本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: python小爬虫
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
-
效果图,其中涉及一些真名我就打码了,还有qq号我也打码了,见谅
-
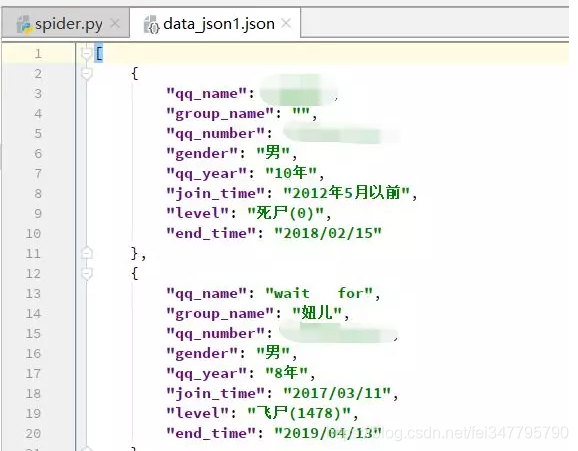
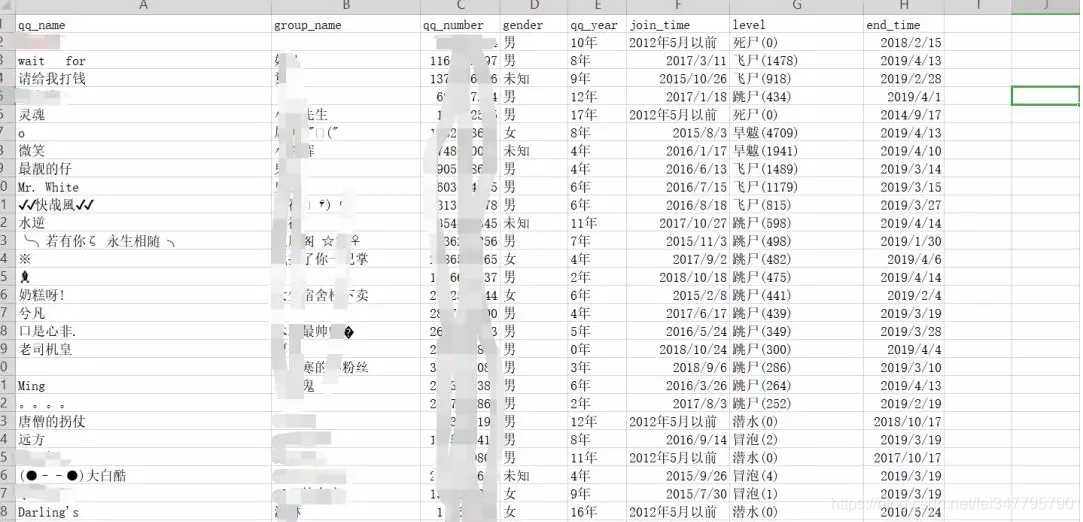
-
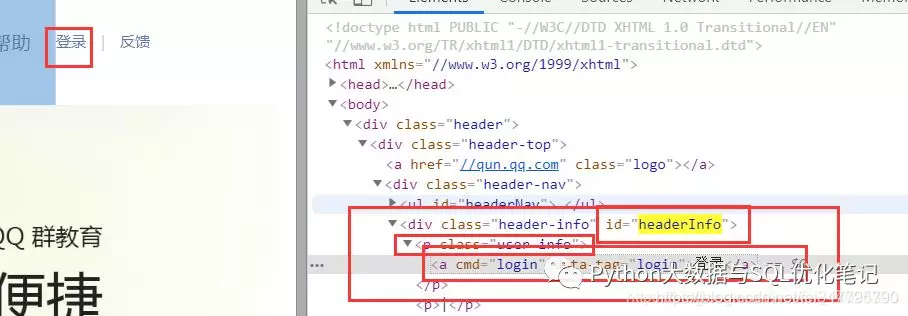
分析登陆的元素,下图一目了然,怎么获取这个登陆元素应该都知道了
-
-
代码奉上
1 url = 'https://qun.qq.com/' 2 # 构建谷歌驱动器 3 browser = webdriver.Chrome() 4 # 请求url 5 browser.get(url) 6 # 模拟登陆,首先找到登陆的id,并点击 7 browser.find_element_by_css_selector('#headerInfo p a').click()
-
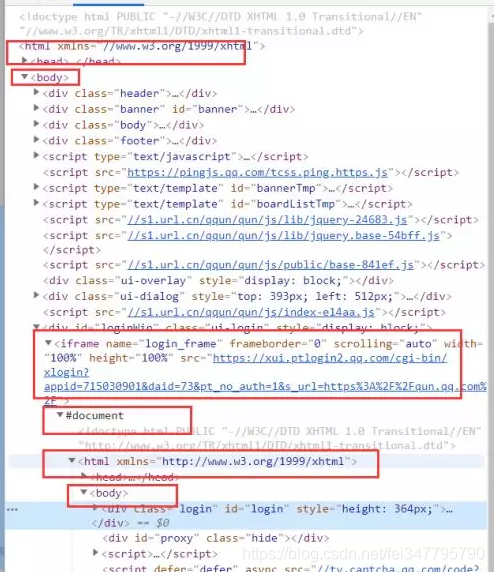
点击之后出现这么一个框框(这个框框可把我折磨的阿)原因是这样的,寻常的获取这个框框是不能获取到的
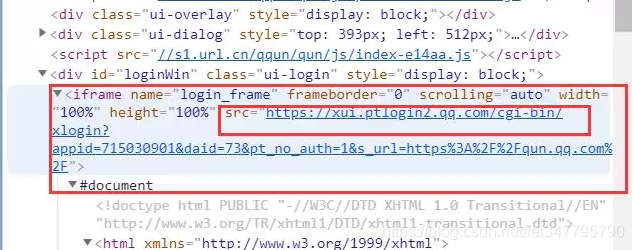
5.先看看这个框所在的位置,这个框框竟然在另一个html代码里面,也就是说在浏览器看的时候,出现了两个html标签,老实说,我是第一次看到这种情况的,奈何我的html也不好,连入门都算不上,没办法,我就去百度了,果然黄天不负有心人,说是因为iframe这个标签可以再放html代码,所以就是这种情况了
-
既然知道了是怎么一回事之后,那就可以继续操作了,首先我们先找到iframe这个标签,然后获取它的src属性,这个链接就是这个框框登陆的链接了,如果不获取这个iframe标签的src属性,那么我们使用selenium是获取不到这个框框的元素的。
1 # 点击之后会弹出一个登陆框,这时候我们用显示等待来等待这个登陆框加载出来 2 WebDriverWait(browser, 1000).until( 3 EC.presence_of_all_elements_located( 4 (By.CSS_SELECTOR, '#loginWin iframe') 5 ) 6 ) 7 print('登陆框已加载') 8 # 登陆框加载之后,我们发现整个登陆框其实就是另一个网网页 9 # 如果在原网页操作这个登陆框的话,是不能操作的 10 # 所以我们只需要提取iframe标签的src属性,然后再去访问这个url即可实现 11 # 自动登陆 12 # 找到iframe标签并获取src 13 iframe_url = browser.find_element_by_css_selector('#loginWin iframe').get_attribute('src') 14 # 再访问这个url 15 browser.get(iframe_url) 16 # 找到快捷登陆的头像并点击 17 # 首先用显示等待这个头像已经加载完成 18 WebDriverWait(browser, 1000).until( 19 EC.presence_of_all_elements_located( 20 (By.ID, 'qlogin_list') 21 ) 22 ) 23 browser.find_element_by_css_selector('#qlogin_list a').click() 24 print('登陆成功')
-
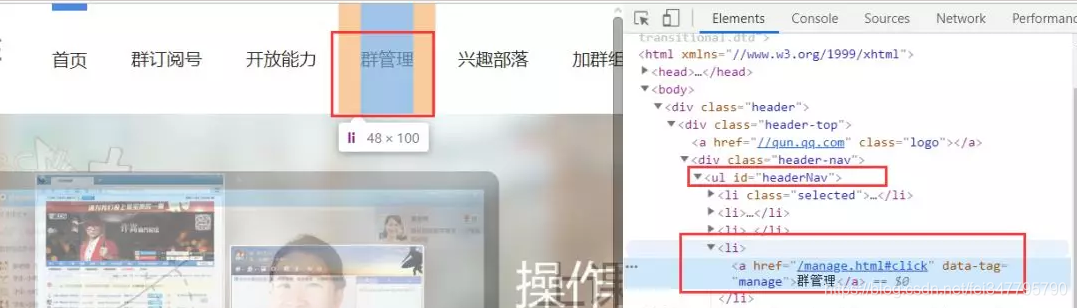
登陆成功之后我们需要的是群管理,是ul标签的第四个li标签,通过xpath获取
-
1 # 登陆成功之后,我们就找到群管理的标签并点击,首先等待这个元素加载完成 2 WebDriverWait(browser, 1000).until( 3 EC.presence_of_all_elements_located( 4 (By.XPATH, './/ul[@id="headerNav"]/li[4]') 5 ) 6 ) 7 browser.find_element_by_xpath('.//ul[@id="headerNav"]/li[4]').click()
8.点击群管理之后,进入群管理界面,我们需要的是成员管理

1 # 点击之后,我们找到成员管理标签并点击 2 WebDriverWait(browser, 1000).until( 3 EC.presence_of_all_elements_located( 4 (By.CLASS_NAME, 'color-tit') 5 ) 6 ) 7 browser.find_element_by_class_name('color-tit').click()
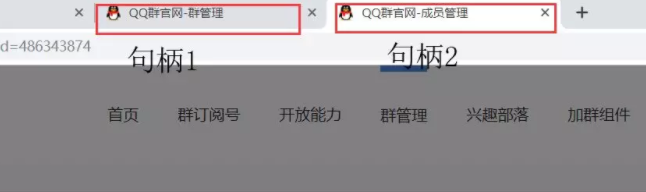
9.点击成员管理之后会重新新建一个窗口,这个时候就会出现句柄,我们需要将当然窗口的句柄切换到新打开的这个界面,不然的话,是获取不到新打开界面的信息的,注释已经写了
1 # 打印全部窗口句柄 2 # print(browser.window_handles) 3 # 打印当前窗口句柄 4 # print(browser.current_window_handle) 5 # 注意这里点击成员管理之后会自动跳转到一个新窗口打开这个页面 6 # 所以我们需要将窗口句柄切换到这个新窗口 7 8 browser.switch_to.window(browser.window_handles[1]) 9 10 # 解释一下browser.switch_to.window是获取当前一共有几个窗口 11 # 这里是2个 12 # browser.switch_to.window这个是指定当前游标切换到哪个窗口 13 # 其实也可以这么写 14 # all_window = browser.switch_to.window返回的是一个列表 15 # browser.switch_to.window(all_window[1]) 16 # 效果是一样的
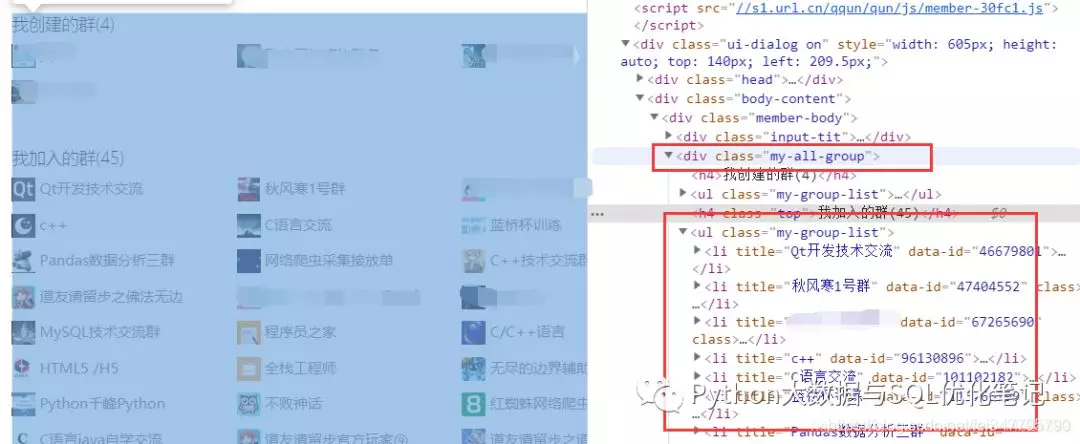
10.我们需要的是我加入的群信息
1 # 切换句柄之后,我们显示等待窗口出来 2 WebDriverWait(browser, 1000).until( 3 EC.presence_of_all_elements_located( 4 (By.CLASS_NAME, 'my-all-group') 5 ) 6 ) 7 8 # 筛选出我加入的群标签 9 lis = browser.find_elements_by_xpath('.//div[@class="my-all-group"]/ul[2]/li')
11.遍历列表,取出信息
# 遍历 num= 0 while True: if num == len(lis): break try: # 按顺序选择群并获取信息 # 先点击该群获取成员信息 lis[num].click() # 显示等待信息加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'list') ) ) # 获取该群当前有多少人,后面翻页需要 groupMemberNum = eval(browser.find_element_by_id('groupMemberNum').text) # 每一次翻页都会刷新21条信息,所以写个循环 # 这里加1是因为假如一个群有36人,那么count=1,如果循环的话就不会翻页了 # 也就是只能抓到一页的数据,大家可以自己想想其中的流程就知道了 count = groupMemberNum // 21 + 1 # 这里我只爬取每个群的一部分,如果想爬取全部成员信息 # 请注释下面的if语句 if count > 2: count = 1 # 每次循环都进行翻页 # while count: # count -= 1 # # browser.execute_script('document.documentElement.scrollTop=100000') # time.sleep(2) time.sleep(2) # 开始获取成员信息 trs = browser.find_elements_by_class_name('mb') if trs: # 遍历 for tr in trs: tds = tr.find_elements_by_tag_name('td')[2:] if len(tds) == 8: # qq网名 qq_name = tds[0].text # 群名称 group_name = tds[1].text # qq号 qq_number = tds[2].text # 性别 gender = tds[3].text # qq年龄 qq_year = tds[4].text # 入群时间 join_time = tds[5].text # 等级(积分) level = None # 最后发言时间 end_time = tds[6].text # 声明一个字典存储数据 data_dict = {} data_dict['qq_name'] = qq_name data_dict['group_name'] = group_name data_dict['qq_number'] = qq_number data_dict['gender'] = gender data_dict['qq_year'] = qq_year data_dict['join_time'] = join_time data_dict['level'] = level data_dict['end_time'] = end_time print(data_dict) elif len(tds) == 9: # qq网名 qq_name = tds[0].text # 群名称 group_name = tds[1].text # qq号 qq_number = tds[2].text # 性别 gender = tds[3].text # qq年龄 qq_year = tds[4].text # 入群时间 join_time = tds[5].text # 等级(积分) level = tds[6].text # 最后发言时间 end_time = tds[7].text # 声明一个字典存储数据 data_dict = {} data_dict['qq_name'] = qq_name data_dict['group_name'] = group_name data_dict['qq_number'] = qq_number data_dict['gender'] = gender data_dict['qq_year'] = qq_year data_dict['join_time'] = join_time data_dict['level'] = level data_dict['end_time'] = end_time data_list.append(data_dict) print(data_dict) browser.find_element_by_id('changeGroup').click() time.sleep(3) WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'ui-dialog') ) ) lis = browser.find_elements_by_xpath('.//div[@class="my-all-group"]/ul[2]/li') num += 1 except Exception as e: lis = browser.find_elements_by_xpath('.//div[@class="my-all-group"]/ul[2]/li') num += 1 continue
1 # 导入需要的包 2 # 爬取qq群的成员信息 3 from selenium import webdriver 4 from selenium.webdriver.support.ui import WebDriverWait 5 from selenium.webdriver.support import expected_conditions as EC 6 from selenium.webdriver.common.by import By 7 import time 8 import json 9 import csv 10 11 12 # 开始登陆 13 def login_spider(): 14 15 url = 'https://qun.qq.com/' 16 # 构建谷歌驱动器 17 browser = webdriver.Chrome() 18 # 请求url 19 browser.get(url) 20 # 模拟登陆,首先找到登陆的id,并点击 21 browser.find_element_by_css_selector('#headerInfo p a').click() 22 # 点击之后会弹出一个登陆框,这时候我们用显示等待来等待这个登陆框加载出来 23 WebDriverWait(browser, 1000).until( 24 EC.presence_of_all_elements_located( 25 (By.CSS_SELECTOR, '#loginWin iframe') 26 ) 27 ) 28 print('登陆框已加载') 29 # 登陆框加载之后,我们发现整个登陆框其实就是另一个网网页 30 # 如果在原网页操作这个登陆框的话,是不能操作的 31 # 所以我们只需要提取iframe标签的src属性,然后再去访问这个url即可实现 32 # 自动登陆 33 # 找到iframe标签并获取是如此熟悉 34 iframe_url = browser.find_element_by_css_selector('#loginWin iframe').get_attribute('src') 35 # 再访问这个url 36 browser.get(iframe_url) 37 # 找到快捷登陆的头像并点击 38 # 首先用显示等待这个头像已经加载完成 39 WebDriverWait(browser, 1000).until( 40 EC.presence_of_all_elements_located( 41 (By.ID, 'qlogin_list') 42 ) 43 ) 44 browser.find_element_by_css_selector('#qlogin_list a').click() 45 print('登陆成功') 46 47 return browser 48 49 50 # 切换句柄操作 51 def switch_spider(browser): 52 # 登陆成功之后,我们就找到群管理的标签并点击,首先等待这个元素加载完成 53 WebDriverWait(browser, 1000).until( 54 EC.presence_of_all_elements_located( 55 (By.XPATH, './/ul[@id="headerNav"]/li[4]') 56 ) 57 ) 58 browser.find_element_by_xpath('.//ul[@id="headerNav"]/li[4]').click() 59 # 点击之后,我们找到成员管理标签并点击 60 WebDriverWait(browser, 1000).until( 61 EC.presence_of_all_elements_located( 62 (By.CLASS_NAME, 'color-tit') 63 ) 64 ) 65 browser.find_element_by_class_name('color-tit').click() 66 # 打印全部窗口句柄 67 # print(browser.window_handles) 68 # 打印当前窗口句柄 69 # print(browser.current_window_handle) 70 # 注意这里点击成员管理之后会自动跳转到一个新窗口打开这个页面 71 # 所以我们需要将窗口句柄切换到这个新窗口 72 browser.switch_to.window(browser.window_handles[1]) 73 # 解释一下browser.switch_to.window是获取当前一共有几个窗口 74 # 这里是2个 75 # browser.switch_to.window这个是指定当前游标切换到哪个窗口 76 # 其实也可以这么写 77 # all_window = browser.switch_to.window返回的是一个列表 78 # browser.switch_to.window(all_window[1]) 79 # 效果是一样的 80 81 return browser 82 83 84 # 开始采集数据 85 def start_spider(browser): 86 # 声明一个列表存储字典 87 data_list = [] 88 # 切换句柄之后,我们显示等待窗口出来 89 WebDriverWait(browser, 1000).until( 90 EC.presence_of_all_elements_located( 91 (By.CLASS_NAME, 'my-all-group') 92 ) 93 ) 94 95 # 筛选出我加入的群标签 96 lis = browser.find_elements_by_xpath('.//div[@class="my-all-group"]/ul[2]/li') 97 # 遍历 98 num = 0 99 while True: 100 try: 101 # 按顺序选择群并获取信息 102 # 先点击该群获取成员信息 103 lis[num].click() 104 # 显示等待信息加载完成 105 WebDriverWait(browser, 1000).until( 106 EC.presence_of_all_elements_located( 107 (By.CLASS_NAME, 'list') 108 ) 109 ) 110 # 获取该群当前有多少人,后面翻页需要 111 groupMemberNum = eval(browser.find_element_by_id('groupMemberNum').text) 112 # 每一次翻页都会刷新21条信息,所以写个循环 113 # 这里加1是因为假如一个群有36人,那么count=1,如果循环的话就不会翻页了 114 # 也就是只能抓到一页的数据,大家可以自己想想其中的流程就知道了 115 count = groupMemberNum // 21 + 1 116 # 这里我只爬取每个群的一部分,如果想爬取全部成员信息 117 # 请注释下面的if语句 118 if count > 5: 119 count = 5 120 # 每次循环都进行翻页 121 while count: 122 count -= 1 123 124 browser.execute_script('document.documentElement.scrollTop=100000') 125 time.sleep(2) 126 time.sleep(3) 127 # 开始获取成员信息 128 trs = browser.find_elements_by_class_name('mb') 129 if trs: 130 # 遍历 131 for tr in trs: 132 tds = tr.find_elements_by_tag_name('td')[2:] 133 if len(tds) == 8: 134 # qq网名 135 qq_name = tds[0].text 136 # 群名称 137 group_name = tds[1].text 138 # qq号 139 qq_number = tds[2].text 140 # 性别 141 gender = tds[3].text 142 # qq年龄 143 qq_year = tds[4].text 144 # 入群时间 145 join_time = tds[5].text 146 # 等级(积分) 147 level = None 148 # 最后发言时间 149 end_time = tds[6].text 150 151 # 声明一个字典存储数据 152 data_dict = {} 153 data_dict['qq_name'] = qq_name 154 data_dict['group_name'] = group_name 155 data_dict['qq_number'] = qq_number 156 data_dict['gender'] = gender 157 data_dict['qq_year'] = qq_year 158 data_dict['join_time'] = join_time 159 data_dict['level'] = level 160 data_dict['end_time'] = end_time 161 162 print(data_dict) 163 elif len(tds) == 9: 164 # qq网名 165 qq_name = tds[0].text 166 # 群名称 167 group_name = tds[1].text 168 # qq号 169 qq_number = tds[2].text 170 # 性别 171 gender = tds[3].text 172 # qq年龄 173 qq_year = tds[4].text 174 # 入群时间 175 join_time = tds[5].text 176 # 等级(积分) 177 level = tds[6].text 178 # 最后发言时间 179 end_time = tds[7].text 180 181 # 声明一个字典存储数据 182 data_dict = {} 183 data_dict['qq_name'] = qq_name 184 data_dict['group_name'] = group_name 185 data_dict['qq_number'] = qq_number 186 data_dict['gender'] = gender 187 data_dict['qq_year'] = qq_year 188 data_dict['join_time'] = join_time 189 data_dict['level'] = level 190 data_dict['end_time'] = end_time 191 data_list.append(data_dict) 192 193 print(data_dict) 194 195 browser.find_element_by_id('changeGroup').click() 196 time.sleep(3) 197 WebDriverWait(browser, 1000).until( 198 EC.presence_of_all_elements_located( 199 (By.CLASS_NAME, 'ui-dialog') 200 ) 201 ) 202 lis = browser.find_elements_by_xpath('.//div[@class="my-all-group"]/ul[2]/li') 203 num += 1 204 except Exception as e: 205 continue 206 207 return data_list 208 209 210 def main(): 211 212 browser = login_spider() 213 browser = switch_spider(browser) 214 data_list = start_spider(browser) 215 216 # 将数据写入json文件 217 with open('data_json.json', 'a+', encoding='utf-8') as f: 218 json.dump(data_list, f) 219 print('json文件写入完成') 220 # 这里的编码格式不要写错了,不然会出现乱码,因为群里面的大神名字贼骚 221 with open('data_csv.csv', 'w', encoding='utf-8-sig', newline='') as f: 222 # 表头 223 title = data_list[0].keys() 224 # 声明writer 225 writer = csv.DictWriter(f, title) 226 # 写入表头 227 writer.writeheader() 228 # 批量写入数据 229 writer.writerows(data_list) 230 print('csv文件写入完成') 231 232 233 if __name__ == '__main__': 234 235 main()