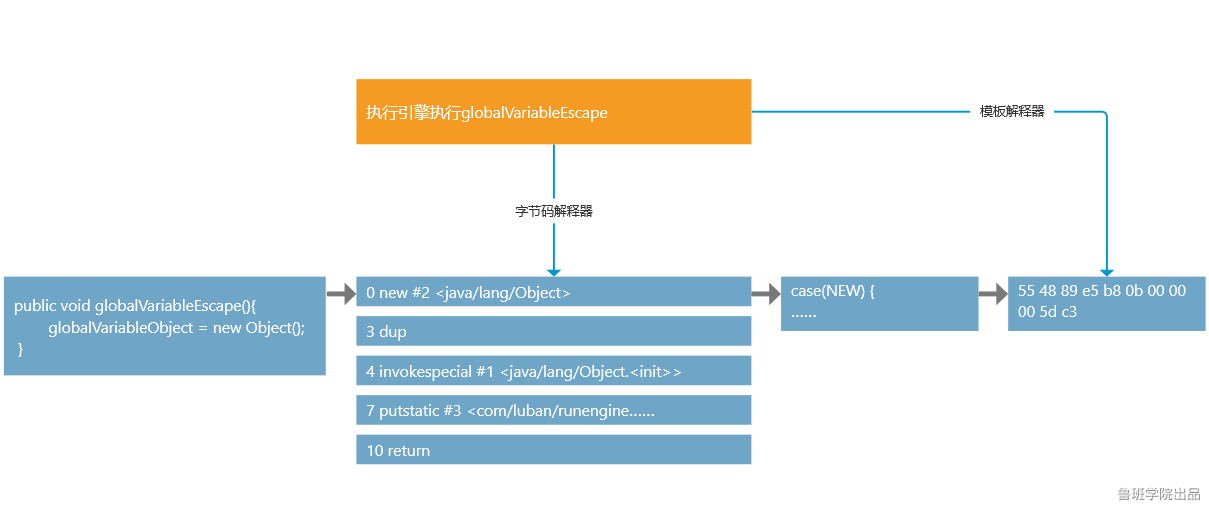
字节码解释器:将Java字节码解释称C++代码(java代码->java字节码->C++代码),再编译成底层的硬编码给CPU执行。性能较低,早期JDK只有字节码解释器。(解释执行,跟即时编译器无关)
字节码解释器的通用结构:
在循环中先取每个字节码指令的code,switch case判断,解释成对应的C++代码执行。
while (true) { //或for循环 char code = … switch (code) { case NEW: … break; case DUP: … break; … } }
模板解释器:(触发即时编译)将Java字节码直接编译成硬编码。是JIT的一部分。
-- 模板解释器下次执行时不会再做字节码解释器的解释过程,直接执行(即时编译器编译好的)硬编码。(所以运行效率比字节码解释器高)
模板解释器的底层实现
1) 申请一块(可读可写可执行的)内存;//JIT在Mac上无法运行,因为Mac出于安全性禁止了申请可执行的内存块的API。
2) (参照字节码解释器,)将处理该部分(new方法)字节码的硬编码拿过来
3) 将硬编码写入申请的内存
4) 申请一个函数指针,指向这块内存
5) 调用时,直接通过函数指针调用
e.g.参照new()中的字节码解释器逻辑,在 template_new()中模拟模板解释器的底层实现:
#include<stdio.h> #include <sys/mman.h> #include <unistd.h> #include <memory.h> int new() { //字节码解释器执行new指令的逻辑,这里简化 //execute_new(method_code, method_code->get_current_code_short()); //method_code->inc_code_pointer(sizeof(short)); return 11; } int template new() { //函数指针 typedef int (*p_fun)(); //处理new方法字节码的硬编码,放在局部变量里 char code[] = { 0x55, //pushq $rbp 0x48, 0x89, 0xe5, //movq %rsp, %rbp 0xb8, 0x8b, 8x80, 8x80, 0x00, //movl $0xb, %eax 0x5d, //popq %rbp 0xc3 //retq }; //创建一块可读可写可执行的内存区域 void *temp = mmap ( NULL, //映射区的开始地址,设置为NULL或0表示由系统决定 getpagesize(), //申请的内存大小按内存页对齐,这里直接调用函数获取内存页大小 PROT_READ | PROT_WRITE | PROT_EXEC, //映射内存区的权限,可读可写可执行 MAP_ANONYMOUS | MAP_PRIVATE, //映射对象的类型 -1, //fd 0, //offset ); //将new()的机器码写入内存 memcpy(temp, code, sizeof(code)); //函数指针指向所申请内存区域 p_fun fun=temp; //通过函数指针调用 return fun(); }
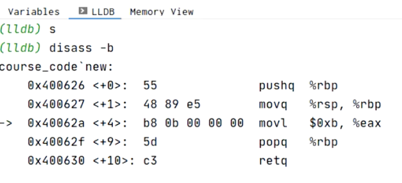
实验1:调试器可查看底层汇编 --(2)中的硬编码是怎么拿到的
int main() { //可正常运行,template_new()能返回和new()一样的结果(11)。 int obj = new(); int obj2 = template_new(); }
-> idea -> lldb,在int obj=new()设置断点,右键debug,输入s开始单步调试;
-> 输入disass –b查看底层汇编。’->’标记现在执行到的位置。
运行模式
根据底层使用不同的解释器,JVM有3种运行模式:
1) –Xint 纯字节码解释器
2) –Xcomp 纯模板解释器
3) –Xmixed 字节码解释器+模板解释器 (JVM默认模式)
命令java –version显示运行模式。E.g.
 //混合模式
//混合模式
 //解释器模式
//解释器模式
 //编译模式
//编译模式
为什么JVM默认采用-Xmixed模式而不是-Xcomp?
- 纯模板解释器模式会先将程序全部编译生成硬编码再运行。如果程序比较大,初次运行时会需要很长时间编译;
- 混合模式会随着程序运行收集数据来做更深层次的优化。
性能比较: -Xmixed ≈ -Xcomp > -Xint
-Xmixed和-Xcomp的性能比较与具体程序大小有关。
因为纯模板解释解释器-Xcomp是将全部代码编译以后才执行。
-> 如果程序很小,-Xcomp性能较高,因为初期编译时间短;
-> 如果程序较大,-Xmixed性能较高,因为可以马上执行程序,运行一段时间以后触发即时编译后再将热点代码缓存起来。
即时编译 – JIT(just-in-time compilation),即时编译器生成热点代码供模板解释器运行。
现在有4种即时编译器:C1、C2、混合编译、GraalVM(jdk14后)。
1) C1编译器: client模式下的即时编译器。
* 可通过命令java –version查看当前jvm处于client还是server模式。64位机只有server模式。32位机可通过java –client –version指定为client模式。
- 触发条件相对C2较宽松 -- 需要收集的数据较少;
- 编译优化较浅 e.g. 基本运算在编译时运算掉;
- 生成的代码执行效率较C2低。
2) C2编译器: server模式下的即时编译器。
- 触发条件较严格 -- 一般来说程序运行了一段时间后才会触发;
- 优化比较深 e.g. 会分析程序中有无堆栈操作,将不需要的堆栈操作优化掉;
- 生成的代码执行效率较C1高。
C2编译优化e.g. 删去多余堆栈操作编码,程序也能正常运行。
int new() { //execute_new(method_code, method_code->get_current_code_short()); //method_code->inc_code_pointer(sizeof(short)); return 11; //函数返回值会给eax寄存器 } int template new() { … //编译优化:发现不需要除eax外另外三句堆栈操作指令,可以删掉。 char code[] = { // 0x55, //pushq $rbp // 0x48, 0x89, 0xe5, //movq %rsp, %rbp 0xb8, 0x8b, 8x80, 8x80, 0x00, //movl $0xb, %eax // 0x5d, //popq %rbp // 0xc3 //retq };
3) 混合编译: 程序运行初期触发C1编译器,运行一段时间后触发C2编译器。
即时编译的触发条件
即时编译的最小单位是代码块(e.g. for/while循环),最大单位是方法。
-> 底层判断循环/方法执行次数达到N次就会触发即时编译
Client模式下,N默认值为1500;
Server模式下,N默认值为10000.
命令 java –XX:+PrintFlagsFinal –version | grep CompileThreshold 可查看触发条件CompileThreshold的N值。E.g.

热度衰减:已执行过若干次数过后如果有一段时间没有执行,已执行次数会倍速减少,未来要达到即时编译条件需要更多执行次数。E.g. 某方法已被调用7000次,本应再调用3001次就会触发即时编译,但没调用后次数会两倍速,减少到3500次时要达到触发条件需要再执行6501次。
e.g. 阿里早年的一个故障:热机且冷机故障
因为业务增加需要在集群里加节点(用于均衡负载),涉及到热机切换冷机。出现问题:将流量/压力切换到冷机上时冷机马上挂掉。
*冷机:刚运行程序不久; 热机:运行程序有一段时间。
*热点代码:编译好的硬编码。(从机器的角度叫硬编码,在JVM中称为热点代码。)
原因:1) 热机上有热点代码缓存,扛的并发更大。马上切换到冷机上时,冷机上没有热点代码缓存,并发达不到;2) 冷机上程序一边在运行一边在触发即时编译,CPU扛不住。
解决方案:先切少量流量到冷机上,等冷机上程序运行一段时间触发即时编译,再逐渐切换流量。
热点代码缓存区
Codecache,存放即时编译生成的热点代码,位于方法区(所以基本不会出现OOM)。
源码 /openjdk/hotspot/src/share/vm/code/codeCache.hpp
命令 java –XX:+PrintFlagsFinal –version | grep CodeCache 查看热点代码缓存区大小。
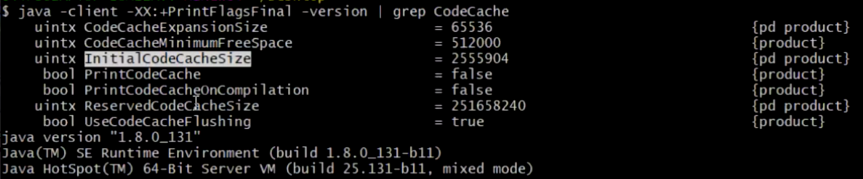
initialCodeCacheSize: 初始大小
ReservedCodeCacheSize: 最大大小
热点代码缓存区的初始/最大大小也是需要调优的地方。(调优参数:initialCodeCacheSize和ReservedCodeCacheSize,调优时一般调为一样大。)
Server编译器模式下热点代码缓存大小起始于2496KB,Client编译器模式下热点代码缓存大小起始于160KB。
对于较长时间没被调用的热点代码,Codecache会按照LRU自动清理。
执行即时编译的线程有多少,如何调优?
-> 命令java –XX:+PrintFlagsFinal –version | grep CICompilerCount查看CICompilerCount为即时编译线程数量。

-> 可通过参数–XX:CICompilerCount=N调优。
即时编译器是如何运行的 -- 类似队列
JVM中很多系统性的操作(e.g. GC,即时编译)都是通过VM_THREAD(JVM的系统线程)触发的。
当某个代码块执行N次达到触发即时编译的条件时会经历以下步骤:
-> 执行引擎将这个即时编译任务写入队列QUEUE;
-> VM_THREAD从这个队列中读取任务execution并运行;(所以即时编译是异步的)
(System.gc的调用同理)
逃逸分析 -- 逃逸是一种现象,分析是一种技术手段。
逃逸:如果对象的作用域是局部的(i.e.仅创建线程可见)则不是逃逸,其它(i.e. 外部线程可见)都是逃逸。E.g. 共享变量、返回值、参数、static变量
-- 可理解为逃逸到方法外/线程外。
e.g.
public class EscapeAnalysis { public static Object globalVariableObject; public Object instanceObject; public void globalVariableEscape() { globalVariableObject = new Object(); } // 静态变量,逃逸 public void instanceObjectEscape() { instanceObject = new Object(); } // 共享变量,逃逸 public Object returnObjectEscape() { return new Object(); } // 返回值,逃逸 public void noEscape1() { synchronized(new Object()) { //不是逃逸 System.out.println(“hello”); } } public void noEscape2() { Object noEscape = new Object(); } //局部变量,不是逃逸 public static void main(String[] args) { EscapeAnalysis analysis = new EscapeAnalysis(); … } }
基于逃逸分析JVM开发了三种优化技术:栈上分配、标量替换、锁消除
为什么基于逃逸分析开发了这些优化技术?
-- 如果对象发生了逃逸,情况就会变得非常复杂(外部可能对该对象进行改变、重新赋值等),优化无法实施。所以这些优化措施都是在逃逸分析的基础(确定对象没有发生逃逸)上进行的。
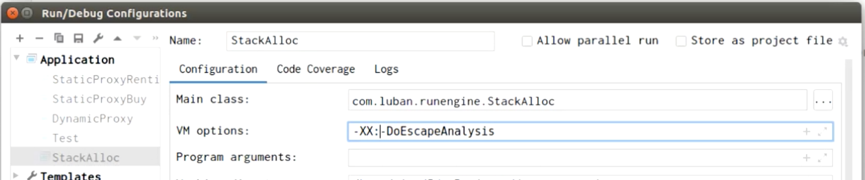
逃逸分析默认是开启的。 调节参数:-XX:+/-DoEscapeAnalysis
-> IDEA右上角 Edit Configuration

-> VM options中填写参数
标量替换
标量:不可再分 e.g. java中的基本数据类型
聚合量:可再分 e.g. 对象
e.g.
/* Position中的xyz为标量,在外部不会被修改。position对象没有发生逃逸。 JVM逃逸分析后会将test()中的标量position.x, position.y, position.z直接替换为1、2、3,提高程序效率。 */ public class ScalarReplace { … public static void test() { Position position = new Position(1, 2, 3); System.out.println(position.x); //标量替换后:System.out.println(1); System.out.println(position.y); //标量替换后:System.out.println(2); System.out.println(position.z); //标量替换后:System.out.println(3); } class Position { int x; int y; int z; public Position(int x, int y, int z) { this.x = x; this.y = y; this.z = z; } } }
锁消除: 逃逸分析发现上锁的对象为局部变量,将锁消除来优化。
e.g.
public void noEscape1() { synchronized (new Object()) { System.out.println(“hello”); } } //----优化后---- public void noEscape1() { System.out.println(“hello”); }
栈上分配: 有些对象会在虚拟机栈上分配。(相对传统观念中对象在堆区分配)
逃逸分析如果是开启的,就存在栈上分配。
如何证明栈上分配存在?
-> (在不发GC的前提下,)生成一个对象100w次,然后看堆区是否有100w个该对象,如果没有则说明存在栈上分配。
e.g.
public class StackAlloc { public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException { long start = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) alloc(); long end = System.currentTimeMillis(); System.out.println((end-start)+” ms”); while (true); } public static void alloc() { StackAlloc obj = new StackAlloc(); } }
实验1:HSDB查看堆区对象数目(逃逸分析默认是开启的)
-> 运行程序,输入命令jps –l,找到程序对应的进程ID;
-> HSDB attach到对应进程ID;
-> HSDB/Tools/Object Histogram;
-> Histogram显示该对象数目(接近20w)没有达到100w个,也没有发生GC,确定栈上分配存在。
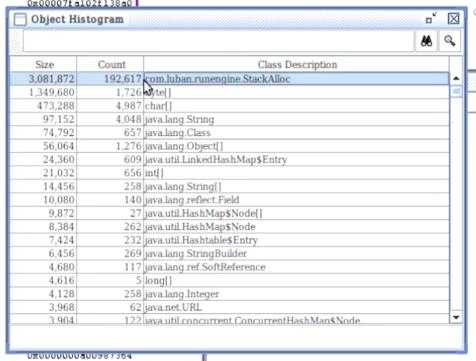
实验2:关闭逃逸分析后查看堆区对象数目
-> 关闭逃逸分析(参数设为-XX:-DoEscapeAnalysis)再运行程序;
-> HSDB attach后查看object histogram
-> histogram生成时间明显比逃逸分析开启时长,结果中显示该对象达到了代码中设定的100w个。
