一、JDBC常用的API深入详解及存储过程的调用
相关链接:Jdbc调用存储过程
1、存储过程(Stored Procedure)的介绍
我们常用的操作数据库语言SQL语句在执行的时候需要先编译,然后执行,而存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。
一个存储过程是一个可编程的函数,它在数据库中创建并保存。它可以有SQL语句和一些特殊的控制结构组成。当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟。它允许控制数据的访问方式。
存储过程通常有以下优点:
(1).存储过程增强了SQL语言的功能和灵活性。存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
(2).存储过程允许标准组件是编程。存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
(3).存储过程能实现较快的执行速度。如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
(4).存储过程能过减少网络流量。针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。
(5).存储过程可被作为一种安全机制来充分利用。系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
简单来说它的好处主要是:
1.由于数据库执行动作时,是先编译后执行的。然而存储过程是一个编译过的代码块,所以执行效率要比T-SQL语句高。
2.一个存储过程在程序在网络中交互时可以替代大堆的T-SQL语句,所以也能降低网络的通信量,提高通信速率。
3.通过存储过程能够使没有权限的用户在控制之下间接地存取数据库,从而确保数据的安全。
2、JDBC调用无参存储过程
在数据库新建存储过程:
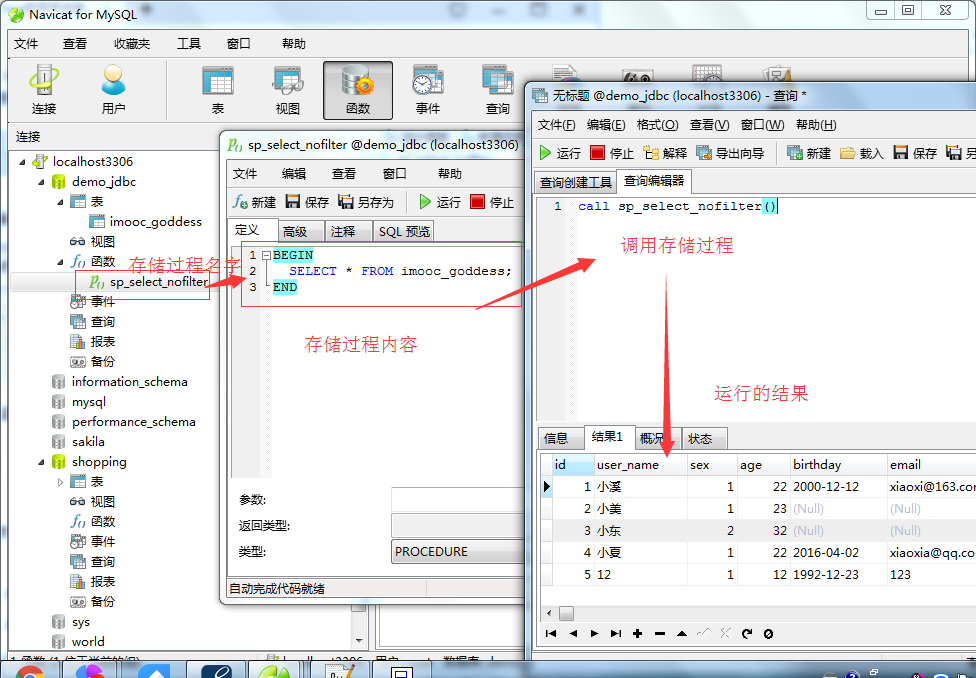
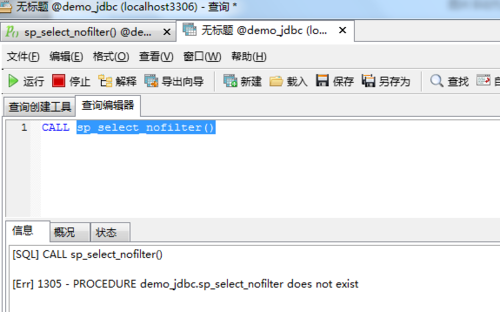
注意:创建的存储过程名称不要加“()”,不然在调用存储过程时会提示如下错误:
代码示例:ProduceDao.java
1 package com.study.dao; 2 3 import java.sql.CallableStatement; 4 import java.sql.Connection; 5 import java.sql.ResultSet; 6 import java.sql.SQLException; 7 8 import com.study.db.DBUtil; 9 10 /** 11 * @Description: 存储过程 12 * @author: Qian 13 * @date: 2016-4-3 下午4:15:24 14 */ 15 public class ProduceDao { 16 public static void select_nofilter() throws SQLException{ 17 //1.获得连接 18 Connection conn = DBUtil.getConnection(); 19 //2.获得CallableStatement 20 CallableStatement cs = conn.prepareCall("call sp_select_nofilter()"); 21 //3.执行存储过程 22 cs.execute(); 23 //4.处理返回的结果:结果集,出参 24 ResultSet rs = cs.getResultSet(); 25 /*遍历结果集*/ 26 while(rs.next()){ 27 System.out.println(rs.getString("user_name")+":"+rs.getString("email")); 28 } 29 } 30 }
JDBCTestProduce.java
1 package com.study.test; 2 3 import java.sql.SQLException; 4 5 import com.study.dao.ProduceDao; 6 7 /** 8 * @Description: 测试存储过程 9 * @author: Qian 10 * @date: 2016-4-3 下午4:24:10 11 */ 12 public class JDBCTestProduce { 13 public static void main(String[] args) throws SQLException { 14 ProduceDao dao=new ProduceDao(); 15 dao.select_nofilter(); 16 } 17 }
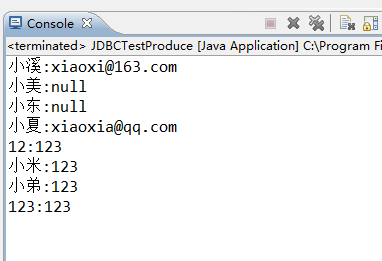
运行结果:
3、JDBC调用含输入参数存储过程
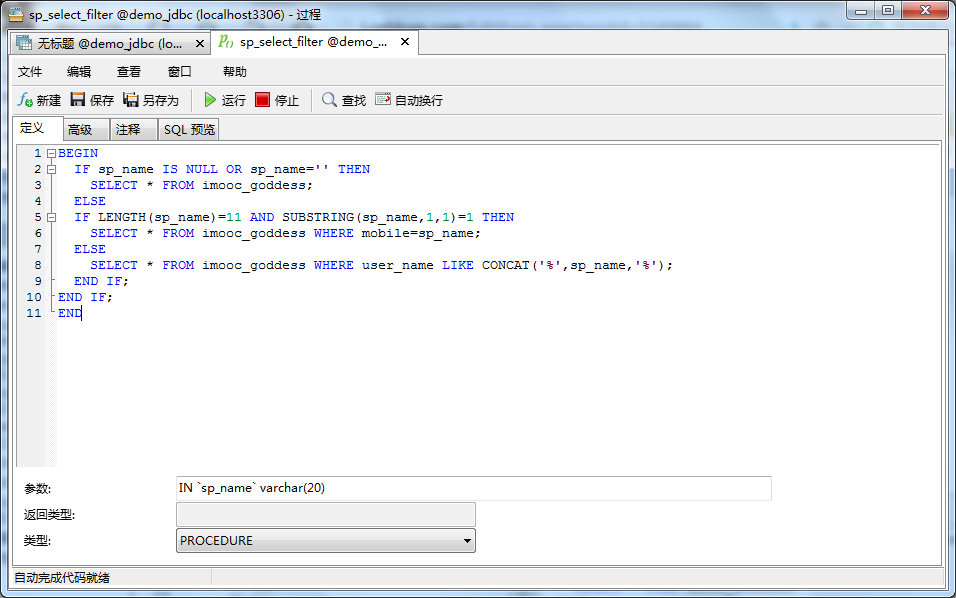
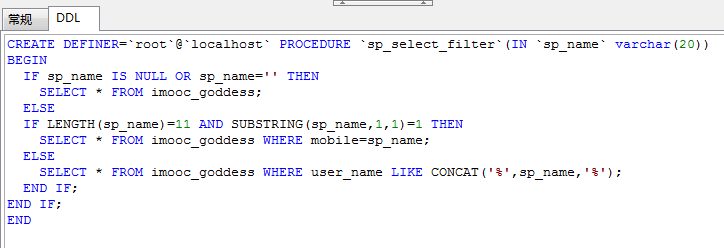
调用存储过程:传个空字符
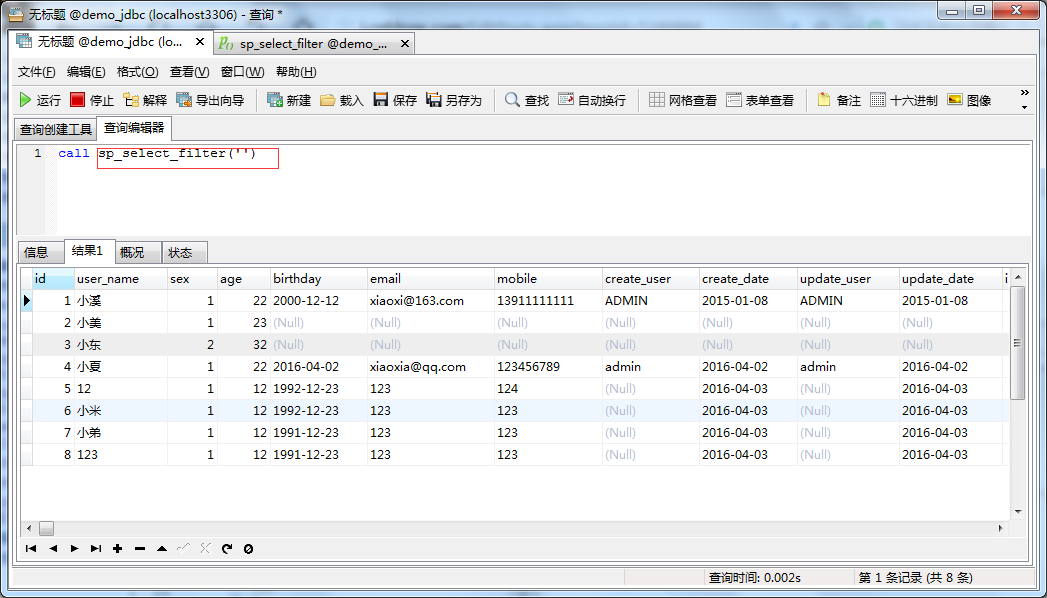
传个“小”
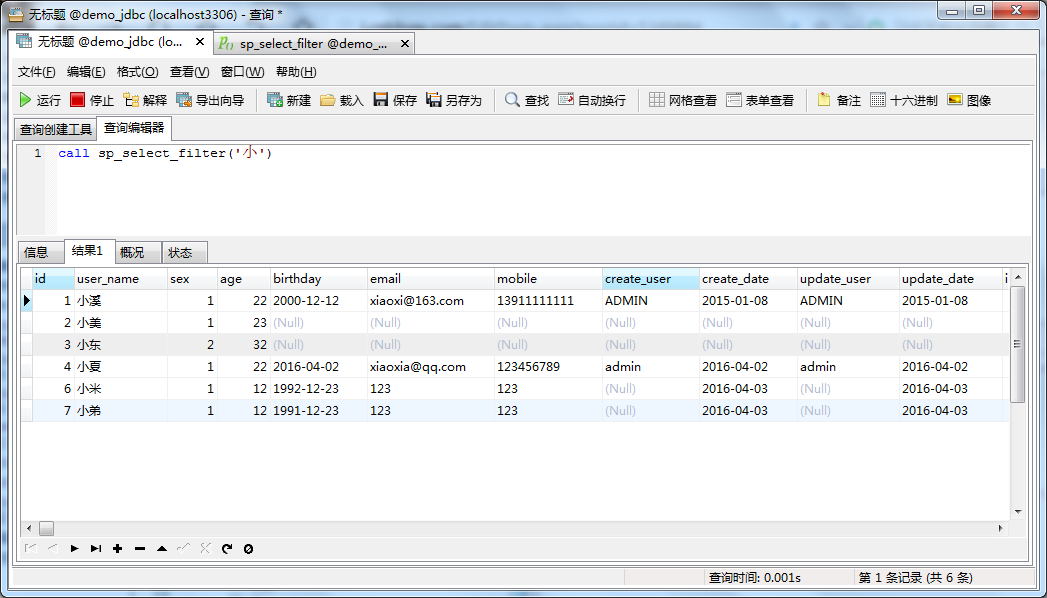
1 //JDBC 调用带输入参数的存储过程 2 public static List<Goddess> select_filter(String sp_name) throws SQLException{ 3 List<Goddess> result=new ArrayList<Goddess>(); 4 //1.获得连接 5 Connection conn = DBUtil.getConnection(); 6 //2.获得CallableStatement 7 CallableStatement cs = conn.prepareCall("call sp_select_filter(?)"); 8 cs.setString(1, sp_name); 9 //3.执行存储过程 10 cs.execute(); 11 //4.处理返回的结果:结果集,出参 12 ResultSet rs = cs.getResultSet(); 13 Goddess g=null; 14 while(rs.next()){//如果对象中有数据,就会循环打印出来 15 g=new Goddess(); 16 g.setId(rs.getInt("id")); 17 g.setUserName(rs.getString("user_name")); 18 g.setAge(rs.getInt("age")); 19 result.add(g); 20 } 21 return result; 22 }
测试:
1 public class JDBCTestProduce { 2 public static void main(String[] args) throws SQLException { 3 ProduceDao dao=new ProduceDao(); 4 // dao.select_nofilter(); 5 String sp_name=""; 6 List<Goddess> res=null; 7 res=dao.select_filter(sp_name); 8 for (int i = 0; i < res.size(); i++) { 9 System.out.println(res.get(i).getId()+":"+res.get(i).getUserName()+":"+res.get(i).getAge()); 10 11 } 12 } 13 }
4、JDBC调用含输出参数存储过程

调用存储过程:
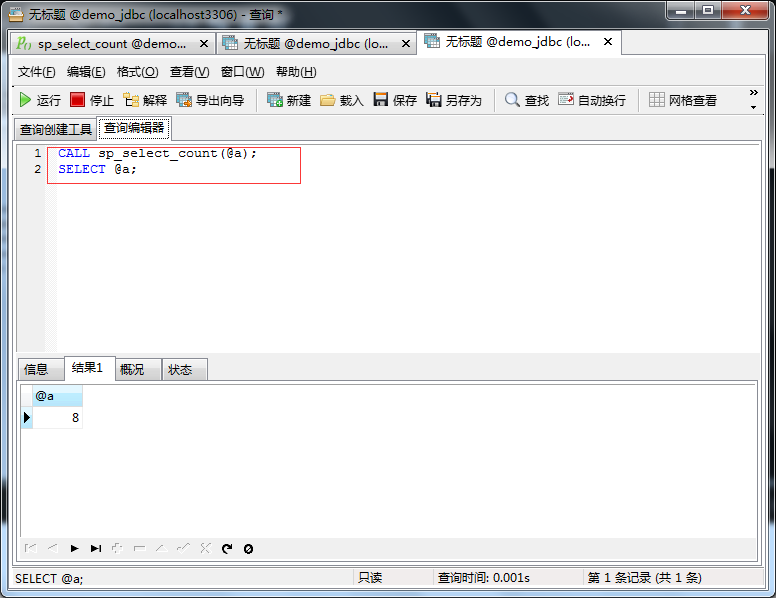
1 //JDBC 调用含输出参数存储过程 2 public static Integer select_count() throws SQLException{ 3 Integer count=0; 4 //1.获得连接 5 Connection conn = DBUtil.getConnection(); 6 //2.获得CallableStatement,prepareStatement,statement 7 CallableStatement cs = conn.prepareCall("call sp_select_count(?)"); 8 cs.registerOutParameter(1, Types.INTEGER);//注册输出参数,第二个参数是告诉JDBC,输出参数的类型 9 //3.执行存储过程 10 cs.execute(); 11 //4.处理返回的结果:这个不是结果集,是出参 12 count=cs.getInt(1); 13 return count; 14 }
测试:
1 package com.study.test; 2 3 import java.sql.SQLException; 4 import java.util.List; 5 6 import com.study.dao.ProduceDao; 7 import com.study.model.Goddess; 8 9 /** 10 * @Description: 测试存储过程 11 * @author: Qian 12 * @date: 2016-4-3 下午4:24:10 13 */ 14 public class JDBCTestProduce { 15 public static void main(String[] args) throws SQLException { 16 // ProduceDao dao=new ProduceDao(); 17 // dao.select_nofilter(); 18 /*String sp_name=""; 19 List<Goddess> res=null; 20 res=dao.select_filter(sp_name); 21 for (int i = 0; i < res.size(); i++) { 22 System.out.println(res.get(i).getId()+":"+res.get(i).getUserName()+":"+res.get(i).getAge()); 23 24 }*/ 25 String sp_name="小"; 26 List<Goddess> res=null; 27 Integer count=0; 28 //带输入参数的存储过程 29 /*res=select_filter(sp_name); 30 showResult(res);*/ 31 count=select_count(); 32 System.out.println(count); 33 } 34 35 public static List<Goddess> select_filter(String sp_name) throws SQLException{ 36 ProduceDao dao=new ProduceDao(); 37 return dao.select_filter(sp_name); 38 } 39 public static Integer select_count() throws SQLException{ 40 ProduceDao dao=new ProduceDao(); 41 return dao.select_count(); 42 } 43 44 public static void showResult(List<Goddess> result){ 45 for (int i = 0; i < result.size(); i++) { 46 System.out.println(result.get(i).getId()+":"+result.get(i).getUserName()+":"+result.get(i).getAge()); 47 48 } 49 } 50 }
二、JDBC的事务管理
事务的概念:
事务(transaction)是作为单个逻辑工作单元执行的一系列操作。这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行。
事务的特点:
1、原子性(Atomicity)
事务是一个完整的操作。不能对它进行再分割,是最小的一个单元。
2、一致性(Consistency)
当事务完成时,数据必须处于一致状态。
(例如银行转账,张三要给李四转100元。则第一步张三的账户需要减去100元,第二步李四的账户需要加上100元。这是两个操作,但是应该在一个事务里面。如果没有在一个事务里面,张三减去100,李四并没有增加100,那这样数据就出现了不一致性,张三的钱跑哪去了呢 )
3、隔离性(Isolation)
对数据进行修改的所有并发事务是彼此隔离的。
(比如业务A:张三减100,李四加100;同时业务B也是张三减100,李四加100进行操作。业务A和B是同时的,这时候就出现了并发,这个时候是怎么变化的呢?当业务员A进行操作的时候,业务员B就要等待……就是同一时间对数据库的操作要保持一个事务的锁定。也就是说我在做的时候,别人是不能做的。我做完了之后别人才能做,彼此之间是隔离的)
4、永久性(Durability)
事务完成后,它对数据库的修改被永久保持。
1、JDBC实现事务管理
①我们通过提交commit()或是回退rollback()来管理事务的操作。
当事务完成的时候,我们通过commit将事务提交到数据库之中,然后数据库会变成持久化的,我们的数据就会永久保存了。
如果采用rollback的话,事务回滚,比如说我们插入的数据、更新的数据都会变成原来没有更新、没有插入时的样子。
②事务操作默认是自动提交
当我们调用完insert语句,不用调用commit语句,自己就提交了。
③可以调用setAutoCommit(false) 来禁止自动提交。
2、通过代码实现事物的管理
首先我们要注意,在JDBC中,事务操作默认是自动提交。也就是说,一条对数据库的更新表达式代表一项事务操作。操作成功后,系统将自动调用commit()来提交,否则将调用rollback()来回退。
其次,在JDBC中,可以通过调用setAutoCommit(false)来禁止自动提交。之后就可以把多个数据库操作的表达式作为一个事务,在操作完成 后调用commit()来进行整体提交。倘若其中一个表达式操作失败,都不会执行到commit(),并且将产生响应的异常。此时就可以在异常捕获时调用 rollback()进行回退。这样做可以保持多次更新操作后,相关数据的一致性。
try { conn = DriverManager.getConnection("jdbc:microsoft:sqlserver://localhost:1433;User=JavaDB;Password=javadb;DatabaseName=northwind); //点禁止自动提交,设置回退 conn.setAutoCommit(false); stmt = conn.createStatement(); //数据库更新操作1 stmt.executeUpdate(“update firsttable Set Name='testTransaction' Where ID = 1”); //数据库更新操作2 stmt.executeUpdate(“insert into firsttable ID = 12,Name = 'testTransaction2'”); //事务提交 conn.commit(); }catch(Exception ex) { ex.printStackTrace(); try { //操作不成功则回退 conn.rollback(); }catch(Exception e){ e.printStackTrace(); } }
这样上面这段程序的执行,或者两个操作都成功,或者两个都不成功,读者可以自己修改第二个操作,使其失败,以此来检查事务处理的效果。
我们在前面还提到了JDBC对事务所支持的隔离级别,下面将更详细进行讨论。
JDBC API支持事务对数据库的加锁,并且提供了5种操作支持,2种加锁密度。
5种加锁支持为:
static int TRANSACTION_NONE = 0;
static int TRANSACTION_READ_UNCOMMITTED = 1;
static int TRANSACTION_READ_COMMITTED = 2;
static int TRANSACTION_REPEATABLE_READ = 4;
static int TRANSACTION_SERIALIZABLE = 8;
具体的说明见表4-2。
2种加锁密度:
最后一项为表加锁,其余3~4项为行加锁。
“脏”数据读写(Dirty Reads):当一个事务修改了某一数据行的值而未提交时,另一事务读取了此行值。倘若前一事务发生了回退,则后一事务将得到一个无效的值(“脏”数据)。
重复读写(Repeatable Reads):当一个事务在读取某一数据行时,另一事务同时在修改此数据行。则前一事务在重复读取此行时将得到一个不一致的值。
错 误(映像)读写(Phantom Reads):当一个事务在某一表中进行数据查询时,另一事务恰好插入了满足了查询条件的数据行。则前一事务在重复读取满足条件的值时,将得到一个额外的 “影像”值。JDBC根据数据库提供的默认值来设置事务支持及其加锁,当然,也可以手工设置:
setTransactionIsolation(TRANSACTION_READ_UNCOMMITTED);
可以查看数据库的当前设置:
getTransactionIsolation ()
需要注意的是,在进行手动设置时,数据库及其驱动程序必须得支持相应的事务操作操作才行。
上 述设置随着值的增加,其事务的独立性增加,更能有效地防止事务操作之间的冲突,同时也增加了加锁的开销,降低了用户之间访问数据库的并发性,程序的运行效 率也会随之降低。因此得平衡程序运行效率和数据一致性之间的冲突。一般来说,对于只涉及到数据库的查询操作时,可以采用 TRANSACTION_READ_UNCOMMITTED方式;对于数据查询远多于更新的操作,可以采用 TRANSACTION_READ_COMMITTED方式;对于更新操作较多的,可以采用TRANSACTION_REPEATABLE_READ;在 数据一致性要求更高的场合再考虑最后一项,由于涉及到表加锁,因此会对程序运行效率产生较大的影响。
另外,在Oracle中数据库驱动对事务处理的默认值是TRANSACTION_NONE,即不支持事务操作,所以需要在程序中手动进行设置。总之,JDBC提供的对数据库事务操作的支持是比较完整的,通过事务操作可以提高程序的运行效率,保持数据的一致性。
三、数据库连接池(dbcp、c3p0)
连接池产生的背景:
数据库连接是一种重要资源。大部分很重要的数据都存在数据库里,那么在产生连接池之前,我们连接数据库的方式:直连。(获取连接->使用->关闭连接)程序小的话可以采用这种方式,但是如果程序很大,比如大型网站,它可能每分钟或者每秒变化量在100万次,就是说同时访问数据库有100万个用户,这时候如果我们不用连接池的话,我们就需要创建100万个连接这样的话就会对数据库造成很大的压力,如果数据库承受不了的话就崩溃了,服务器也崩溃了,网站就瘫痪了。
即:
①数据库连接是一种重要资源;
②频繁的连接数据库会增加数据库的压力;
③为解决以上问题出现连接池技术。
(池子里保持一定数量的连接,当使用时就从池子中拿一个连接出来,当使用完连接后就把它释放到池子里。当你同时访问数据库人很多的时候,这个时候连接不够用,就需要等待,减少数据库的压力)
常用的开源数据库连接池:
- dbcp
- c3p0
1、dbcp使用步骤
1、首先,导入相关jar包:

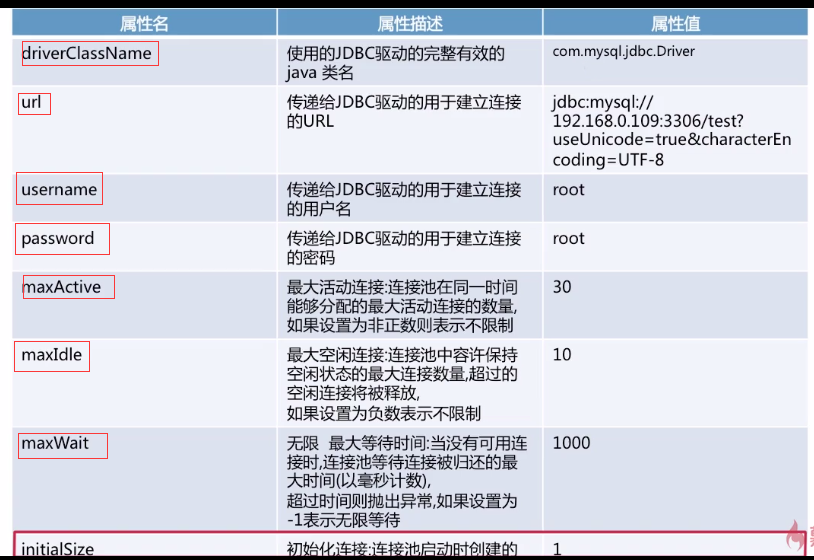
2、在项目根目录增加配置文件:dbcp.properties
这个属性文件的内容如下:
3、配置并测试dbcp连接
DBCPUtil.java
1 package com.study.db; 2 3 import java.sql.Connection; 4 import java.sql.SQLException; 5 import java.util.Properties; 6 7 import javax.sql.DataSource; 8 9 import org.apache.commons.dbcp2.BasicDataSource; 10 import org.apache.commons.dbcp2.BasicDataSourceFactory; 11 /** 12 * @Description: DBCP配置类 13 * @author: Qian 14 * @date: 2016-4-4 上午8:57:49 15 */ 16 public class DBCPUtil { 17 /**数据源,static*/ 18 private static DataSource DS; 19 private static final String configFile="/dbcp.properties";//配置文件 20 21 /**从数据源获得一个连接*/ 22 /** 23 * @Description: TODO 24 * @param @return 设定文件 25 * @return Connection 返回类型 26 * @author Qian 27 * @date 2016-4-4 上午9:11:07 28 */ 29 public Connection getConn(){ 30 Connection conn=null; 31 if(DS !=null){ 32 try { 33 conn=DS.getConnection();//从数据源里面拿到连接 34 } catch (Exception e) { 35 e.printStackTrace(System.err); 36 } 37 try { 38 conn.setAutoCommit(false);//关闭连接的自动提交 39 } catch (SQLException e) { 40 e.printStackTrace(); 41 } 42 return conn; 43 } 44 return conn; 45 } 46 47 /**默认的构造函数*/ 48 /** 49 * @Description: TODO 50 * @param 51 * @return 52 * @author Qian 53 * @date 2016-4-4 上午9:17:02 54 */ 55 public DBCPUtil(){ 56 initDbcp(); 57 } 58 59 private static void initDbcp(){ 60 Properties pops=new Properties(); 61 try { 62 pops.load(Object.class.getResourceAsStream(configFile));//读取配置文件 63 DS=BasicDataSourceFactory.createDataSource(pops);//通过BasicDataSourceFactory提供的工厂类,拿到DataSource数据源 64 } catch (Exception e) { 65 e.printStackTrace(); 66 } 67 } 68 /*构造函数,初始化了DS,指定数据库*/ 69 public DBCPUtil(String connectURI){ 70 initDS(connectURI); 71 } 72 73 /*构造函数,初始化了DS,指定所有参数*/ 74 public DBCPUtil(String connectURI,String userName,String passWord,String driverClass,int initialSize,int maxIdle,int minIdle,int maxWait){ 75 initDS(connectURI,userName,passWord,driverClass,initialSize,maxIdle,minIdle,maxWait); 76 } 77 78 /** 79 * @Description: 创建数据源,除了数据外,都是用硬编码默认参数 80 * @param @param connectURI 数据库 81 * @return 82 * @author Qian 83 * @date 2016-4-4 上午9:47:18 84 */ 85 public static void initDS(String connectURI){ 86 initDS(connectURI, "root", "root", "com.mysql.jdbc.Driver", 10, 20, 5, 1000); 87 } 88 89 /** 90 * @Description: 91 * @param @param connectURI 数据库 92 * @param @param userName 用户名 93 * @param @param passWord 密码 94 * @param @param driverClass 驱动 95 * @param @param initialSize 初始化连接数 96 * @param @param maxIdle 最大连接数 97 * @param @param minIdle 最小连接数 98 * @param @param maxWait 超时等待时间(获得连接的最大等待毫秒数) 99 * @return 100 * @author Qian 101 * @date 2016-4-4 上午9:45:18 102 */ 103 public static void initDS(String connectURI,String userName,String passWord,String driverClass, 104 int initialSize,int maxIdle,int minIdle,int maxWait){ 105 BasicDataSource ds=new BasicDataSource();//new 一个数据源 106 ds.setDriverClassName(driverClass); 107 ds.setUsername(userName); 108 ds.setPassword(passWord); 109 ds.setUrl(connectURI); 110 ds.setInitialSize(initialSize);//初始的连接数 111 ds.setMaxIdle(maxIdle); 112 ds.setMaxWaitMillis(maxWait); 113 ds.setMinIdle(minIdle); 114 DS = ds; 115 } 116 }
GoddessDao.java
1 //查询单个女神(根据id去查询) 2 public Goddess get(Integer id) throws SQLException{ 3 Goddess g=null; 4 Connection con=DBUtil.getConnection();//首先拿到数据库的连接 5 String sql="" + 6 "select * from imooc_goddess "+ 7 "where id=?";//参数用?表示,相当于占位符;用mysql的日期函数current_date()来获取当前日期 8 //预编译sql语句 9 PreparedStatement psmt = con.prepareStatement(sql); 10 //先对应SQL语句,给SQL语句传递参数 11 psmt.setInt(1, id); 12 //执行SQL语句 13 /*psmt.execute();*///execute()方法是执行更改数据库操作(包括新增、修改、删除);executeQuery()是执行查询操作 14 ResultSet rs = psmt.executeQuery();//返回一个结果集 15 //遍历结果集 16 while(rs.next()){ 17 g=new Goddess(); 18 g.setId(rs.getInt("id")); 19 g.setUserName(rs.getString("user_name")); 20 g.setAge(rs.getInt("age")); 21 g.setSex(rs.getInt("sex")); 22 //rs.getDate("birthday")获得的是java.sql.Date类型。注意:java.sql.Date类型是java.util.Date类型的子集,所以这里不需要进行转换了。 23 g.setBirthday(rs.getDate("birthday")); 24 g.setEmail(rs.getString("email")); 25 g.setMobile(rs.getString("mobile")); 26 g.setCreateUser(rs.getString("create_user")); 27 g.setCreateDate(rs.getDate("create_date")); 28 g.setUpdateUser(rs.getString("update_user")); 29 g.setUpdateDate(rs.getDate("update_date")); 30 g.setIsDel(rs.getInt("isdel")); 31 } 32 return g; 33 } 34 35 //查询单个女神(根据id去查询) 36 public Goddess getByDbcp(Integer id) throws SQLException{ 37 DBCPUtil db=new DBCPUtil(); 38 Goddess g=null; 39 Connection con=db.getConn();//首先拿到数据库的连接 40 String sql="" + 41 "select * from imooc_goddess "+ 42 "where id=?";//参数用?表示,相当于占位符;用mysql的日期函数current_date()来获取当前日期 43 //预编译sql语句 44 PreparedStatement psmt = con.prepareStatement(sql); 45 //先对应SQL语句,给SQL语句传递参数 46 psmt.setInt(1, id); 47 //执行SQL语句 48 /*psmt.execute();*///execute()方法是执行更改数据库操作(包括新增、修改、删除);executeQuery()是执行查询操作 49 ResultSet rs = psmt.executeQuery();//返回一个结果集 50 //遍历结果集 51 while(rs.next()){ 52 g=new Goddess(); 53 g.setId(rs.getInt("id")); 54 g.setUserName(rs.getString("user_name")); 55 g.setAge(rs.getInt("age")); 56 g.setSex(rs.getInt("sex")); 57 //rs.getDate("birthday")获得的是java.sql.Date类型。注意:java.sql.Date类型是java.util.Date类型的子集,所以这里不需要进行转换了。 58 g.setBirthday(rs.getDate("birthday")); 59 g.setEmail(rs.getString("email")); 60 g.setMobile(rs.getString("mobile")); 61 g.setCreateUser(rs.getString("create_user")); 62 g.setCreateDate(rs.getDate("create_date")); 63 g.setUpdateUser(rs.getString("update_user")); 64 g.setUpdateDate(rs.getDate("update_date")); 65 g.setIsDel(rs.getInt("isdel")); 66 } 67 return g; 68 }
测试:
1 package com.study.test; 2 3 import java.util.Date; 4 5 import com.study.dao.GoddessDao; 6 import com.study.model.Goddess; 7 8 /**@Description: 测试用DBCP连接数据库 9 * @author: Qian 10 * @date: 2016-4-4 上午9:53:53 11 */ 12 public class TestDbcp { 13 14 /**@Description: TODO 15 * @param @param args 16 * @return 17 * @author Qian 18 * @throws Exception 19 * @date 2016-4-4 上午9:53:53 20 */ 21 public static void main(String[] args) throws Exception { 22 //1.通过普通方式操作数据库 23 Date a=new Date(); 24 get(); 25 Date b=new Date(); 26 System.out.println(b.getTime()-a.getTime()); 27 28 //2.通过DBCP连接池的方式操作数据库 29 Date c=new Date(); 30 get(); 31 Date d=new Date(); 32 System.out.println(d.getTime()-c.getTime()); 33 34 /** 35 * 通过运行,发现第二种方式明显要比第一种用时少 36 */ 37 } 38 39 public static void get() throws Exception{ 40 GoddessDao dao=new GoddessDao(); 41 Goddess g=dao.get(1); 42 System.out.println(g.toString()); 43 } 44 45 public static void getByDbcp() throws Exception{ 46 GoddessDao dao=new GoddessDao(); 47 Goddess g=dao.getByDbcp(1); 48 System.out.println(g.toString()); 49 } 50 }
2、c3p0使用步骤
c3p0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3和JDBC2的标准扩展。目前使用它的开源项目有Hibernate,Spring等。
默认情况下(即没有配置连接池的情况下),Hibernate会采用内建的连接池。但这个连接池性能不佳,因此官方也只是建议仅在开发环境下使用。Hibernate支持第三方的连接池,官方推荐的连接池是C3P0,Proxool。
1、导入相关jar包:

注:在tomcat或者项目中引入最新版的C3P0的JAR包(我是用的是c3p0-0.9.2.1.jar)
如果启动时报类没有找到:Caused by: java.lang.NoClassDefFoundError: com/mchange/v2/ser/Indirector,
则需要加入mchange-commons-java-0.2.3.4.jar。
2、在项目根目录增加配置文件:c3p0.properties
1 c3p0.driverClass=com.mysql.jdbc.Driver 2 c3p0.jdbcUrl=jdbc:mysql://localhost:3306/demo_jdbc 3 c3p0.user=root 4 c3p0.password=root
3、编写类文件,创建连接池
C3P0Util.java
1 package com.study.db; 2 3 import java.sql.Connection; 4 import java.sql.SQLException; 5 6 import com.mchange.v2.c3p0.ComboPooledDataSource; 7 8 /**@Description: c3p0数据源配置类 9 * @author: Qian 10 * @date: 2016-4-4 上午10:40:01 11 */ 12 public class C3P0Util { 13 //创建一个数据源 14 private static ComboPooledDataSource ds=new ComboPooledDataSource(); 15 16 public static Connection getConn(){ 17 try { 18 return ds.getConnection(); 19 } catch (SQLException e) { 20 throw new RuntimeException(e); 21 } 22 } 23 }
TestC3p0.java
1 package com.study.test; 2 3 import java.sql.Connection; 4 import java.sql.SQLException; 5 6 import com.study.db.C3P0Util; 7 8 /**@Description: 测试C3P0 9 * @author: Qian 10 * @date: 2016-4-4 上午10:43:11 11 */ 12 public class TestC3p0 { 13 14 /**@Description: TODO 15 * @param @param args 16 * @return 17 * @author Qian 18 * @throws SQLException 19 * @date 2016-4-4 上午10:43:11 20 */ 21 public static void main(String[] args) throws SQLException { 22 Connection con=C3P0Util.getConn(); 23 System.out.println(con.getCatalog()); 24 25 } 26 27 }
可以仿照上面dbcp来测试c3p0连接池。
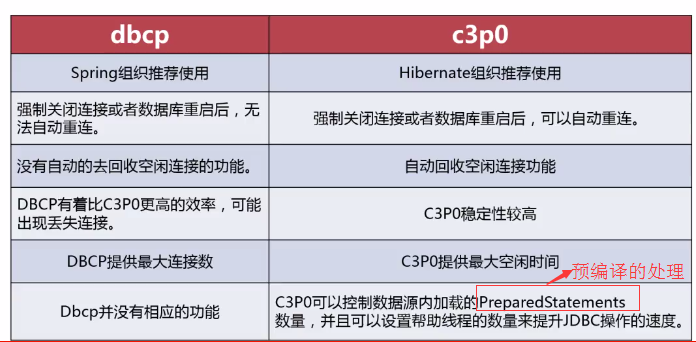
3、连接池总结
DBCP和C3P0的相同点:

DBCP和C3P0的不同点:
四、JDBC的替代产品(Hibernate、Mybatis)
上面介绍的都是手工的连接数据库,写SQL语句。这部分的替代产品会替代我们的这些工作。
替代工具:
- Commons-dbutils;
- Hibernate;
- Mybatis;
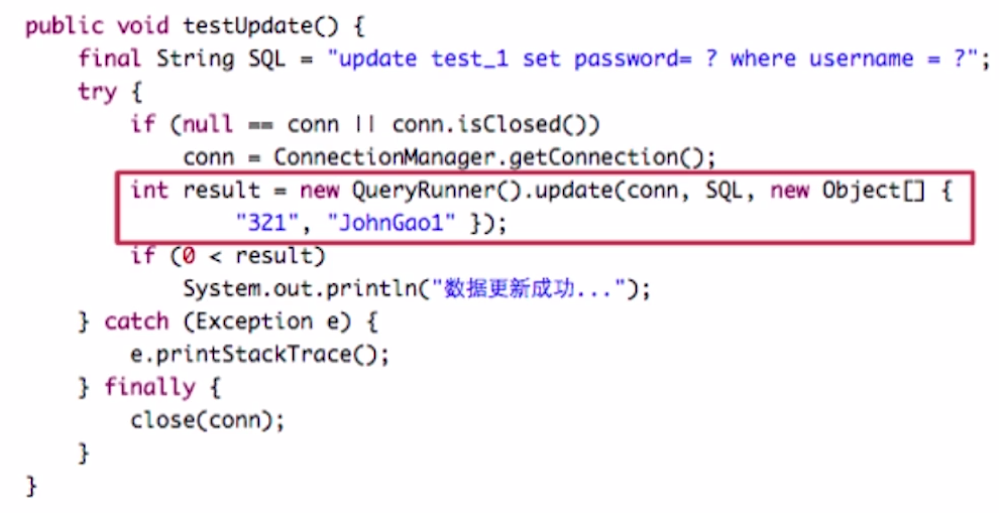
1、Commons-dbutils
从字面意思可以理解为:通用的数据库工具类。
Apache组织提供的一个开源JDBC工具类库,对传统操作数据库的类进行二次封装,可以把结果集转化成List。
特点:

核心接口:

示例:



2、Hibernate简介
是一种Java语言下的对象关系映射解决方案。它是一种自由、开源的软件。
优点:

缺点:
如果对大量的数据进行频繁的操作,性能效率比较低,不如直接使用JDBC。(因为Hibernate做了完整的封装,所以效率可能会低。)
核心接口:


示例:

*.hbm.xml
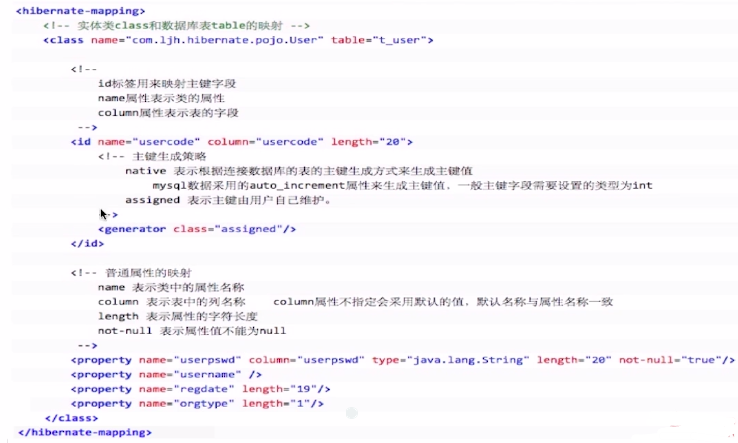
插入:

3、Mybatis简介
Mybatis是支持普通SQL查询,存储过程和高级映射的优秀持久层框架。
特点:

示例:

userMapper.xml示例
