常量池包括class文件常量池、运行时常量池和字符串常量池。
*常量池查看方法参考“JVM:类加载&类加载器”/实验
运行时常量池:一般意义上所指的常量池。是InstanceKlass的一个属性。存储于方法区(元空间)。
/openjdk/hotspot/src/share/vm/oops/instanceKlass.hpp
class InstanceKlass : public Klass { … ConstantPool* _constants; …. }
Class文件常量池: 可通过 javap –verbose 对象全限定名查看constant pool。存储在硬盘。
字符串常量池(String Pool):底层是StringTable。存储在堆区。继承链:HashTable – StringTable – String Pool
/openjdk/hotspot/src/share/vm/classfile/symbolTable.hpp
class StringTable : public RehashableHashtable<oop, mtSymbol> { … }
hashtable如何存储字符串
- hashtable的底层是数组+链表。
- 用hash算法对字符串对象计算得到hashValue,按照hashValue将key和value放入hashtable中,如果有冲突的放进该hashValue的链表中。
e.g.name=”ziya”; sex=”man”; zhiye=”teacher”
name/sex /zhiye的hash value为11/13/11
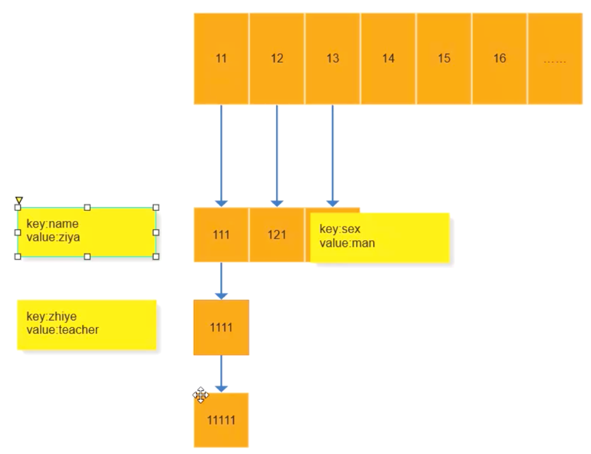
根据key从hashtable查找数据:
-> 用hash算法对key计算得到hashValue (e.g. key:name -> hashValue 11)
-> 根据hashValue区hashtable中找,如果index=hashValue的元素只有1个,直接返回;
-> 如果元素有多个,根据链表进行遍历比对key
java字符串在jvm中的存储
StringTable中key的生成方式
-> 根据字符串(name)和字符串长度计算出hashValue
-> 根据hashValue计算出index(作为key)
/openjdk/hotspot/src/share/vm/classfile/symbolTable.cpp
oop StringTable::basic_add(int index_arg, Handle string, jchar* name, int len, unsigned int hashValue_arg, TRAPS) { … hashValue = hash_string(name, len); index = hash_to_index(hashValue); … }
StringTable中value的生成方式
-> 调用new_entry()将Java的String类实例instanceOopDesc封装成HashtableEntry
* instanceOopDesc: OOP(ordinary object pointer)体系是Java对象在jvm中的存在形式 //相对于Klass是Java类在jvm中的存在形式
/openjdk/hotspot/src/share/vm/classfile/symbolTable.cpp
//string()就是instanceOopDesc oop StringTable::basic_add(int index_arg, Handle string, jchar* name, int len, unsigned int hashValue_arg, TRAPS) { … HashtableEntry<oop, mtSymbol>* entry = new_entry(hashValue, string()); add_entry(index, entry); … }
new_entry()包含有关HashtableEntry的一些链表操作。
/openjdk/hotspot/src/share/vm/utilities/hashtable.cpp
template <MEMFLAGS F> BasicHashtableEntry<F>* BasicHashtable<F>::new_entry(unsigned int hashValue) { … }
HashtableEntry是一个单向链表结点结构。value对应要封装的字符串对象InstanceOopDesc,key对应hashValue。
/openjdk/jdk/src/windows/native/sun/windows/Hashtable.h
struct HashtableEntry { INT_PTR hash; void* key; void* value; HashtableEntry* next; };
创建String的底层实现
实验1
public class Test { public static void main(String[] args) { String s1=”11”; String s2=new String(“11”); System.out.println(s1.hashCode()); System.out.println(s2.hashCode()); System.out.println(s1==s2); System.out.println(s1.equals(s2)); } }
结果:两次输出hashCode值相同,s1==s2为false, s1.equals(s2)为true。
原因:1) 因为hashCode就是根据字符串值计算得到的,字符串值一样hashCode就会一样。
2) s1==s2比较的是地址。
* String重写了Object中的hashCode方法。
String的值是存储在字符数组char[] value中的。
基本数据类型数组的对象生成的实例为TypeArrayOopDesc(对应Klass体系中基本数据类型数组的元信息存放在TypeArrayKlass)。
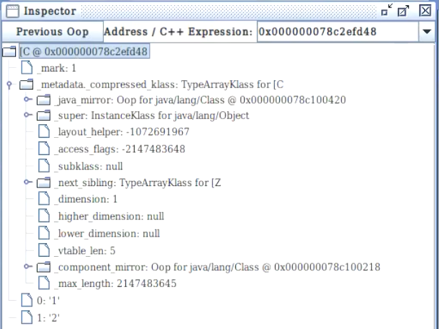
实验2:证明字符数组在jvm中以TypeArrayOopDesc形式存在
public class Test { public static void main(String[] args) { char[] arr=new char[]{‘1’, ‘2’}; while (true); } }
-> 代码中声明字符数组
-> HSDB attach到对应进程,查看main线程堆栈,找到[C的内存地址

-> Inspector查看证明元信息存储在TypeArrayKlass,对象为OOP(TypeArrayOopDesc)。
实验3 String s1 = “1”;语句生成了几个OOP?2个。
public class Test { public static void main(String[] args) { test3(); } public static void test3() { String s1=”11”; } }
1) TypeArrayOopDesc – char数组
2) InstanceOop – String对象
证明:在语句处设置断点, idea debug模式运行程序(Debug模式单步验证)
-> 勾选memory,memory layout点击load classes
-> 执行完String s1=“11”时,String和char[]的count都增1;

原因:
 //底层
//底层
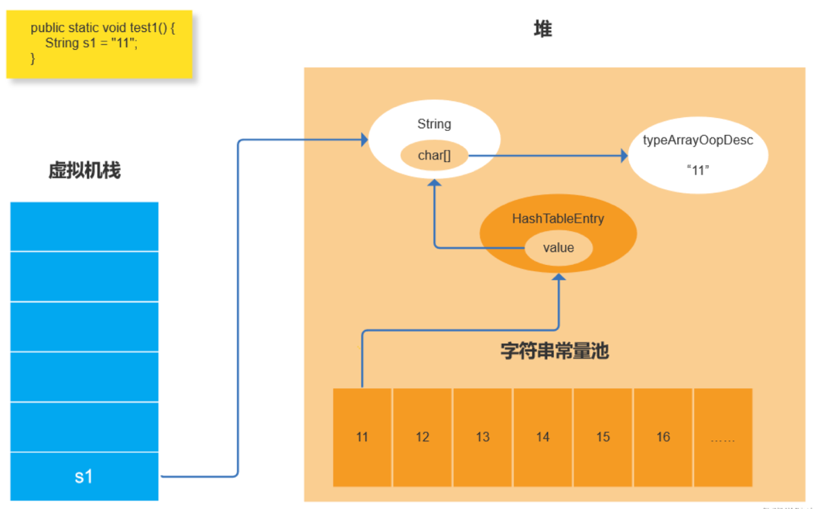
* 因为是字面量,该String值会放在字符串常量池
-> 在字符串常量池中找有没有该value(“11”),如果有则直接返回对应的String对象;
-> 如果没有找到,创建该value的typeArrayOopDesc,再创建String, String中包含char数组,char数组指向该typeArrayOopDesc;
-> 在字符串常量池表创建HashTableEntry指向String(将String对象对应的InstanceOopDesc封装成HashTableEntry作为StringTable的value存储)。
*面试题:创建了几个对象
-> 先问清楚问的是String对象还是OOP对象
-> 如果问创建了几个String对象-> 1个。
-> 如果问创建了几个OOP对象 -> 2个: 1个char数组,1个String对象对应的OOP。
//HashTableEntry是C++对象,不算入OOP对象。
实验4 String s1 = “11”; String s2=”11”;语句生成了几个OOP? 2个。
证明:
public class Test { public static void main(String[] args) { test4(); } public static void test4() { String s1=”11”; String s2=”11”; } }
Debug模式单步验证,
-> 执行完String s1=“11”时,String和char[]都增1;

-> 执行完String s2=“11”时,count没有增加;

原因:

-> s1的创建参考实验1;
-> 创建s2时,在字符串常量池中有找到该值,不需要再创建,S2直接和S1指向同一个String对象。
*面试题:创建了几个对象
-> 先问清楚问的是String对象还是OOP对象
-> 如果问创建了几个String对象-> 1个。
-> 如果问创建了几个OOP对象 -> 2个: 1个char数组,1个String对象(对应的OOP)。
实验5 String s1 = new String(“11”)语句生成了几个OOP? 3个。
证明:
public class Test { public static void main(String[] args) { test5(); } public static void test5() { String s1=new String(“11”); } }
Debug模式单步验证,
-> 执行完String s1=new String(“11”)时,String增2,char[]增1;

原因:
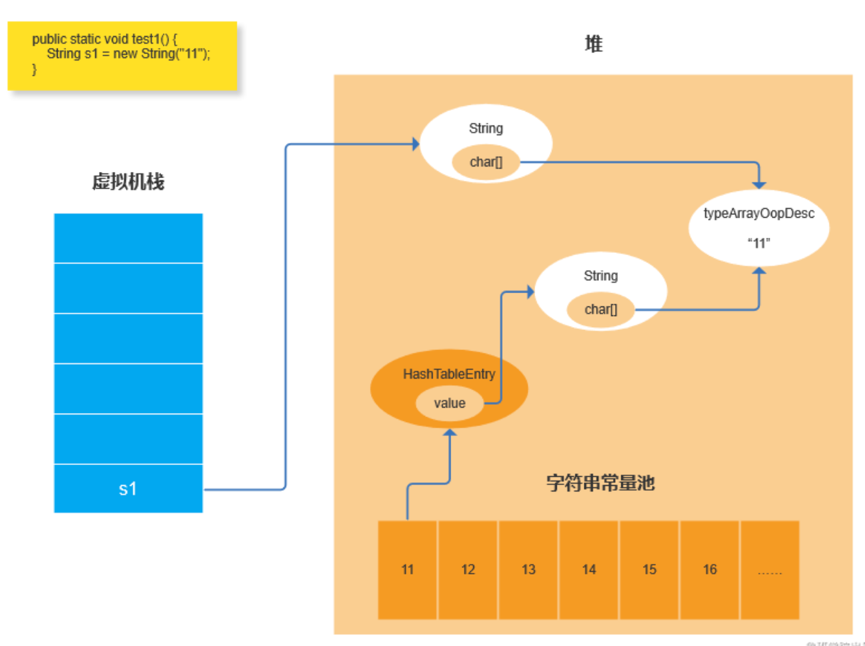
-> 在字符串常量池中找,发现没有该value(“11”);
-> 创建HashTableEntry指向String,String指向typeArrayOopDesc;
-> 因为new,又在堆区再创建一个String对象,其char数组直接指向已创建的typeArrayOopDesc。
实验6 String s1 = new String(“11”); String s2 = new String(“11”);语句生成了几个OOP? 4个。
证明:
public class Test { public static void main(String[] args) { test6(); } public static void test6() { String s1=new String(“11”); String s2=new String(“11”); } }
Debug模式单步验证,
-> 执行完String s1=new String(“11”)时,String增2,char[]增1;

-> 执行完String s2=new String(“11”)时,String增1。

原因:
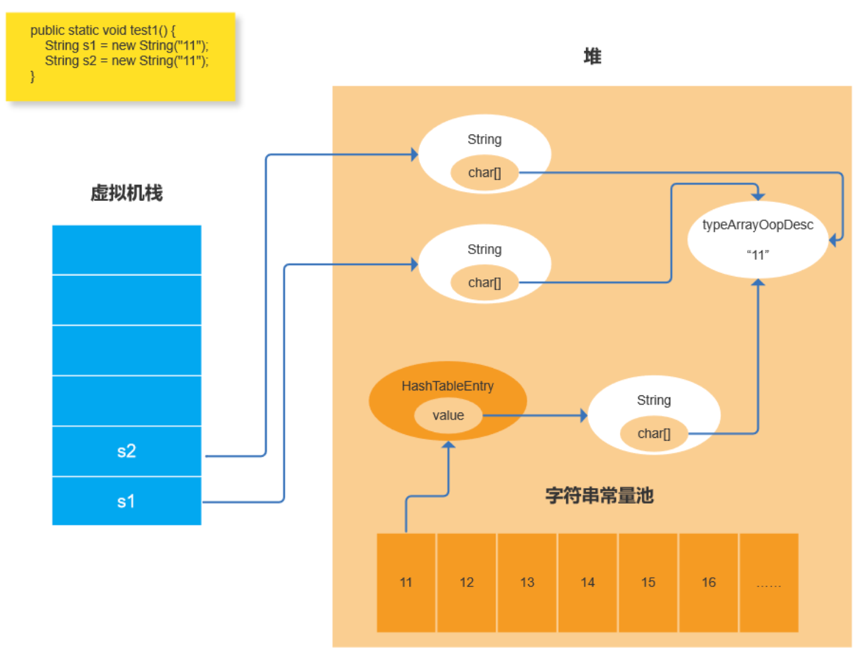
-> s1的创建参考实验5;
-> 创建s2时,因为new,再创建一个String对象指向同一个typeArrayOopDesc。
实验7 String s1 = “11”; String s2=”22”;语句生成了几个OOP? 4个。
证明:
public class Test { public static void main(String[] args) { test7(); } public static void test7() { String s1=“11”; String s2=“22”; } }
创建了几个对象?
-> 如果问创建了几个String对象?-> 2个。
-> 如果问创建了几个OOP对象? -> 4个。
String拼接
实验8
public class Test { public static void main(String[] args) { test8(); } public static void test8() { String s1=“1”; String s2=”1”; String s = s1+s2; } }
Debug模式单步验证,
-> 执行完String s1=”1”时,char[]和String的count都增1;

-> 执行完String s2=”1”时,count没有增加;

-> 执行完String s=s1+s2时,char[]和String的count都增1。
//因为语句3底层调用StringBuilder.toString()==调用String构造方法String(value, offset, count),不会在常量池生成记录,只创建了1个String对象。(参考:String的两种构造方法)

所以总共创建了2个String,4个OOP(2个char数组,2个String)。
对应字节码:
0 ldc #2 <1> 2 astore_0 3 ldc #2 <1> 5 astore_1 6 new #3 <java/lang/StringBuilder> 9 dup 10 invokespecial #4 <java/lang/StringBuilder.<init>> 13 aload_0 14 invokevirtual #5 <java/lang/StringBuilder.append> 17 aload_1 18 invokevirtual #5 <java/lang/StringBuilder.append> 21 invokevirtual #6 <java/lang/StringBuilder.toString> 24 astore_2 25 return
说明拼接语句String s=s1+s2底层是用new StringBuilder().append(“1”).apend(“1”).toString()实现的。
String的两种构造方法
StringBuilder的toString()调用了String(char[] value, int offset, int count)的构造方法。
StringBuilder.class
Public String toString() { return new String(this.value, 0, this.count); }
String(value)会创建2个String,3个OOP (实验运行String s2=new String(“22”),结果char[]增1,String增2)。
String(value, offset, count)会创建1个String,2个OOP(可实验运行String s1=new String(new char[]{‘1’,’1’},0,count); 结果char[]和String都增1证明)。该构造方法不会在常量池生成记录。
*从结果来看,String(value, offset, count)创建了2个OOP,但从过程来讲则创建了3个OOP(1个String和2个char数组)。因为:
String(value, offset, count) 用到了copyOfRange();
String.class
Public String(char[], int offset, int count) { … this.value = Arrays.copyOfRange(value, offset, offset + count); … }
copyOfRange()底层又重新生成了char[];
Arrays.class
Public static char[] copyOfRange(char[] original, int from, int to) { … char[] copy = new char[newLength]; … }
String.intern()
intern()去常量池中找字符串,如果有直接返回,如果没有就把String对应的instanceOopDesc封装成HashTableEntry存储(写入常量池)。
实验9
public class Test { public static void main(String[] args) { test9(); } public static void test9() { String s1=“1”; String s2=”1”; String s = s1+s2; s.intern(); String str=”11”; System.out.println(s==str); } }
结果:有执行intern输出true,没有执行intern输出false
原因:
如果没有调用intern,String s=s1+s2执行时不会在常量池中生成记录,所以String str=”11”执行时依然会生成新String;
如果有调用intern,intern()将s=”11”写入常量池,后面str就会在常量池中找到该值,直接指向s所创建的String对象。
Debug模式单步验证,
如果没有调用intern,执行完String str=”11”时,String和char[]的count都增1;
如果有调用intern,执行完String str=”11”时,count没有增加。
实验10
public class Test { public static void main(String[] args) { test10(); } public static void test10() { final String s1=“3”; final String s2=”3”; String s = s1+s2; s.intern(); String str=”33”; System.out.println(s==str); } }
结果:有没有执行intern都输出true。
原因:因为s1和s2都是常量,编译优化时已经将String s=s1+s2变成String s=”33”,33”会被存储到常量池。
(没有执行intern版本)字节码:
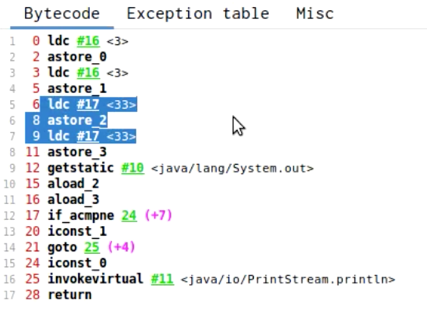
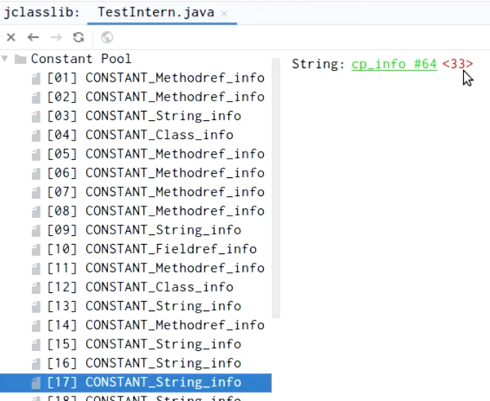
//常量池17位为CONSTANT_String_info “33”。
Debug模式单步验证,(如果没有调用intern方法)
-> 执行完final String s1=”3”时String和char[]的count都增1;
-> 执行完final String s2=”3”时count没有增加;
-> 执行完String s=s1+s2时String和char[]的count都增1;
-> 执行完String str=”33”时count没有增加 (因为已经能够在常量池找到)。
实验11
public class Test { public static void main(String[] args) { test11(); } public static void test11() { final String s1=new String(“5”); final String s2=new String(”5”); String s = s1+s2; //s.intern(); String str=”55S”; System.out.println(s==str); } }
结果:没有执行intern输出false。
原因:new得到的对象不是常量(类似uuid的动态生成,见”JVM: 类加载&类加载器”)。-- 虽然用了final修饰,只能表示引用是final,引用指向的值并不是final。
(没有执行intern版本)字节码:
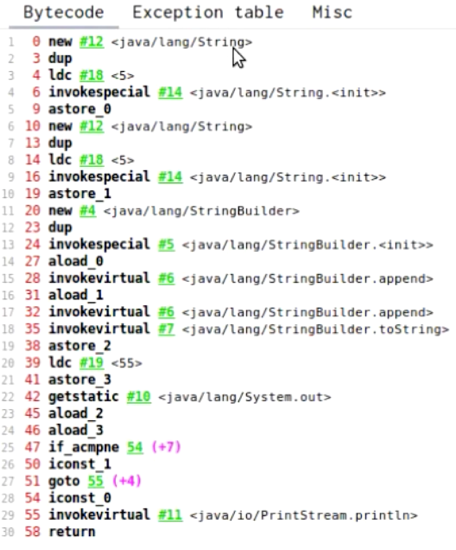
----
练习1
String s1 = “11”+new String(“22”);
结果:实验显示该语句新增4个String和3个char数组。
原因:可以拆开来分析:
1) “11” -> 1个String,1个char数组;
2) new String(“22”) -> 2个String,1个char数组;
3) 拼接->底层调用StringBuilder.toString()->底层调用String(value, offset, count)-> 1个String,1个char数组。
所以总共生成4个String,3个char数组。
练习2
String s1 = “11”+”11”; String s2 = “11”+new String(“22”);
结果:即使前面有语句1,语句2仍然新增4个String和3个char数组。
原因:语句1在编译时已经被计算替换为s1=“1111”(查看字节码可证);语句2过程分析同练习1。
e.g.
