进程中的通信就是 I-P-C ,首先想到的就是队列
管道:队列就相当于加了锁的管道,管道是不安全的,队列是安全的。所以通常会用队列。
信息共享manage,一般不会使用
from multiprocessing import Manager, Process, Lock
def func(dic, lock):
lock.acquire()
dic["count"] -= 1
lock.release()
if __name__ == '__main__':
m = Manager()
lock = Lock()
dic = m.dict({"count": 100})
p_lst = []
for i in range(1, 51):
p = Process(target=func, args=(dic, lock))
p.start()
p_lst.append(p)
for p in p_lst:
p.join()
print(dic["count"])
进程池:

当启用一两个进程的时候还行,当需要用到超过五个进程的时候,就需要使用到进程池了。
信号量和进程池的区别:
信号量是二百个任务对应二百个进程,只不过一次执行比如五个进程
进程池是二百个任务对应比如进程池中的五个进程,一次执行五个进程


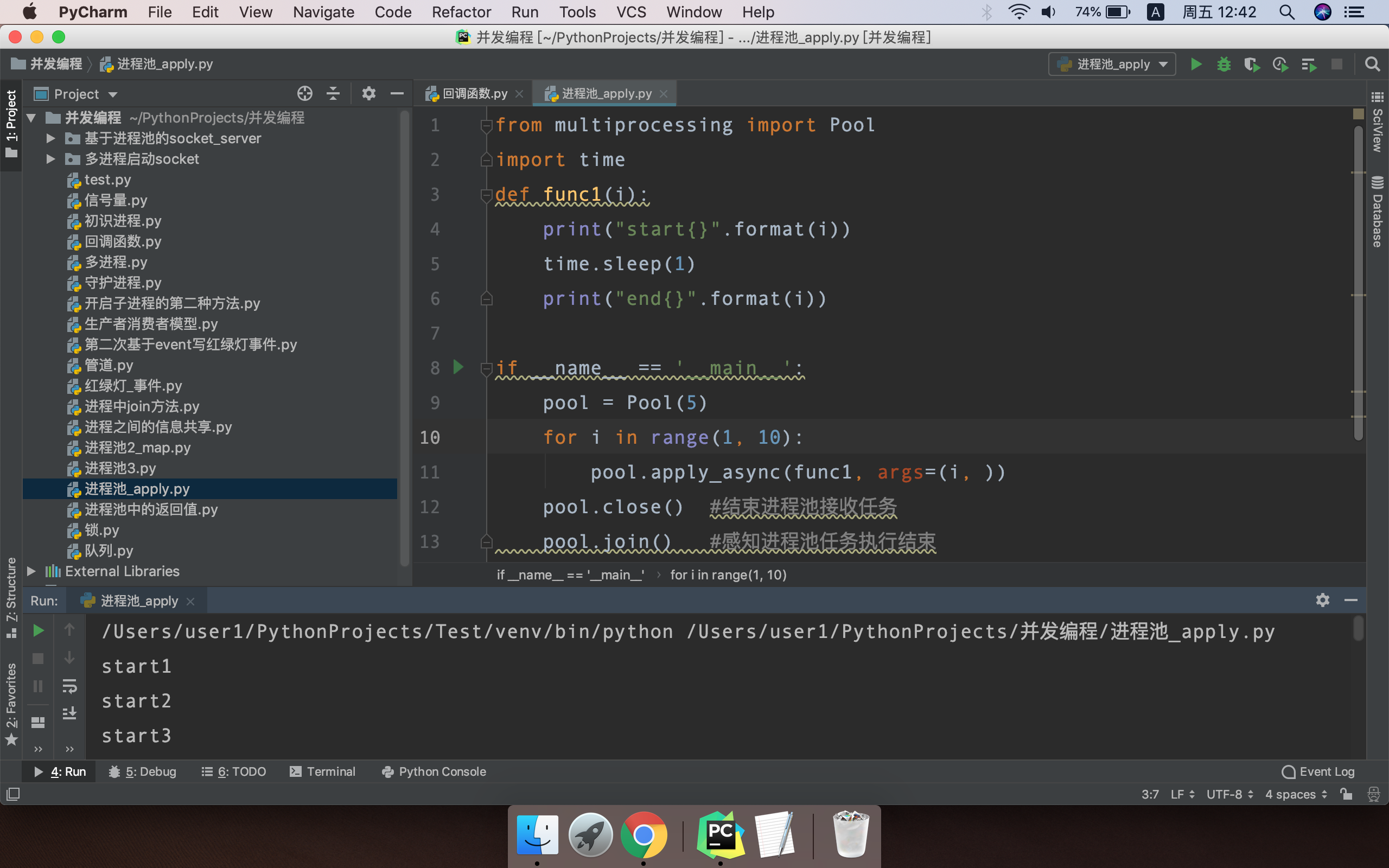
from multiprocessing import Pool def func(n): for i in range(1, 11): print(n + 1) if __name__ == '__main__': pool = Pool(5) pool.map(func, range(1, 101))
map()自带join()方法
map 中,一种任务之间的进程是异步的,多种任务之间的进程是同步的,也就说明了map()自带join()方法
apply 是进程池中同步执行任务
apply_async 是进程池中异步执行任务
进程池总结:

子进程没有返回值,进程池中的子进程有返回值
回调函数:回调函数是在主进程中执行的

回调函数一般用于爬虫中,其中访问网页、爬取网页这些事交给子进程来干,然后拿到数据的时候交给主进程来干,这样可以把效率最大化
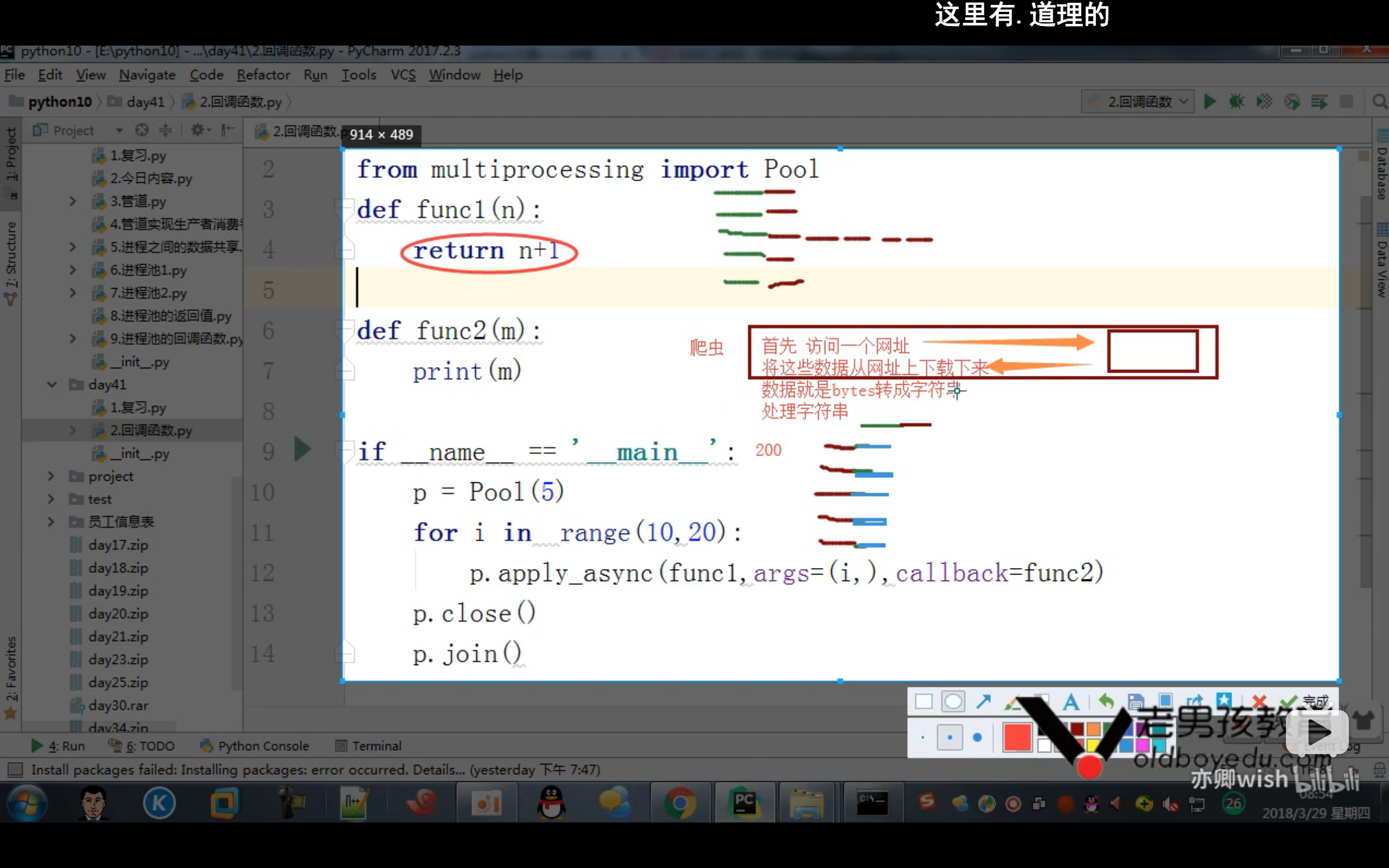
基于线程池和回调函数进行爬虫示例(58国际)
from multiprocessing import Pool
import requests
from lxml import etree
def get_url_list(main_url):
response = requests.get(main_url).content.decode()
HTML = etree.HTML(response)
url_list = HTML.xpath('//div[@class="main_list"]/div[@class="main_s clearfix"]/div[@class="info"]/a/@href')
finally_url_list = []
for url in url_list:
url = "https:" + url
finally_url_list.append(url)
return finally_url_list
def requests_url(url):
response = requests.get(url).content.decode()
return response
def handle_url(detail_response):
HTML = etree.HTML(detail_response)
title = HTML.xpath('//div[@class="houselist"]/h3/text()')[0]
print(title)
if __name__ == '__main__':
pool = Pool(5)
finally_url_list = get_url_list("http://g.58.com/j-glseoul/glchuzu/?PGTID=0d000000-05b0-5792-7a69-e9ff17a8ca8a&ClickID=2")
for url in finally_url_list:
pool.apply_async(requests_url, args=(url, ), callback=handle_url)
pool.close()
pool.join()