这一节我们来讨论IOC容器到底做了什么。
还是借用之前的那段代码
ClassPathXmlApplicationContext app = new ClassPathXmlApplicationContext("beans.xml");
Car car =app.getBean(Car.class);
System.out.println(car.getBrand()+","+car.getDesc());
这里ClassPathXmlApplicationContext是如何加载beans.xml的呢?
它到底做了哪些事情?
1.资源定位 2.资源加载 3.资源注册
再次之前,补充一点:SpringIOC容器管理了我们定义的各种Bean对象及其相互的关系,Bean对象在Spring实现中是以BeanDefinition(Bean定义资源文件中配置的POJO对象在Spring IoC容器中的映射)来描述的。
IOC初始化
现在我们通过源码来分析并验证:
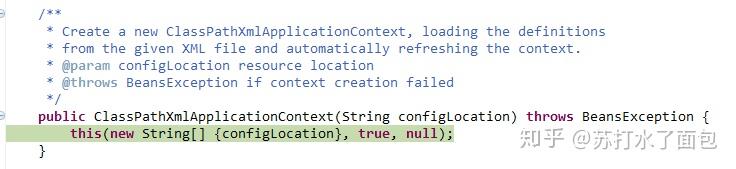
首先进入它的构造方法,这个构造方法调用其他的构造方法

没错,就是这个方法啦,参数跟上图一样。这里有三个方法:
super();
setConfigLocation();
refresh();
来看一下这三个方法:
1、资源定义
①super();//资源加载器的配置
执行的是AbstractApplicationContext的构造方法
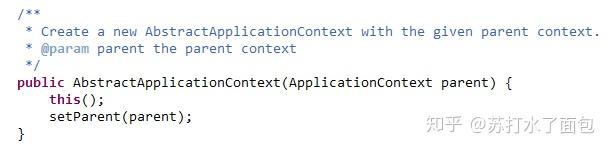


这里的this,就是ClassPathXmlApplicationContext,它间接的继承自AbstractApplication Context,而AbstractApplicationContext又继承了DefaultResourceLoader,故它本身就是个ResourceLoader

②setConfigLocation()//资源定位

处理文件路径为一个字符串的情况
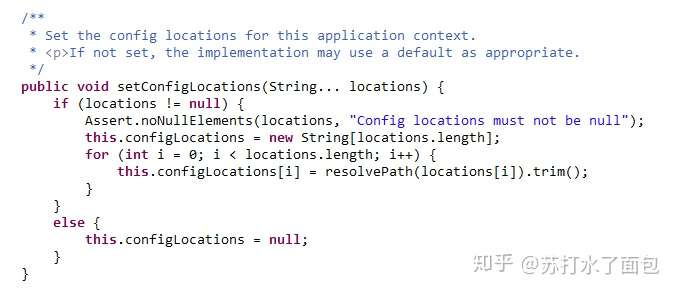
处理多个多个资源文件字符串数组
StringUtils.tokenizeToStringArray(location, CONFIG_LOCATION_DELIMITERS)
//String CONFIG_LOCATION_DELIMITERS = ",;
";
这个方法是用来解析我们给的location,因为在创建ClassPathXmlApplicationContext时,我们可以传入多个Xml的配置,并用分号隔开。如:
ClassPathXmlApplicationContext app = new ClassPathXmlApplicationContext("beans.xml;spring.xml");
这时候就需要来解析这个String了,当然这个String有多种写法,不止用分号这么简单。所以需要来解析一下。
this.configLocations[i] = resolvePath(locations[i]).trim();
这个resovlePath是用来解析一些占位符的,由于这些文件可能是 classpath , filesystem ,或者是 URL 网络资源, servletContext 等。所以可能会存在占位符。
具体的解析过程在PropertyPlaceholderHelper的parseStringValue中。
2、资源加载
AbstractApplicationContext的refresh()是一个模版方法,它就是对IOC容器进行初始化并且对资源进行载入。其中obtainFreshBeanFactory()就是对"Bean"资源加载的关键。

startupShutdownMonitor用于刷新和销毁的同步标记
①prepareRefresh()//准备刷新
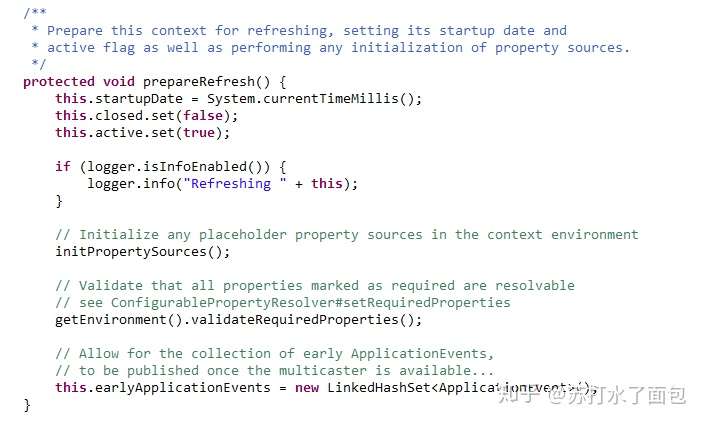
准备此上下文以进行刷新,设置其启动日期和活动标志以及执行属性源的任何初始化。
②obtainFreshBeanFactory()//资源加载
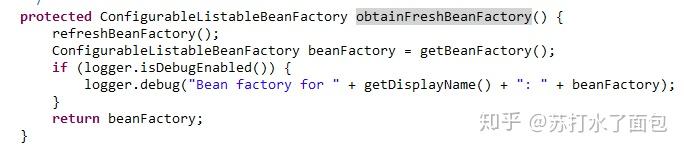
先看refreshBeanFactory();//刷新BeanFactory

判断是否存在BeanFacotry(即IOC容器),如果存在就销毁,因为IOC容器是单例的。只能存在一个。
这里createBeanFactory创建的是一个默认的DefaultListableBeanFactory

customizeBeanFactory();//初始化工厂参数
自定义此上下文使用的内部bean工厂。 为每次refresh()尝试调用。默认实现应用此上下文的“allowBeanDefinitionOverriding”和“allowCircularReferences”设置(如果已指定), 可以在子类中重写以自定义任何DefaultListableBeanFactory的设置。
loadBeanDefinitions();//加载BeanDefinitions
这里调用的是AbstractXmlApplicationContext的loadBeanDefinitions方法
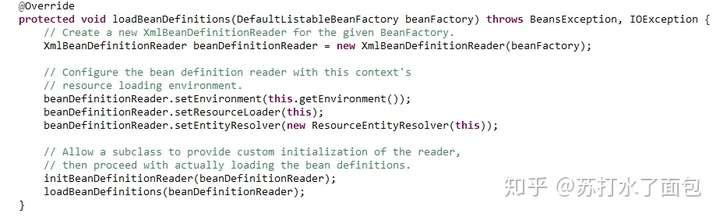
这里传入了RourceLoader的资源加载器为ClassPathXmlApplicationContext
真正执行是重写的方法

继续执行重写方法


真正执行的重写方法:
 图-X
图-X
这里首先获取getResourceLoader即是获取ClassPathXmlApplication,之前说过它继承自AbstractApplicationContext,而AbstractApplicationContext又继承了DefaultResource Loader
IOC容器是如何取到资源的呢?
这里的getResourceLoader();//取资源加载器
//获取资源
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);

这里locationPattern用来区分是以多资源文件的形式,还是单资源文件的形式(就像Spring跟SpringMVC同时使用时的情况).
String CLASSPATH_ALL_URL_PREFIX = "classpath*:";
这里走else分支的else分支(获取单个资源)
return new Resource[] {getResourceLoader().getResource(locationPattern)};
getResourceLoader()即获取资源加载器,这里的就是ClassPathXmlApplicationContext,
getResource()//获取资源

这里仍然走的是else分支,执行getResourceByPath(location);区分是从 本地,还是URL,还是其他的方式来配置的。


最终执行ClassPathResource的构造方法
最终得到的resource如下图:
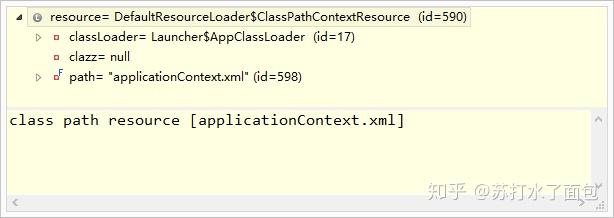
在获取到了Resource之后,我们继续回到图-X,看它接下来的操作
int loadCount = loadBeanDefinitions(resources);
最终执行XmlBeanDefinitionReader的loadBeanDefinitions方法:
/**
*从指定的XML文件加载bean定义。
* @param encodedResource XML文件的资源描述符,
*允许指定用于解析文件的编码
* @return找到的bean定义数
* @throws BeanDefinitionStoreException在加载或解析错误的情况下
*/

3、资源注册
在注册之前需要将读取到的resource转换成BeanDefinitions
这里获取资源的输入流,并执行真正执行的方法doLoadBeanDefinitions()
/**
*实际上从指定的XML文件加载bean定义。
* @param inputSource要读取的SAX InputSource
* @param资源XML文件的资源描述符
* @return找到的bean定义数
* @throws BeanDefinitionStoreException在加载或解析错误的情况下
* @see #doLoadDocument
* @see #registerBeanDefinitions
*/
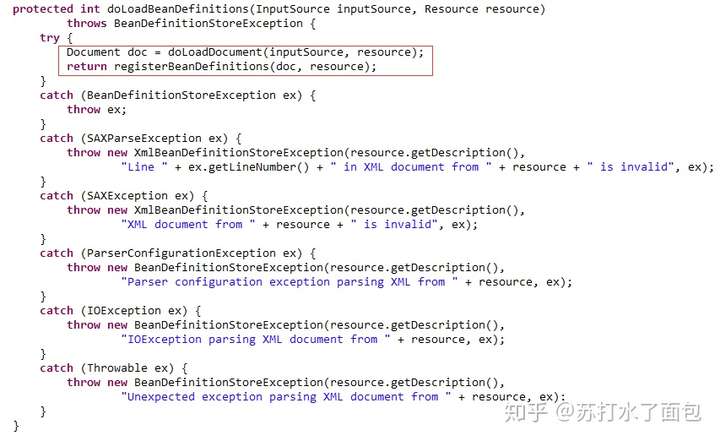
这里doLoadDocument(inputSource,resource)将资源文件转换成DOM对象
具体转换过程这里就不进行细看了,主要使用JAXP。
转换成DOM之后需要做的就是将DOM转换成Spring能够识别的数据结构BeanDefinitions

这里的BeanDefinitionDocumentReader用于解析实际的DOM文档。
这里执行DefaultBeanDefinitionDocumentReader的registerBeanDefinitions

doRegisterBeanDefinitions();是真正的注册beanDefinitions的方法
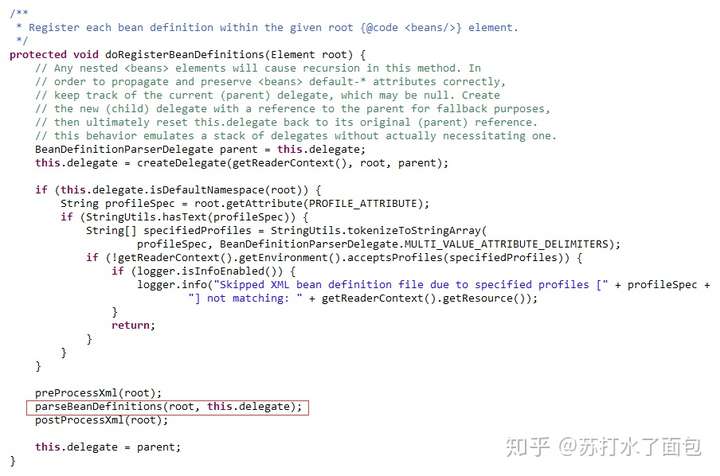
这里有一个用来帮助解析的类:
BeanDefinitionParserDelegate
官方给的解释是:用于解析XML bean定义的有状态委托类。 旨在供主解析器和任何扩展BeanDefinitionParsers或BeanDefinitionDecorators使用。
之后是对Spring命名空间的一些检测。
最后才是真正的解析BeanDefinitions——parseBeanDefinitions
/**
*解析文档中根级别的元素:
*“import”,“alias”,“bean”。
* @param root文档的DOM根元素
*/
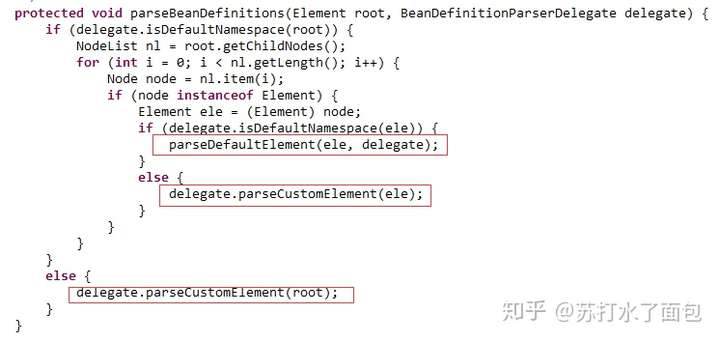
这里补充一点XML的知识
xml文档 —————-> Document对象 代表整个xml文档
节点 —————>Node对象 父类
标签节点 —————> Element对象 子类
属性节点 —————> Attribute对象 子类
文本节点 —————>Text对象 子类
NodeList ---------->节点列表集合(Node的集合)
先看这个默认命名空间的解析方法:
parseDefaultElement();

这里分别对<import> <alias> <bean><beans> 用各自的方法进行解析
这里的顺序也是比较讲究
先查看是否有<import>标签,如果有可以先引入其他资源文件到IOC容器中。
然后查看<alias>标签,如果有先引入别名到IOC容器中(后面会根据是否有id将别名赋值给bean)
然后查看<bean>标签
最后查看<beans>,可能<beans>里引入了其他<bean>,故在最后
这里我们查看对于 <bean>标签的解析:
processBeanDefinition();
/**
*处理给定的bean元素,解析beanDefinition
*并在注册表中注册。
*/
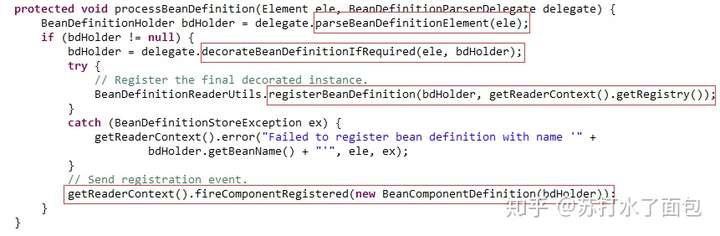
首先解析BeanDefinition的基本属性:
BeanDefinitionParserDelegate里的parseBeanDefinitionElement();