前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
基本开发环境
- Python 3.6
- Pycharm
相关模块的使用
- requests
- parsel
- csv
安装Python并添加到环境变量,pip安装需要的相关模块即可。
爬虫基本思路

一、明确需求
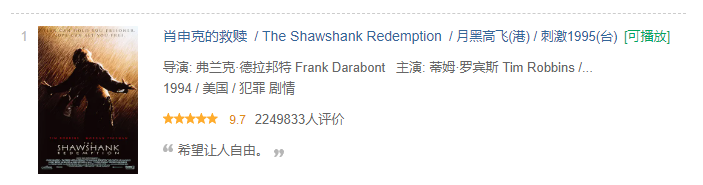
爬取豆瓣Top250排行电影信息
- 电影名字
- 导演、主演
- 年份、国家、类型
- 评分、评价人数
- 电影简介
二、发送请求
Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模块就是requests。


请求url地址,使用get请求,添加headers请求头,模拟浏览器请求,网页会给你返回response对象
# 模拟浏览器发送请求
import requests
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response)

200是状态码,表示请求成功
2xx (成功)
3xx (重定向)
4xx(请求错误)
5xx(服务器错误)
常见状态码
- 200 - 服务器成功返回网页,客户端请求已成功。
- 302 - 对象临时移动。服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
- 304 - 属于重定向。自上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。
- 401 - 未授权。请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
- 404 - 未找到。服务器找不到请求的网页。
- 503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。通常,这只是暂时状态。
三、获取数据
import requests
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)

requests.get(url=url, headers=headers) 请求网页返回的是response对象
response.text: 获取网页文本数据
response.json: 获取网页json数据
这两个是用的最多的,当然还有其他的
apparent_encoding cookies history
iter_lines ok close
elapsed is_permanent_redirect json
raise_for_status connection encoding
is_redirect links raw
content headers iter_content
next reason url
四、解析数据
常用解析数据方法: 正则表达式、css选择器、xpath、lxml...
常用解析模块:bs4、parsel...
我们使用的是 parsel 无论是在之前的文章,还是说之后的爬虫系列文章,我都会使用 parsel 这个解析库,无它就是觉得它比bs4香。
parsel 是第三方模块,pip install parsel 安装即可
parsel 可以使用 css、xpath、re解析方法

所有的电影信息都包含在 li 标签当中。
# 把 response.text 文本数据转换成 selector 对象
selector = parsel.Selector(response.text)
# 获取所有li标签
lis = selector.css('.grid_view li')
# 遍历出每个li标签内容
for li in lis:
# 获取电影标题 hd 类属性 下面的 a 标签下面的 第一个span标签里面的文本数据 get()输出形式是 字符串获取一个 getall() 输出形式是列表获取所有
title = li.css('.hd a span:nth-child(1)::text').get() # get()输出形式是 字符串
movie_list = li.css('.bd p:nth-child(1)::text').getall() # getall() 输出形式是列表
star = movie_list[0].strip().replace('xa0xa0xa0', '').replace('/...', '')
movie_info = movie_list[1].strip().split('xa0/xa0') # ['1994', '美国', '犯罪 剧情']
movie_time = movie_info[0] # 电影上映时间
movie_country = movie_info[1] # 哪个国家的电影
movie_type = movie_info[2] # 什么类型的电影
rating_num = li.css('.rating_num::text').get() # 电影评分
people = li.css('.star span:nth-child(4)::text').get() # 评价人数
summary = li.css('.inq::text').get() # 一句话概述
dit = {
'电影名字': title,
'参演人员': star,
'上映时间': movie_time,
'拍摄国家': movie_country,
'电影类型': movie_type,
'电影评分': rating_num,
'评价人数': people,
'电影概述': summary,
}
# pprint 格式化输出模块
pprint.pprint(dit)

以上的知识点使用到了
- parsel 解析模块的方法
- for 循环
- css 选择器
- 字典的创建
- 列表取值
- 字符串的方法:分割、替换等
- pprint 格式化输出模块
所以扎实基础是很有必要的。不然你连代码都不知道为什么要这样写。
五、保存数据(数据持久化)
常用的保存数据方法 with open
像豆瓣电影信息这样的数据,保存到Excel表格里面会更好。
所以需要使用到 csv 模块
# csv模块保存数据到Excel
f = open('豆瓣电影数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['电影名字', '参演人员', '上映时间', '拍摄国家', '电影类型',
'电影评分', '评价人数', '电影概述'])
csv_writer.writeheader() # 写入表头

这就是爬取了数据保存到本地了。这只是一页的数据,爬取数据肯定不只是爬取一页数据。想要实现多页数据爬取,就要分析网页数据的url地址变化规律。

可以清楚看到每页url地址是 25 递增的,使用for循环实现翻页操作
for page in range(0, 251, 25):
url = f'https://movie.douban.com/top250?start={page}&filter='
完整实现代码
""""""
import pprint
import requests
import parsel
import csv
'''
1、明确需求:
爬取豆瓣Top250排行电影信息
电影名字
导演、主演
年份、国家、类型
评分、评价人数
电影简介
'''
# csv模块保存数据到Excel
f = open('豆瓣电影数据.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['电影名字', '参演人员', '上映时间', '拍摄国家', '电影类型',
'电影评分', '评价人数', '电影概述'])
csv_writer.writeheader() # 写入表头
# 模拟浏览器发送请求
for page in range(0, 251, 25):
url = f'https://movie.douban.com/top250?start={page}&filter='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# 把 response.text 文本数据转换成 selector 对象
selector = parsel.Selector(response.text)
# 获取所有li标签
lis = selector.css('.grid_view li')
# 遍历出每个li标签内容
for li in lis:
# 获取电影标题 hd 类属性 下面的 a 标签下面的 第一个span标签里面的文本数据 get()输出形式是 字符串获取一个 getall() 输出形式是列表获取所有
title = li.css('.hd a span:nth-child(1)::text').get() # get()输出形式是 字符串
movie_list = li.css('.bd p:nth-child(1)::text').getall() # getall() 输出形式是列表
star = movie_list[0].strip().replace('xa0xa0xa0', '').replace('/...', '')
movie_info = movie_list[1].strip().split('xa0/xa0') # ['1994', '美国', '犯罪 剧情']
movie_time = movie_info[0] # 电影上映时间
movie_country = movie_info[1] # 哪个国家的电影
movie_type = movie_info[2] # 什么类型的电影
rating_num = li.css('.rating_num::text').get() # 电影评分
people = li.css('.star span:nth-child(4)::text').get() # 评价人数
summary = li.css('.inq::text').get() # 一句话概述
dit = {
'电影名字': title,
'参演人员': star,
'上映时间': movie_time,
'拍摄国家': movie_country,
'电影类型': movie_type,
'电影评分': rating_num,
'评价人数': people,
'电影概述': summary,
}
pprint.pprint(dit)
csv_writer.writerow(dit)
实现效果

