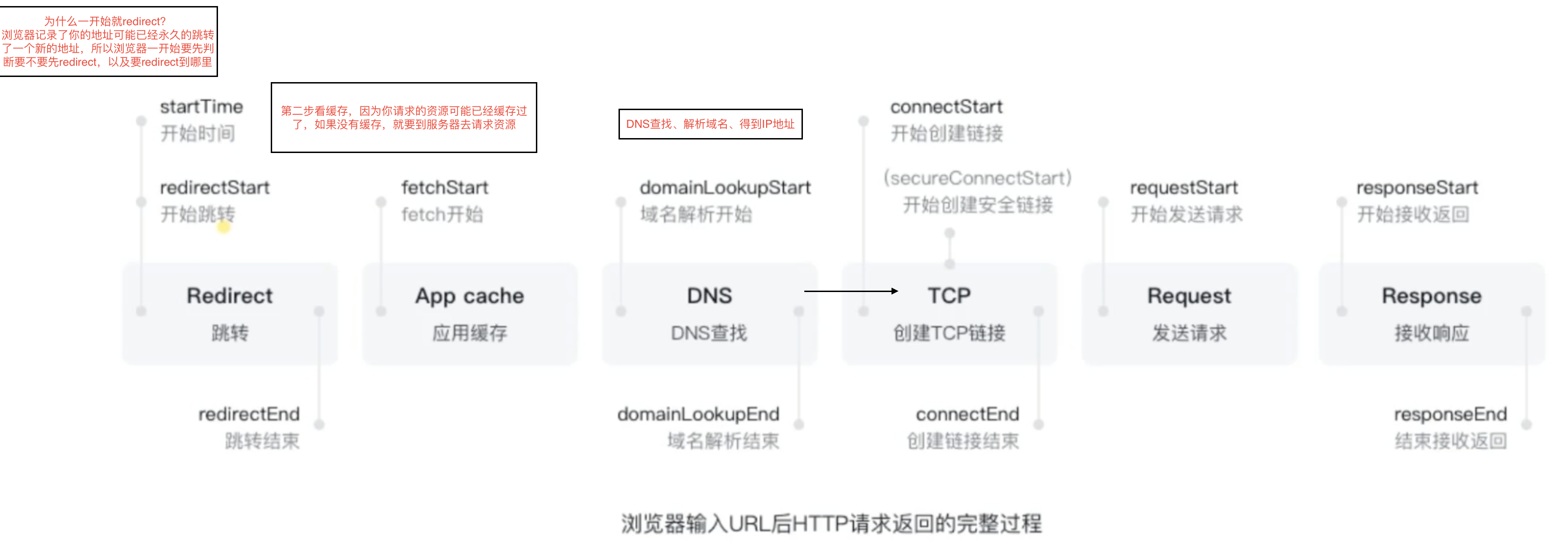
应用层:为应用软件提供了很多服务,构建于协议层,屏蔽网络传输相关细节
传输层:TCP、UPD协议,向用户提供可靠的端到端的服务,传输层向高层屏蔽了下层数据通信的细节
物理层:定义物理设备如何传输数据的(电脑,网线,光缆)
数据链路层:在通信实体间建立数据链路连接(软件服务,有了物理的连接,还需要软件的连接,这两边可以传输数据)
网络层:为数据在结点之间传输创建逻辑链路(电脑访问百度的服务器,那么如何查到百度的地址,这就是网络层的逻辑)
HTTP1.1:
持久连接、pipeline,参考https://www.cnblogs.com/chengdabelief/p/6686603.html
增加host和其他一些命令:host可以在同一台物理服务器上可以跑不同的服务(node、java),就可以通过host字段,指明,都是请求的是这台物理服务器上的服务,但是具体是哪个软件服务node还是Java,就是通过host来判断的
HTTP2.0:
所有数据以二进制传输,帧来传输(1.1是字符串),因此同一个连接里面发送的多个请求不再需要安装顺序来
头信息压缩(1.1中发送和响应的过程中,很多头信息都是需要完整的发送和返回的,但是其实很多的字段用字符串保存,占用带宽比较大,头压缩可以节约带宽)以及推送(服务端主动发送信息的,比如:HTML中有很多的CSS、JS文件都是引用进来,我们请求完HTML文件然后再根据文件里面的连接去请求css、js文件,这是按顺序的串行的,有了推送之后,发起HTML请求,再发送完HTML文件后,服务器会主动的将css 、js文件返回,而不需要你再发送请求,这就是并行的)等提高效率的功能
URI: 用来唯一标示互联网上的信息资源,包括URL和URN
URL:统一资源定位器
URN:永久统一资源定位符,普通的情况,要是资源移动了,就会返回404,但是URN情况下,资源移动之后还能被找到,URN始终指向那个资源

method: get(获取这个数据)、put(更新这个数据)、post(创建这个数据)、delete(删除这个数据)
跨域:
请求是已经发送了,浏览器是会发送这个请求的,服务器也返回了,浏览器也接受了返回内容,只是浏览器发现,返回的内容没有'Access-Control-Allow-Origin':'*'所以浏览器忽略返回的结果,这是浏览器提供的功能。
比如:有三个文件server.js,server2.js,test.html
//server.js
const http = require('http')
const fs = require('fs')
http.createServer(function (request, response){
console.log('request come', request.url)
const html = fs.readFileSync('test.html', 'utf8')
response.writeHead(200, {
'Content-Type': 'text/html'
})
response.end(html)
}).listen(8888)
console.log('server listening on 8888')
//server2.js
const http = require('http')
http.createServer(function (request, response){
console.log('request come', request.url)
response.writeHead(200, {
'Access-Control-Allow-Origin': 'http://127.0.0.1:8888'//test.html//发起对server2的请求,通过在server2这个服务器上设置’Access-Control-Allow-Origin‘设置对应发起请求的地址允许请求的发起
})
response.end('123')
}).listen(8887)
console.log('server listening on 8887')
<!-- test.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
</body>
<script>
var xhr = new XMLHttpRequest()
xhr.open('GET', 'http://127.0.0.1:8887/')
xhr.send()
</script>
</html>
CORS预请求:
跨域的时候,默认允许的方法只有:get,head,post,其他的默认不允许,浏览器有一个预请求会去验证的。也就是说这三个不需要预请求验证,其他的方法需要预请求验证。
允许Content-Type:text/plain,multipart/form-data,application/x-www-form-urlencoded,这几个不需要预请求,其他的都需要。
预请求例子如下:
server.js不变
server2.js变成如下:
//server2.js const http = require('http') http.createServer(function (request, response){ console.log('request come', request.url) response.writeHead(200, { 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Headers': 'X-Test-Cors', 'Access-Control-Allow-Methods': 'POST,PUT,Delete', 'Access-Control-Max-Age': '1000' }) response.end('123') }).listen(8887) console.log('server listening on 8887')
test.html改成如下:
<!-- test.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
</body>
<script>
fetch('http://localhost:8887',{
method: 'PUT', method: 'PUT',//本来默认情况下,跨域只允许get,post,header请求,但是因为server2.js已经设置了'Access-Control-Allow-Methods': 'POST,PUT,Delete',因此不会报错
headers: {
'X-Test-Cors': '123'//本来默认情况下,跨域不允许自定义请求头,但是因为server2.js已经设置了'Access-Control-Allow-Headers': 'X-Test-Cors',,因此不会报错
}
})
</script>
</html>
更加详细的解释参考:http://www.ruanyifeng.com/blog/2016/04/cors.html
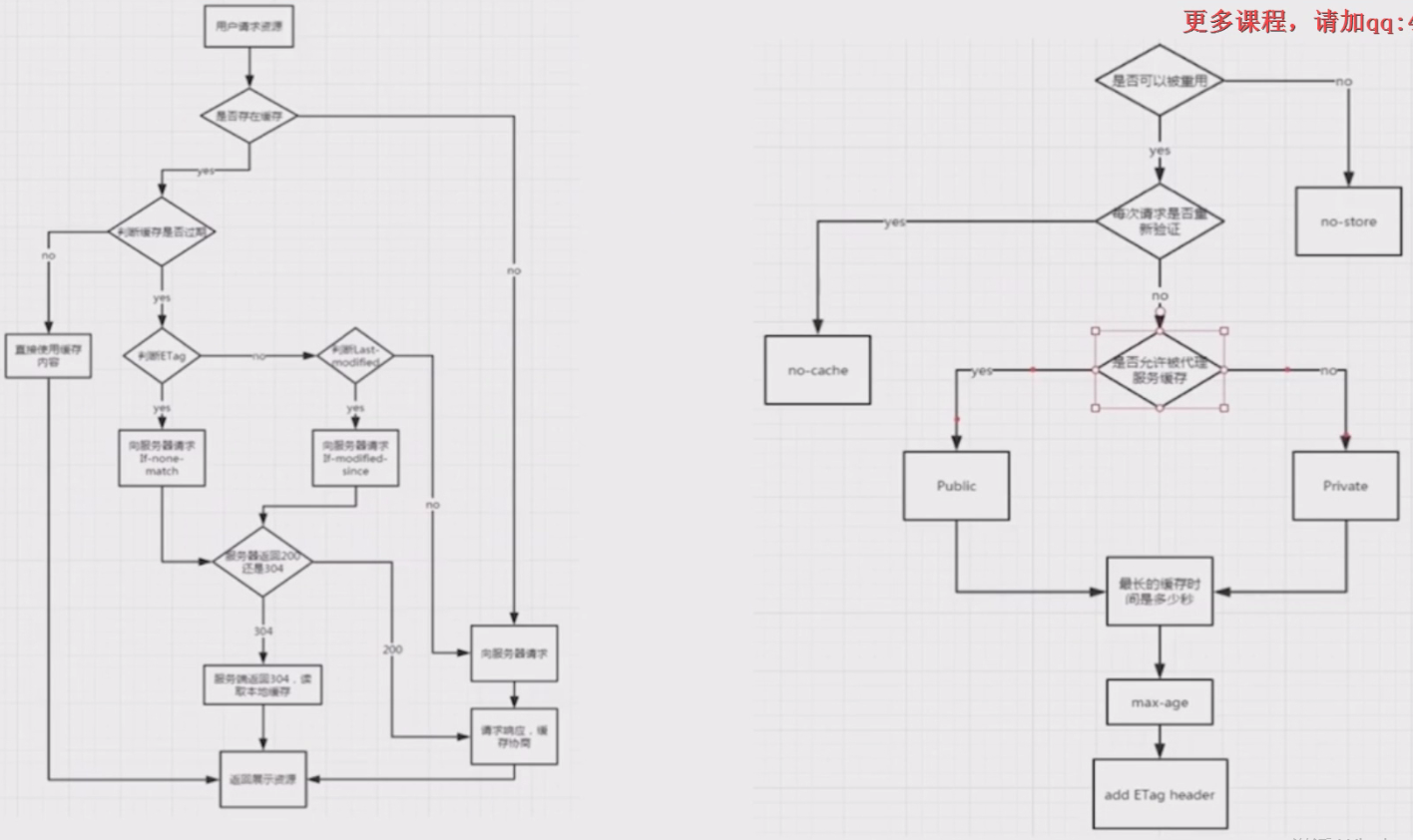
Cache-Control可缓存性
public:HTTP经过的任何地方,任何代理都可以缓存
private:只有发起请求的浏览器可以缓存
no-cache:你可以在本地,proxy服务器缓存,每次都需要去源服务器验证一下,如果服务器告诉你可以使用本地的缓存,你才可以使用本地的缓存
no-store:彻底的,本地,代理服务器都不可以缓存,每次都需要去服务器拿资源。
no-transform:某些资源可能很多,某些服务器可能会去压缩,no-transform 就是用来告诉代理服务器不要去压缩等的transform
max-age:代表缓存的最长时间。如果cache-control中有max-age,同时又有Last-modified,那么只有当max-age过期了,才会通过Last-modified进行缓存协商,因为max-age就是服务端告诉客户端的,所以max-age优先。
s-maxage:s-maxage是在代理服务器里面的,如果max-age和s-maxage都设置了,那么在代理服务器里面会用s-maxage代理max-age,但是浏览器里面还是max-age
max-stale:就是说即使缓存已经过期了,但是只要还在max-stale的时间段内,就会用发起请求一方的过期的缓存
must-revalidate:如果已经过期了,那么必须再去源服务端去请求,获取资源然后再沿验证是不是真的过期了,而不能直接使用缓存
proxy-revalidate:用在缓存服务器中的,如果已经过去那么必须再去源服务端去请求,获取资源然后再沿验证是不是真的过期了,而不能直接使用缓存
在浏览器中用到的有:public、private、no-cache,max-age,must-revalidate
如果设置了max-age,如果在max-age时间期间静态资源发生了改变,但是这时候浏览器还是会从缓存中读取资源,而不会去请求最新的资源,这样就矛盾了,如何解决尼?设置了max-age后,利用hash原理实现动态缓存静态资源文件,根据打包好的静态资源,计算出一个hash码,当静态资源变化了,hash码就发生了变化。URL就发生变化了,这样就会去请求新的资源。
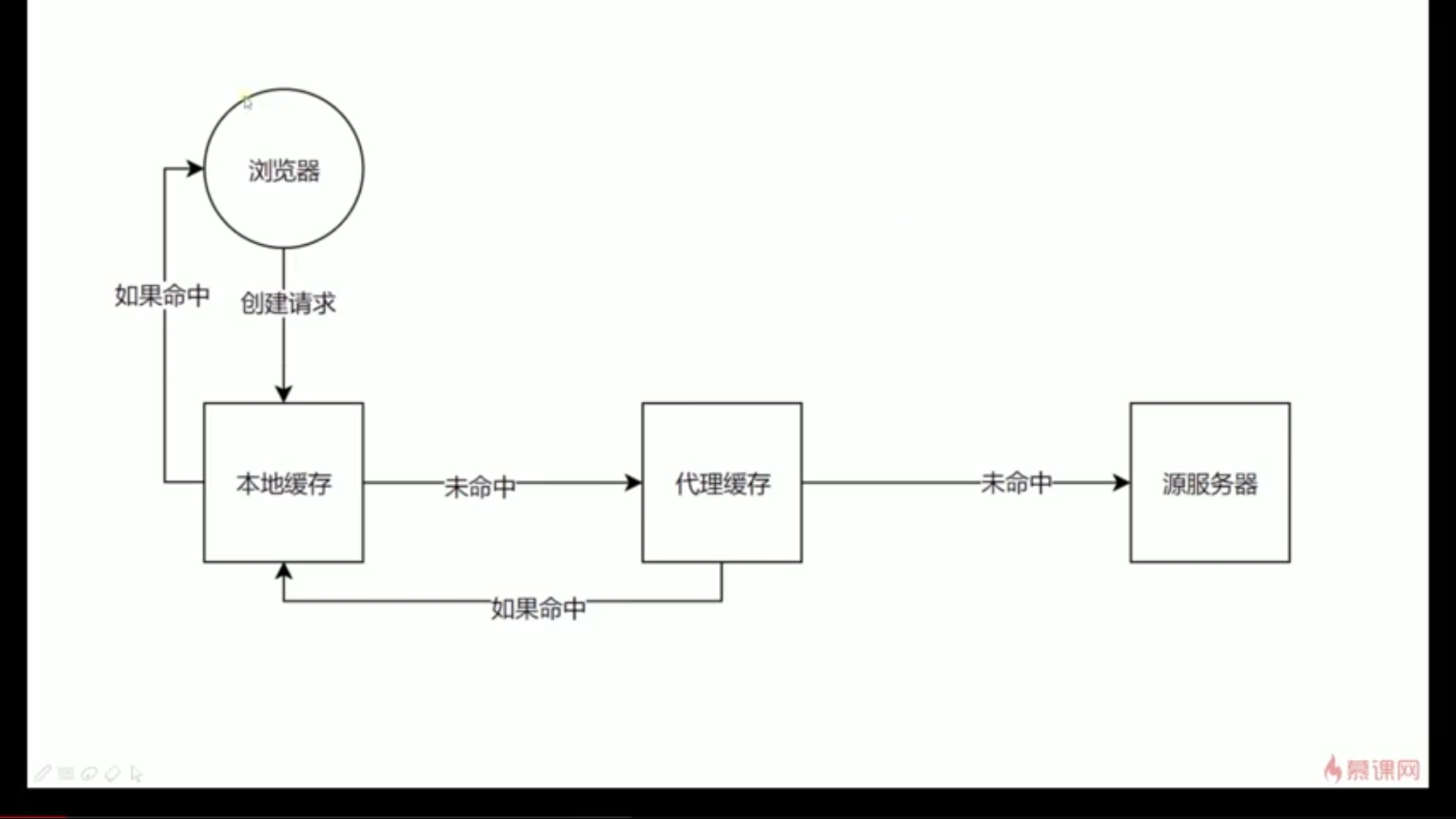
如果是‘Cache-Control’:‘no-cache’,那么每次请求资源,都需要去服务器问一问,验证一下资源有没有更新,那么如何验证?有两种验证方式:
第一种:通过Last-modified和if-modified-since,当第一次请求时,服务器会把last-modified发送给浏览器,当浏览器发起第二次请求时,浏览器会用if-modified-since带上之前的last-modified,然后服务器验证浏览器的request中的if-modified-since和服务器保持的last-modified是否一致,如果一致,那么就不需要返回资源返回304(即使返回资源,浏览器也会从缓存中读取数据,而不是使用返回的资源,因为浏览器会通过304这个有语义的状态码得知没有改变,使用原来的缓存),如果不一致就返回新的资源,返回200状态码。
Last-modified有什么缺点:
- 某些服务端不能获取精确的修改时间
- 文件修改时间改了,但是文件内容却没有变
第二种,就是通过Etag和If-Match,和上面的道理是一样的。
上面的验证是基于‘Cache-Control’:‘no-cache’的,才这样验证,如果‘Cache-Control’:‘no-store’,那么就是真正的不会缓存了
可以参考:https://blog.csdn.net/lqlqlq007/article/details/79940017

缓存流程:
HTTP长连接
浏览器的Connection-id是查看创建的TCP连接的ID
HTTP1.1 浏览器允许并发的创建TCP连接,Chrome可以并发创建6个TCP连接,但是在一个TCP连接上只能一个接一个的发送请求,不能一次并发的发送多个请求
'Connection':'keep-alive'长连接,就是TCP连接不会关闭,会不断的复用
HTTP2.0在一个域里面用一个TCP 连接,这个TCP连接允许并发的发送请求
Cookie和Session
什么是cookie?服务器返回的Set-Cookie(键值对)这个header字段,然后保持在浏览器中的一个内容。然后在下次同域请求数据时带上这个cookie。键值对,可以设置多个。服务器端发现客户端发送过来的Cookie后,会去检查究竟是从哪一个客户端发送来的连接请求,然后对比服务器上的记录,最后得到之前的状态信息
属性:
max-age(你这个cookie的有效时间有多长),和expires(到什么时间点过期)设置过期时间
Secure表示cookie只有在https请求的时候才会发送
HttpOnly设置了之后,禁止用JavaScript访问就无法通过document.cookie进行访问,可以防止CSRF攻击。
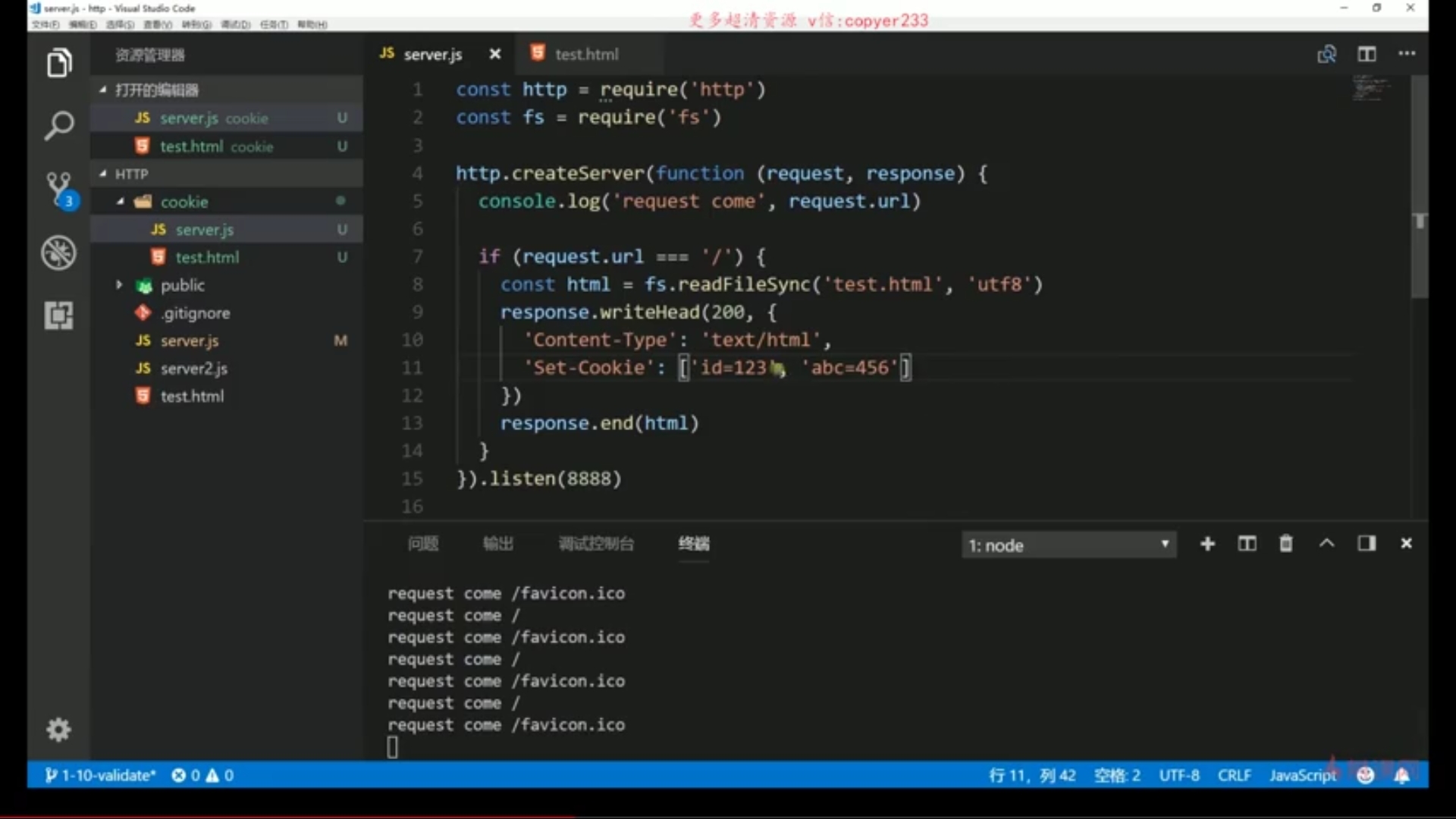
可以用domain设置主域名下的所有二级域名都是可以访问的: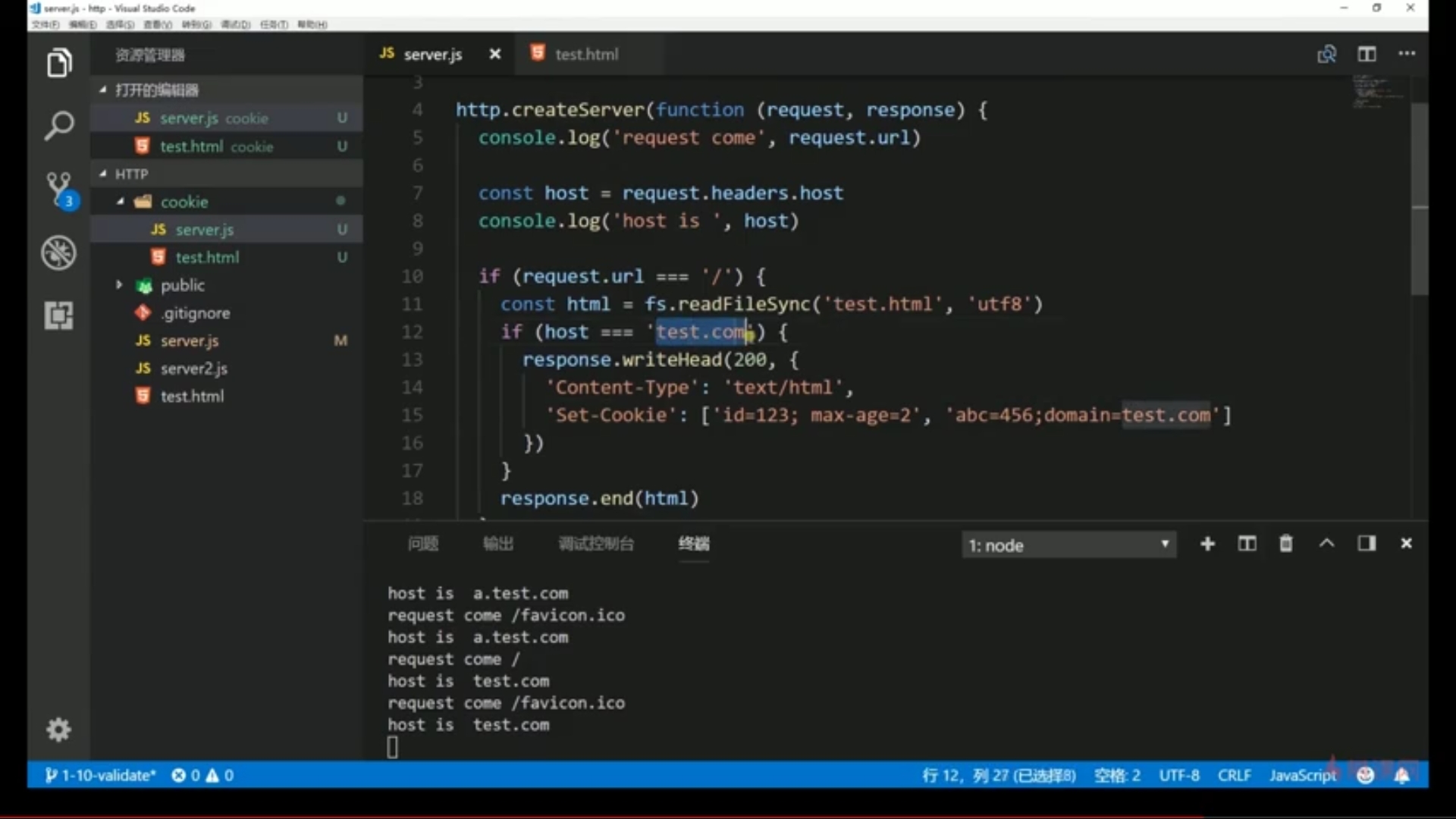
数据协商:
请求:
Accept:想要的数据类型
Accept-Encoding:数据的压缩方式
Accept-Language:想要返回的数据的语言,中文、英文
User-Agent:声明自己是什么环境,PC还是移动端,想要返回的是PC端的页面还是移动端的页面
响应:
Content-Type:从Accept选择一种数据格式返回,告诉说返回了什么样的数据格式,text/plain,text/html,image/jpeg,image/png,application/json,application/javascript,video/*,video/mp4,application/x-www-form-urlencoded(https://www.cnblogs.com/gamedaybyday/p/7028128.html),multipart/form-data(表单提交多种数据类型,文件,图片,字符串等)


Content-Encoding:deflate,gzip,br,compress(UNIX系统的标准压缩),identity(不进行编码)声明返回的数据是以什么方式压缩的在浏览器里面的Size包含两个值,上面的值是整个返回的数据(header+body)被压缩后传输过程中的数据,下面的是body到了浏览器后解压后的body数据。
Content-Language:声明返回的语言
重定向:
当资源的路径已经修改了,但是浏览器不知道,仍然按照原来的路径访问,这是后服务器端要进行重定向,告诉浏览器地址已经变了。302有语义(要跳转)如果改成200是不会跳转的,通过Location进行直接跳转,同一个域所以不需要host
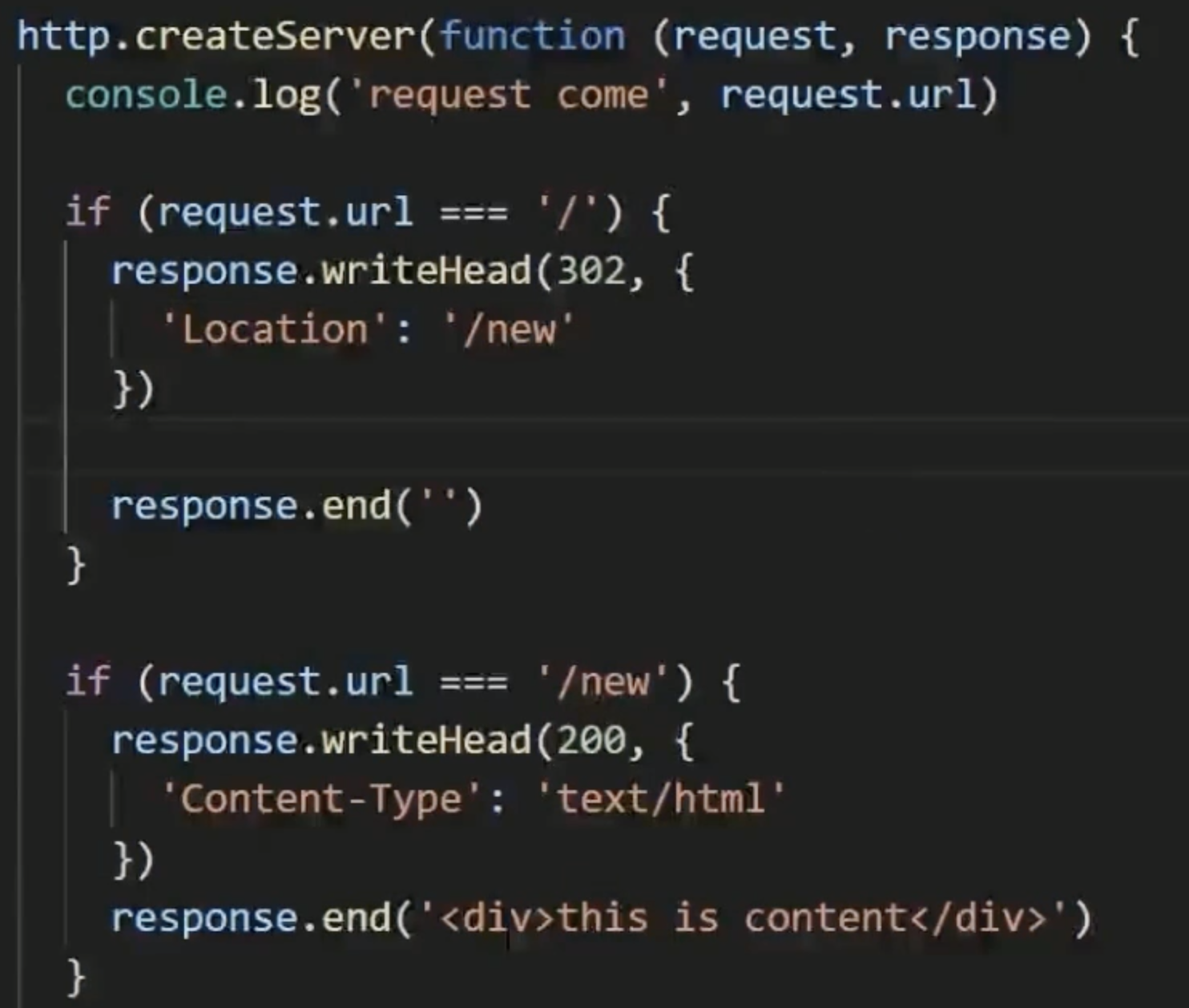
301与302区别:
301是永久重定向,302是临时性重定向,采用302的时候,用户每次输入原来的地址发起请求,都会有两次请求,一次是原来的地址的请求,然后跳转进行第二次请求,第二次是重定向地址的请求。301的时候第一次会有两次请求,一次是原来的地址的请求,然后跳转进行第二次请求,第二次是重定向地址的请求。但是当第二次用户再输入同样的原来的地址的时候,只有一次请求,就是重定向地址的请求,因为浏览器会进行缓存,记住了这个重定向地址,每次用户输入原来的地址在浏览器上就进行了重定向,直接跳转到缓存的地址上了,而不需要再发送到服务器上进行重定向。这个缓存还时间比较长,因此要用301的时候慎重,这是不能反悔的。
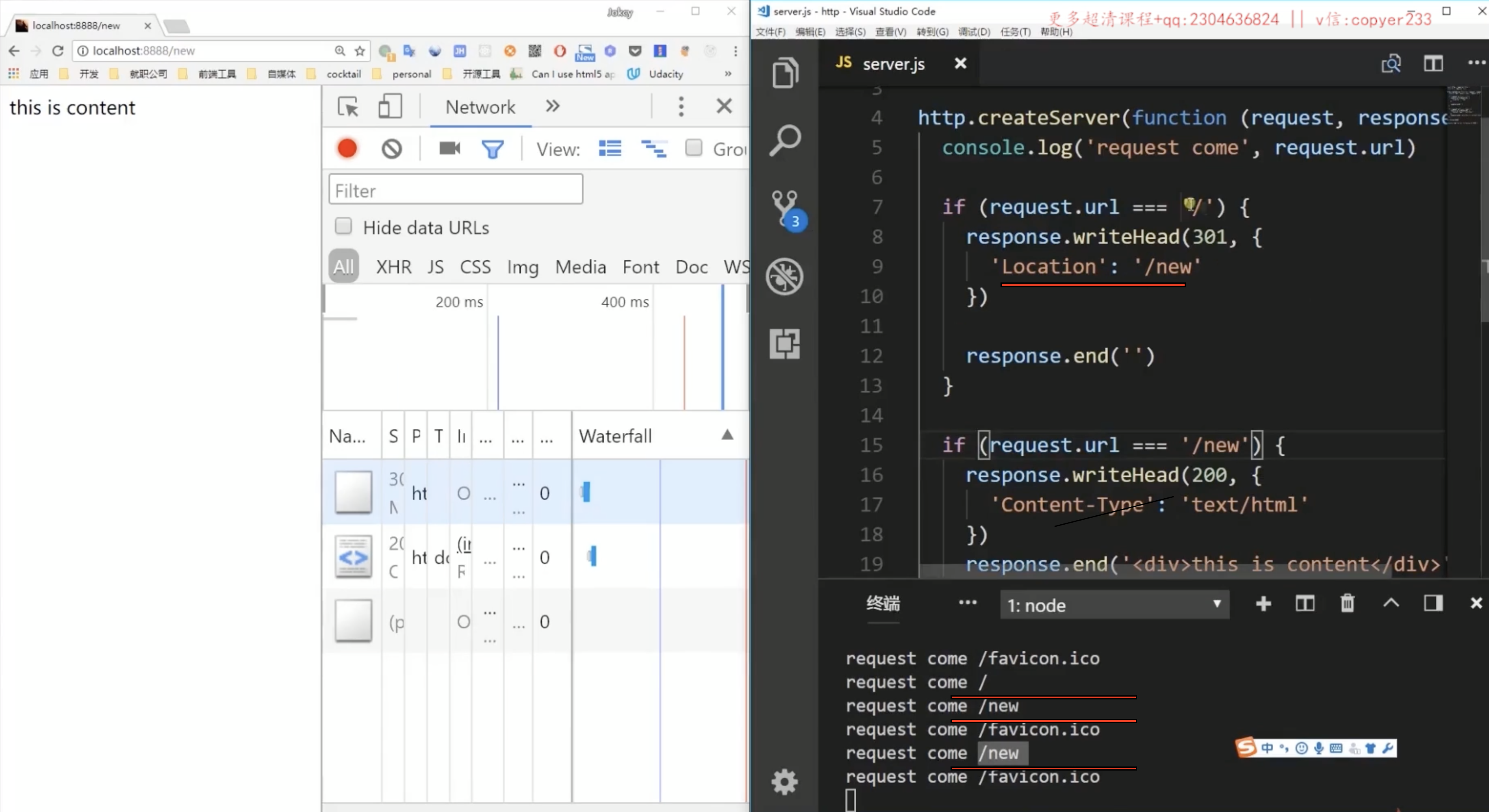
302和303区别:

307和302区别:

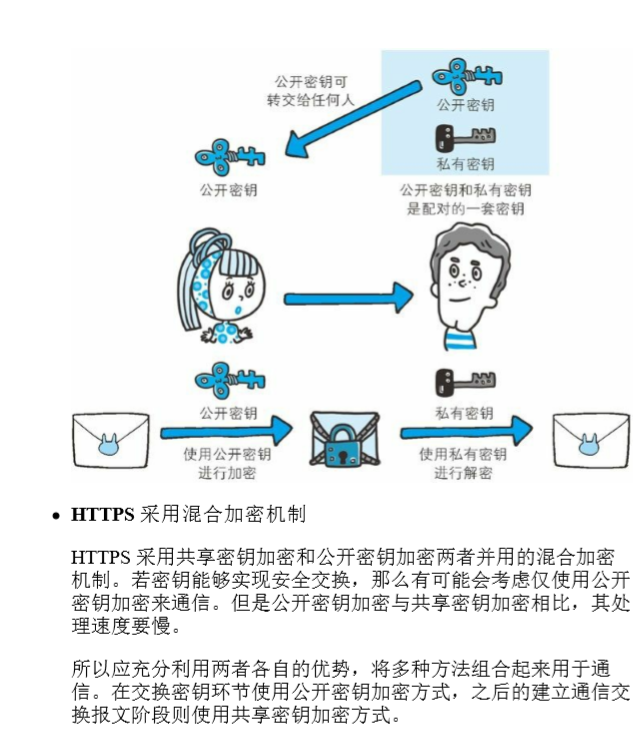
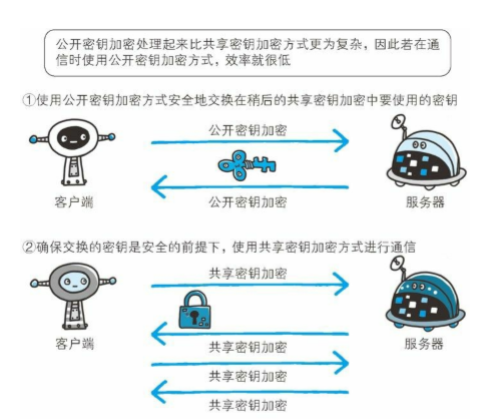
HTTPS
公钥(互联网上所有人都可以拿到的),私钥是在握手的时候进行传输
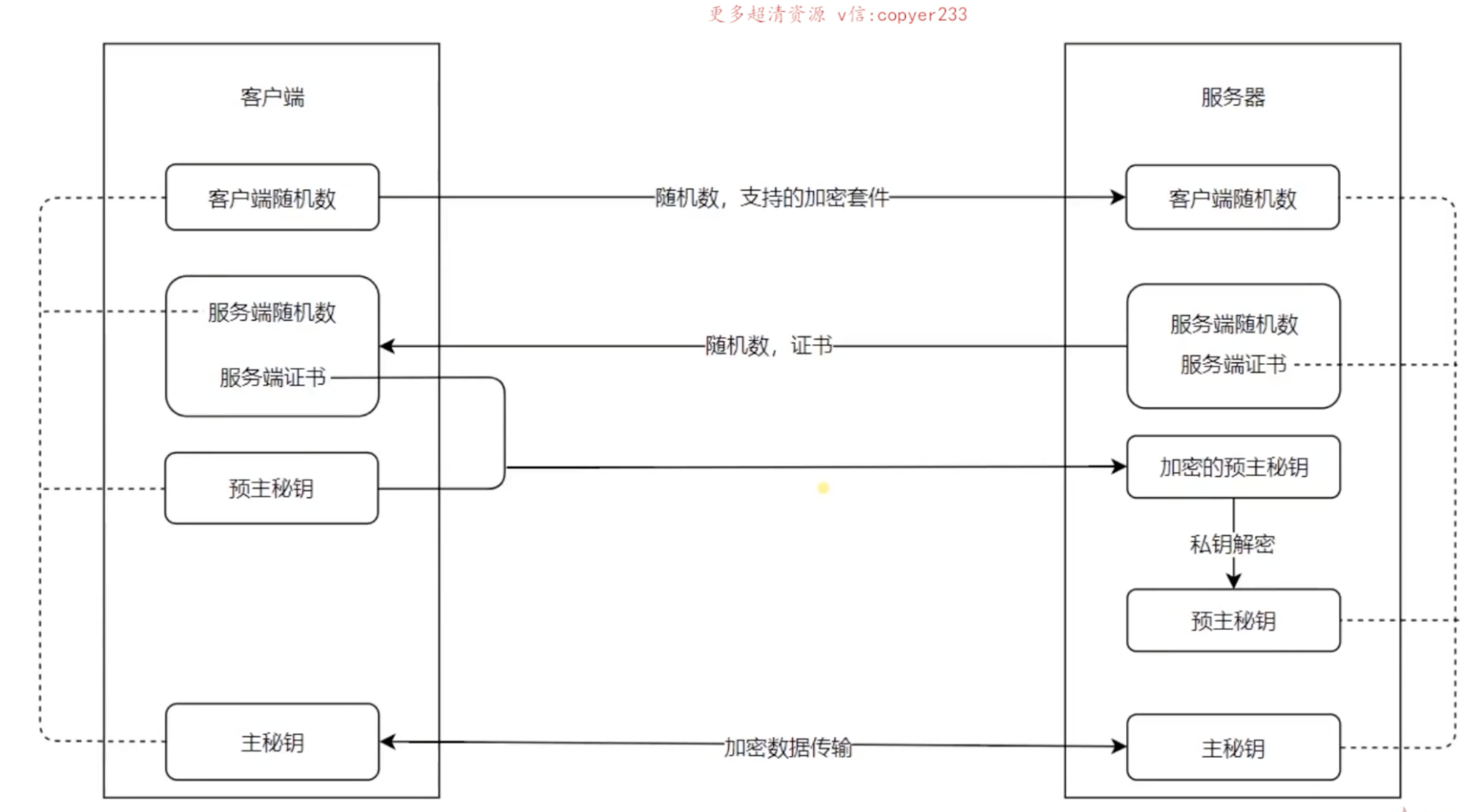
过程:
1、客户端生成随机数,发送给服务器,带上支持的加密套件,因为服务器有很多加密的方法
2、服务端把客户端的随机数先存着,然后服务端也生成随机数,发送给客户端,带上服务端证书(公钥)
3、客户端拿到服务端的随机数也先存着,然后通过服务端证书(公钥)生成预主秘钥,生成过程中也会有一个随机数,随机数被加密后传输给服务器这里
4、服务器私钥解密得到预主秘钥。
5、客户端和服务端对这三个随机数进行算法操作,生成主秘钥。因此两边的主秘钥是一样的,可以用来加密解密。
HTTP2
信道复用
分帧传输:每一帧,谁先到,谁后到没有关系,等所有帧到了,会根据帧信息进行重新组合,因此可以在一个TCP连接里面并发的发送不同的请求
服务器推送
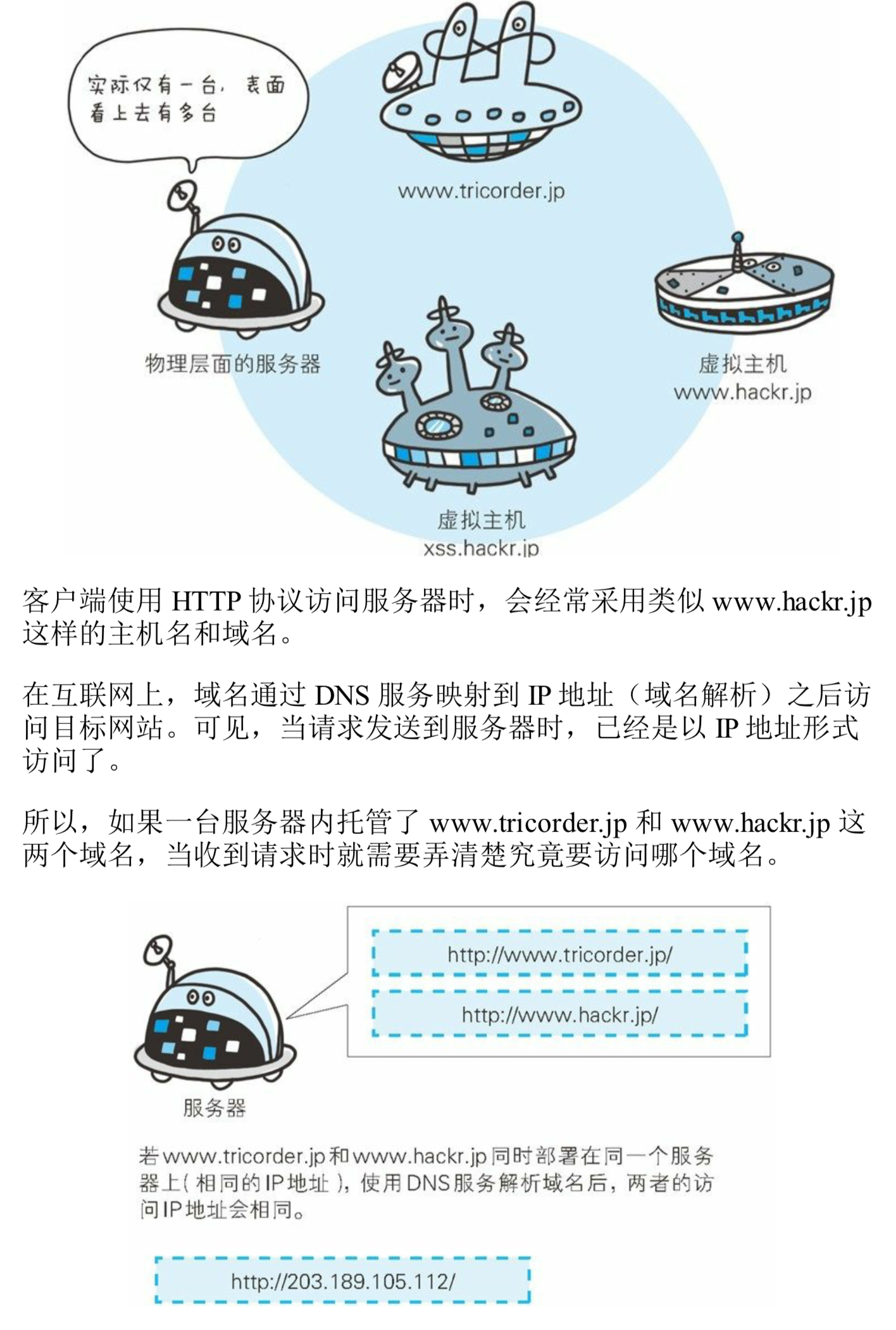
单台虚拟机实现多个域名
Host:https://blog.csdn.net/u012111465/article/details/79779550


通信数据转发程序:代理、网关、隧道:
