快速实例
大致步骤

(1)创建表,数据迁移
(2)创建表序列化类BookSerializer
class BookSerializer(serializers.HyperlinkedModelSerializer):
class Meta:
model=Book
fields="__all__"
(3)创建视图类:
class BookViewSet(viewsets.ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookSerializer
(4) 设计url:
router.register(r'books', views.BookViewSet)
序列化
创建一个序列化类
简单使用
开发我们的Web API的第一件事是为我们的Web API提供一种将代码片段实例序列化和反序列化为诸如json之类的表示形式的方式。我们可以通过声明与Django forms非常相似的序列化器(serializers)来实现。
models部分:
from django.db import models
# Create your models here.
class Book(models.Model):
title=models.CharField(max_length=32)
price=models.IntegerField()
pub_date=models.DateField()
publish=models.ForeignKey("Publish")
authors=models.ManyToManyField("Author")
def __str__(self):
return self.title
class Publish(models.Model):
name=models.CharField(max_length=32)
email=models.EmailField()
def __str__(self):
return self.name
class Author(models.Model):
name=models.CharField(max_length=32)
age=models.IntegerField()
def __str__(self):
return self.name
views部分:
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import *
from django.shortcuts import HttpResponse
from django.core import serializers
from rest_framework import serializers
class BookSerializers(serializers.Serializer):
title=serializers.CharField(max_length=32)
price=serializers.IntegerField()
pub_date=serializers.DateField()
publish=serializers.CharField(source="publish.name")
#authors=serializers.CharField(source="authors.all")
authors=serializers.SerializerMethodField()
def get_authors(self,obj):
temp=[]
for author in obj.authors.all():
temp.append(author.name)
return temp
class BookViewSet(APIView):
def get(self,request,*args,**kwargs):
book_list=Book.objects.all()
# 序列化方式1:
# from django.forms.models import model_to_dict
# import json
# data=[]
# for obj in book_list:
# data.append(model_to_dict(obj))
# print(data)
# return HttpResponse("ok")
# 序列化方式2:
# data=serializers.serialize("json",book_list)
# return HttpResponse(data)
# 序列化方式3:
bs=BookSerializers(book_list,many=True) # 当传的是一个queryset时要加many=True,如果是一个单个对象则不用加
return Response(bs.data)
我们可以看到当我们拿到book_list后,有很多种方式来进行序列化,这里我们使用的是rest_framwork带的serializers来进行的序列化,在返回时我们也用到了rest_framwork的Response
还有一点值得注意的时,我们之前在写CBV时,继承的django.views中的View类,而这里我们是从rest_framwork.views中导入的APIView,我们来看看这个类具体做了什么
首先,在url中我们可以看到
from django.conf.urls import url
from django.contrib import admin
from api import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^books/$', views.BookView.as_view()),
]
这里我们还是使用的as_view这个方法,那么在APIView中这个方法是如何定义的呢
@classmethod
def as_view(cls, **initkwargs):
"""
Store the original class on the view function.
This allows us to discover information about the view when we do URL
reverse lookups. Used for breadcrumb generation.
"""
if isinstance(getattr(cls, 'queryset', None), models.query.QuerySet):
def force_evaluation():
raise RuntimeError(
'Do not evaluate the `.queryset` attribute directly, '
'as the result will be cached and reused between requests. '
'Use `.all()` or call `.get_queryset()` instead.'
)
cls.queryset._fetch_all = force_evaluation
view = super(APIView, cls).as_view(**initkwargs)
view.cls = cls
view.initkwargs = initkwargs
# Note: session based authentication is explicitly CSRF validated,
# all other authentication is CSRF exempt.
return csrf_exempt(view)
可以看到这里其实是通过super方法执行的它父类的as_view方法,而它的父类正式django的View类,所以这里的view其实就是父类执行as_view方法获得的view函数,在url中得到这个函数后,会自动去执行它,而执行它其实就是在执行dispatch方法
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
我们来看看APIView的dispatch方法都做了什么
def dispatch(self, request, *args, **kwargs):
"""
`.dispatch()` is pretty much the same as Django's regular dispatch,
but with extra hooks for startup, finalize, and exception handling.
"""
self.args = args
self.kwargs = kwargs
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
self.initial(request, *args, **kwargs)
# Get the appropriate handler method
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
response = handler(request, *args, **kwargs)
except Exception as exc:
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response
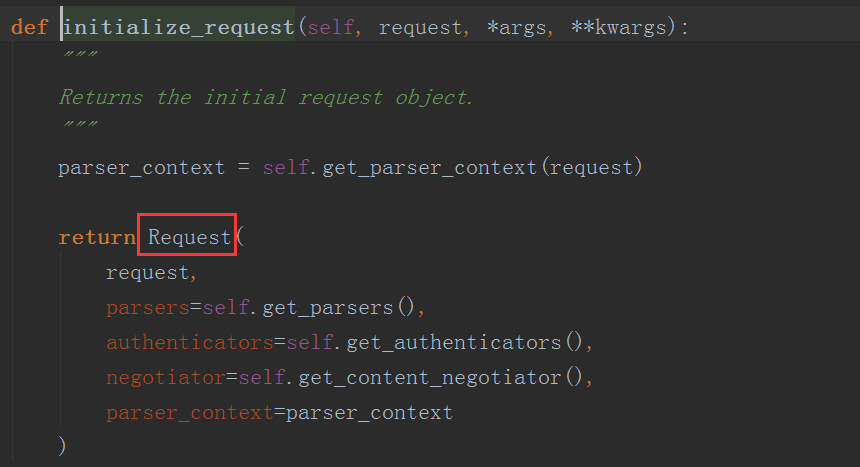
这里的dispatch首先重新定义了一下request,request = self.initialize_request(request, *args, **kwargs),这个initialize_request方法的内容如下
def initialize_request(self, request, *args, **kwargs):
"""
Returns the initial request object.
"""
parser_context = self.get_parser_context(request)
return Request(
request,
parsers=self.get_parsers(),
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)
可以看到它其实就是返回了一个Request类的实例对象,那么这个类又做了什么呢
def __init__(self, request, parsers=None, authenticators=None,
negotiator=None, parser_context=None):
assert isinstance(request, HttpRequest), (
'The `request` argument must be an instance of '
'`django.http.HttpRequest`, not `{}.{}`.'
.format(request.__class__.__module__, request.__class__.__name__)
)
self._request = request
self.parsers = parsers or ()
self.authenticators = authenticators or ()
self.negotiator = negotiator or self._default_negotiator()
self.parser_context = parser_context
self._data = Empty
self._files = Empty
self._full_data = Empty
self._content_type = Empty
self._stream = Empty
if self.parser_context is None:
self.parser_context = {}
self.parser_context['request'] = self
self.parser_context['encoding'] = request.encoding or settings.DEFAULT_CHARSET
force_user = getattr(request, '_force_auth_user', None)
force_token = getattr(request, '_force_auth_token', None)
if force_user is not None or force_token is not None:
forced_auth = ForcedAuthentication(force_user, force_token)
self.authenticators = (forced_auth,)
别的暂时先不看,我们可以看到它定义了一个self._request = request,所以我们以后如果想使用wsgi封装的request其实需要用request._request才行
在定义完新的request之后,dispatch又进行了一步初始化操作self.initial(request, *args, **kwargs),这个我们后面再说,然后进行的就和View类一样,判断请求的方式是否在self.http_method_names中,如果在就利用反射的方式取到,然后执行,但是这样要注意的是,这时后执行get,post等方法时传进去的request已经是重新定义过后的了
看完了源码的大体流程,我们再来看看序列化的类干了什么
from rest_framework import serializers
from rest_framework.response import Response
from rest_framework.views import APIView
class BookSerializers(serializers.Serializer):
title = serializers.CharField(max_length=32)
price = serializers.IntegerField()
pub_date = serializers.DateField()
publish = serializers.CharField(source="publish.id")
# authors = serializers.CharField(source="authors.all")
# 针对多对多
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
temp = []
for author in obj.authors.all():
temp.append(author.pk)
return temp
首先定义这个类其实和我们之前使用的form有点像,不过这里要注意一对多的字段,有个source属性,可以控制我们具体显示的内容,默认是显示这个对象,这里我们可以定义为对象的id等,而多对多的字段我们可以自定义一个方法
serializers.SerializerMethodField()是固定写法,而下面的函数名必须是get_字段名,函数的参数obj就是每一个book对象,这样我们通过这个类,在使用postman进行get请求时就能得到如下的数据
[
{
"id": 1,
"authors": [
1,
2
],
"title": "python",
"price": 123,
"pub_date": "2018-04-08",
"publish": 1
},
{
"id": 2,
"authors": [
1
],
"title": "go",
"price": 222,
"pub_date": "2018-04-08",
"publish": 2
},
{
"id": 3,
"authors": [
2
],
"title": "java",
"price": 222,
"pub_date": "2018-04-08",
"publish": 2
}
]
上面的写法跟普通的form类似,当然我们还学过ModelForm,这里也有类似的用法
class BookSerializers(serializers.ModelSerializer):
class Meta:
model = Book
fields = "__all__"
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
temp = []
for author in obj.authors.all():
temp.append(author.pk)
return temp
这里如果不单独定义多对多的字段和一对多的字段,那么默认显示的是字段的pk值
提交post请求
def post(self,request,*args,**kwargs):
bs=BookSerializers(data=request.data,many=False)
if bs.is_valid():
# print(bs.validated_data)
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
post请求是用来添加数据的,这里的request经过了新的封装,我们可以从request.data中拿到数据,然后就像使用form表单一样使用serializers,实例化一个对象,通过is_valid方法验证数据,如果没问题直接save保存数据,有问题的话则返回错误信息,这里要注意,当数据保存后我们要将新添加的数据返回(Json格式)
各种情况下需要返回的内容
全部信息
users/
----查看所有数据
get users/ :返回所有的用户的json数据
----提交数据
post users/ :返回添加数据的json数据
具体对象
users/2
----查看
get users/2 :返回具体查看的用户的json数据
----删除
delete users/2 :返回空文档
----编辑
put/patch users/2:返回的编辑后的json数据包
单条数据的get、put和delete请求
这里需要对单条数据进行操作,所以要有一个新的url和新的视图
from django.conf.urls import url
from django.contrib import admin
from api import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^books/$', views.BookView.as_view(), name="book_list"),
url(r'^books/(d+)/$', views.BookDetailView.as_view(), name="book_detail"),
]
新的url对应的新视图
# 针对Book某一个数据操作 查看,编辑,删除一本书
class BookDetailView(APIView):
# 查看一本书
def get(self, request, pk, *args, **kwargs):
obj = Book.objects.filter(pk=pk).first()
if obj:
bs = BookSerializers(obj)
return Response(bs.data)
else:
return Response()
# 编辑一本书
def put(self, request, pk, *args, **kwargs):
obj = Book.objects.filter(pk=pk).first()
bs = BookSerializers(data=request.data, instance=obj)
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return Response(bs.errors)
# 删除一本书
def delete(self, request, pk, *args, **kwargs):
Book.objects.filter(pk=pk).delete()
return Response()
查看时跟我们之前的区别在于,之前是序列化的一个queryset,现在只是一个单个对象,然后将这个对象的序列化结果返回,这里多加了一步判断,如果这个对象不存在则返回空
编辑时,我们首先通过主键值取到这个书对象,然后像使用form组件一样,将更新的数据和这个对象传给我们的序列化类进行实例化,这里注意参数instance和form组件一样,然后通过is_valid验证数据是否正确,如果正确则save并返回这条记录,错误则返回错误信息
删除时,直接过滤出我们要删除的进行删除即可,返回空
超链接API:Hyperlinked
采用上面的内容,我们访问时,外键内容我们可以看到的是主键值,但是如果我们想看到一个链接url呢,那么就要采用下面的方法
class BookSerializers(serializers.ModelSerializer):
publish= serializers.HyperlinkedIdentityField(
view_name='publish_detail',
lookup_field="publish_id",
lookup_url_kwarg="pk")
class Meta:
model=Book
fields="__all__"
#depth=1
这里我们重新定义了publish字段,view_name是url对应的别名,lookup_field则是url上对应的需要显示的内容,lookup_url_kwarg是url上的分组名称
urls部分:
urlpatterns = [
url(r'^books/$', views.BookViewSet.as_view(),name="book_list"),
url(r'^books/(?P<pk>d+)$', views.BookDetailViewSet.as_view(),name="book_detail"),
url(r'^publishers/$', views.PublishViewSet.as_view(),name="publish_list"),
url(r'^publishers/(?P<pk>d+)$', views.PublishDetailViewSet.as_view(),name="publish_detail"),
]
这样,我们访问时就能看到publish的结果是一个url链接
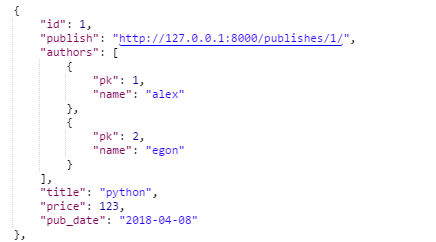
视图
使用混合(mixins)
使用我们上面的方法,如果我们要再定义一个publish表的操作,则需要再写两个视图
from rest_framework.views import APIView
from rest_framework.response import Response
from .models import *
from django.shortcuts import HttpResponse
from django.core import serializers
from rest_framework import serializers
class BookSerializers(serializers.ModelSerializer):
class Meta:
model=Book
fields="__all__"
#depth=1
class PublshSerializers(serializers.ModelSerializer):
class Meta:
model=Publish
fields="__all__"
depth=1
class BookViewSet(APIView):
def get(self,request,*args,**kwargs):
book_list=Book.objects.all()
bs=BookSerializers(book_list,many=True,context={'request': request})
return Response(bs.data)
def post(self,request,*args,**kwargs):
print(request.data)
bs=BookSerializers(data=request.data,many=False)
if bs.is_valid():
print(bs.validated_data)
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
class BookDetailViewSet(APIView):
def get(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,context={'request': request})
return Response(bs.data)
def put(self,request,pk):
book_obj=Book.objects.filter(pk=pk).first()
bs=BookSerializers(book_obj,data=request.data,context={'request': request})
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
class PublishViewSet(APIView):
def get(self,request,*args,**kwargs):
publish_list=Publish.objects.all()
bs=PublshSerializers(publish_list,many=True,context={'request': request})
return Response(bs.data)
def post(self,request,*args,**kwargs):
bs=PublshSerializers(data=request.data,many=False)
if bs.is_valid():
# print(bs.validated_data)
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
class PublishDetailViewSet(APIView):
def get(self,request,pk):
publish_obj=Publish.objects.filter(pk=pk).first()
bs=PublshSerializers(publish_obj,context={'request': request})
return Response(bs.data)
def put(self,request,pk):
publish_obj=Publish.objects.filter(pk=pk).first()
bs=PublshSerializers(publish_obj,data=request.data,context={'request': request})
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return HttpResponse(bs.errors)
可以方法,代码基本都是重复的,context={'request': request}是使用超链接API时需要加的内容
通过使用mixin类编写视图:
from rest_framework import mixins
from rest_framework import generics
class BookViewSet(mixins.ListModelMixin,
mixins.CreateModelMixin,
generics.GenericAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializers
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)
class BookDetailViewSet(mixins.RetrieveModelMixin,
mixins.UpdateModelMixin,
mixins.DestroyModelMixin,
generics.GenericAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializers
def get(self, request, *args, **kwargs):
return self.retrieve(request, *args, **kwargs)
def put(self, request, *args, **kwargs):
return self.update(request, *args, **kwargs)
def delete(self, request, *args, **kwargs):
return self.destroy(request, *args, **kwargs)
这里我们用到了多继承,当执行对应的方法时,其实会一步一步的从每一个继承的类中去找,这里我们以BookViewSet的get方法为例,当执行它时其实执行的是self.list(request, *args, **kwargs),这个list方法我们可以在它的第一个继承类mixins.ListModelMixin中找到
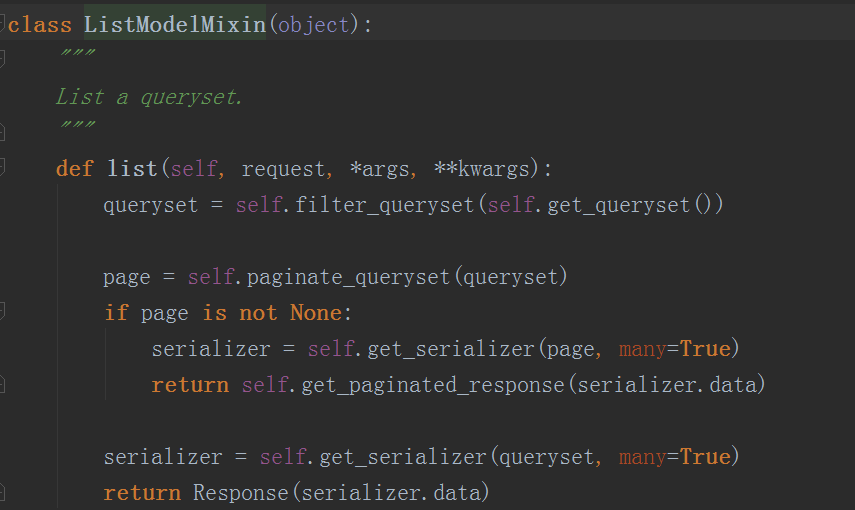
这个方法的内容其实和我们自己写的get方法是类似的,先拿到queryset,再利用序列化类进行实例化,最后返回序列化的结果
其它的方法也都跟这里类似,执行一个方法时只要按照继承顺序一步一步的找就行了
通过这种方式,我们就可以不用自己写那么多代码,而是直接使用继承类的内容,但是如果要再写一个publish表还是要写很多重复的内容
使用通用的基于类的视图
通过使用mixin类,我们使用更少的代码重写了这些视图,但我们还可以再进一步。REST框架提供了一组已经混合好(mixed-in)的通用视图,我们可以使用它来简化我们的views.py模块
from rest_framework import mixins
from rest_framework import generics
class BookViewSet(generics.ListCreateAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializers
class BookDetailViewSet(generics.RetrieveUpdateDestroyAPIView):
queryset = Book.objects.all()
serializer_class = BookSerializers
class PublishViewSet(generics.ListCreateAPIView):
queryset = Publish.objects.all()
serializer_class = PublshSerializers
class PublishDetailViewSet(generics.RetrieveUpdateDestroyAPIView):
queryset = Publish.objects.all()
serializer_class = PublshSerializers
generics.ListCreateAPIView,我们可以点击进去看看这个类的内容
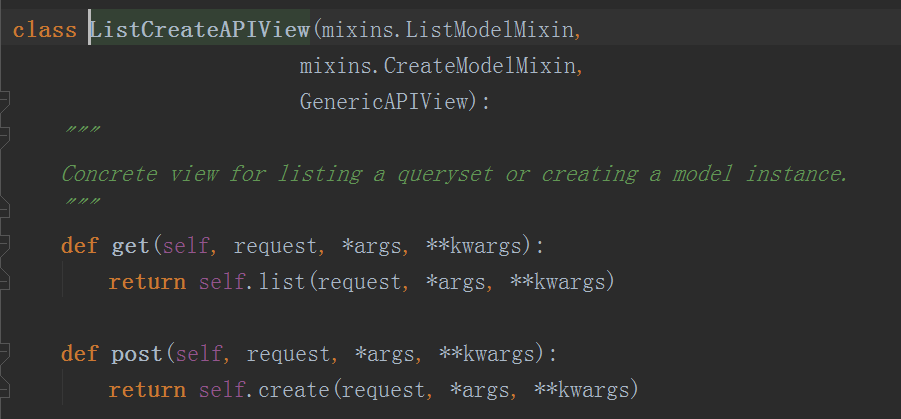
可以看到它已经帮我们把get和post方法都封装好了,其它的类也做了一样的事情,所以我们在写时,只需要继承这些类,然后在我们自己类中定义好queryset和serializer_class这两个参数即可,这样重复的代码就不用再写了
再次优化
通过上面的方法我们已经将代码优化了很多,那么还能不能再进行优化呢,其实还可以将我们定义的两个类合并
from rest_framework.viewsets import ModelViewSet
class BookViewSet(viewsets.ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookSerializers
这里我们继承了一个新的类,可以看看这个类都有一些什么内容
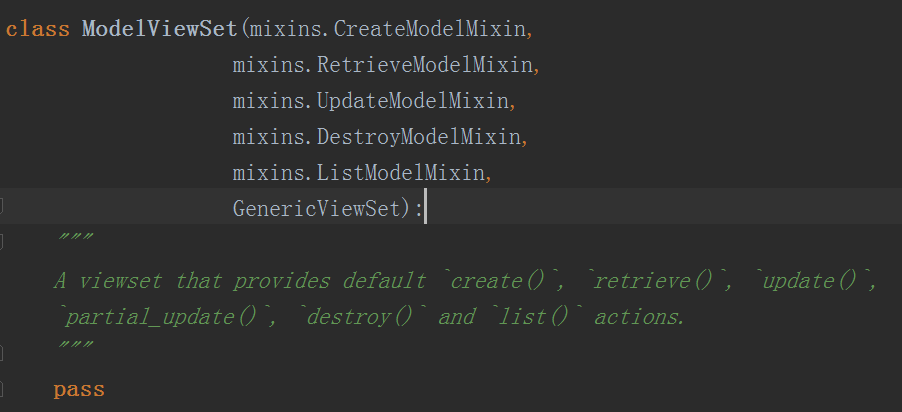
可以看到其实这个类就是继承了我们上面用到的各种类,这么用以后,为了加以区分,在url中我们需要多传一点参数
views.BookViewSet.as_view({"get":"list","post":"create"}),name="book_list"),
url(r'^books/(?P<pk>d+)$', views.BookViewSet.as_view({
'get': 'retrieve',
'put': 'update',
'patch': 'partial_update',
'delete': 'destroy'
}),name="book_detail"),
认证与权限组件
认证组件
局部视图认证
为了做认证,我们先要有用户相关的表,所以我们先添加表结构
from django.db import models
# Create your models here.
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.IntegerField()
pub_date = models.DateField()
publish = models.ForeignKey("Publish")
authors = models.ManyToManyField("Author")
def __str__(self):
return self.title
class Publish(models.Model):
name = models.CharField(max_length=32)
email = models.EmailField()
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
def __str__(self):
return self.name
class User(models.Model):
user = models.CharField(max_length=32)
pwd = models.CharField(max_length=32)
user_type = models.IntegerField(choices=((1, "普通用户"), (2, "VIP"), (3, "SVIP")), default=1)
class UserToken(models.Model):
user = models.OneToOneField("User")
token = models.CharField(max_length=128)
这里我们添加了两个表,一个用户表还有一个用户token表,token表中的token信息就是我们用来认证的字符串
表建好后,我们就要来创建login的逻辑了,这里的login我们只需要创建post请求的逻辑
from django.http import JsonResponse
def get_random_str(user):
import hashlib, time
ctime = str(time.time())
md5 = hashlib.md5(bytes(user, encoding="utf8"))
md5.update(bytes(ctime, encoding="utf8"))
return md5.hexdigest()
class LoginView(APIView):
def post(self, request, *args, **kwargs):
user = request.data.get("user")
pwd = request.data.get("pwd")
token = request.data.get("token")
user = User.objects.filter(user=user, pwd=pwd).first()
res = {"state_code": 200, "msg": None}
if user:
random_str = get_random_str(user.user)
UserToken.objects.update_or_create(user=user, defaults={"token": random_str})
res["msg"] = "success"
res["token"] = random_str
else:
res["msg"] = "用户名或密码错误"
res["state_code"] = 110
return JsonResponse(res)
当用户登录后我们先要判断用户名和密码是否正确,如果正确的话,我们通过md5生成一串随机字符串,然后将这个随机字符串添加到usertoken表中,这里要注意的是我们用到了update_or_create,当user=user的数据存在时就更新,否则就添加
如果登录不成功,则返回错误信息
用户登录完成后,我们就开始做认证了,首先我们需要创建一个认证类
from rest_framework import exceptions
from rest_framework.authentication import BaseAuthentication
class Authentication(BaseAuthentication):
def authenticate(self, request):
token = request._request.GET.get("token")
user_token_obj = UserToken.objects.filter(token=token).first()
if user_token_obj:
return user_token_obj.user, token
else:
raise exceptions.AuthenticationFailed("token验证失败")
类名随便取,但是类中必须有一个authenticate方法,在这个方法中做我们的逻辑判断,这里我们就从url上拿token值到数据库中搜索,如果有表示登录成功,这是需要返回一个元组,元组的两个值可以根据需要返回,如果不成功则要抛出一个异常
类定义完后我们就需要在我们的视图类中添加一个属性
class BookViewSet(ModelViewSet):
authentication_classes = [Authentication]
queryset = Book.objects.all()
serializer_class = BookSerializers
这样,当用户访问Book表相关功能时就会进行认证了
全局视图认证组件
上面我们介绍了局部认证,那么如果想让全局都进行认证呢,只需要在settings配置中增加
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",]
}
字典中的内容为认证类的路径
源码分析
上面我们介绍了认证组件的用法,那么为什么这么用呢,这就要通过源码来进行分析了,首先当用户来访问时,url匹配到了我们先执行的是一个as_view方法,这里我们从BookViewSet类继承的ModelViewSet类开始一步步往上找
首先我们来看看这些类的继承顺序
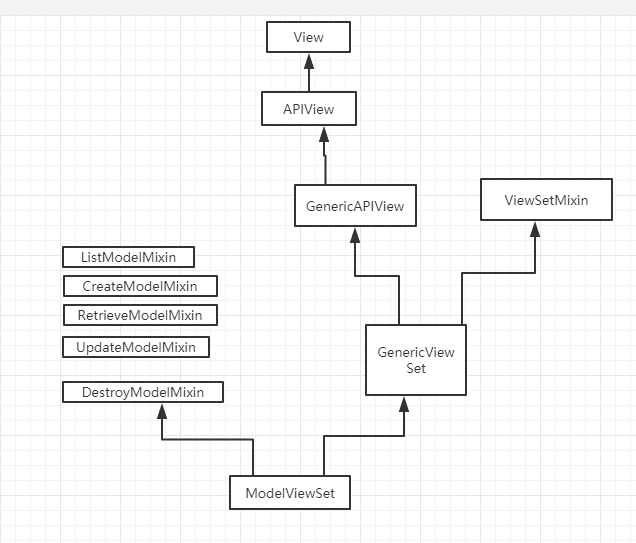
然后再一步步找
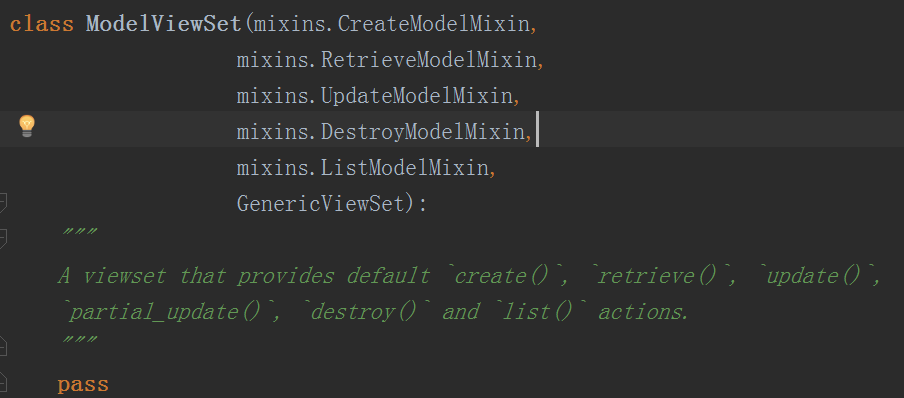
ModelViewSet中没有as_view
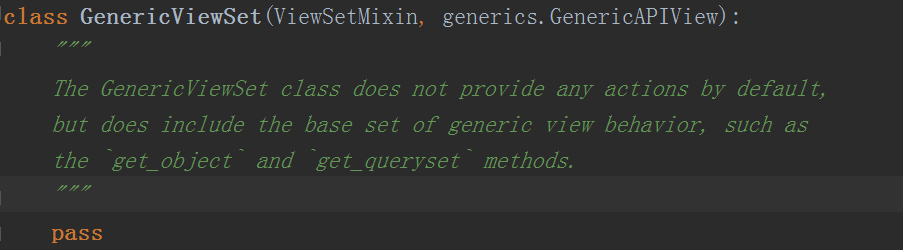
GenericViewSet中也没有,generics.GenericAPIView中也没有,最后在generics.GenericAPIView的父类APIView中发现as_view方法,这个方法在上面我们已经提到了,他返回了一个view函数,当匹配到url后,会执行这个view函数并给它传一个request
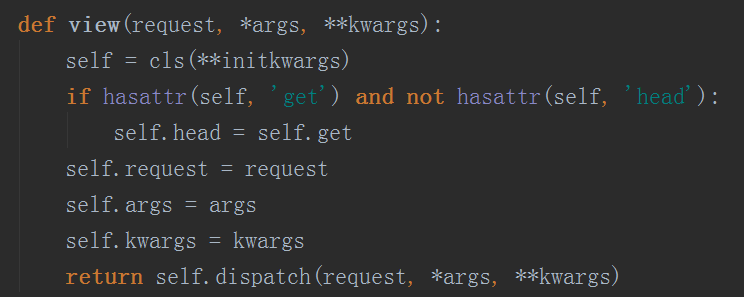
而执行这个view其实就是在self.dispatch方法,我们还是一步步找,最后还是在APIView找到了,这个方法我们上面说到了他重新封装了request,然后又进行了初始化操作
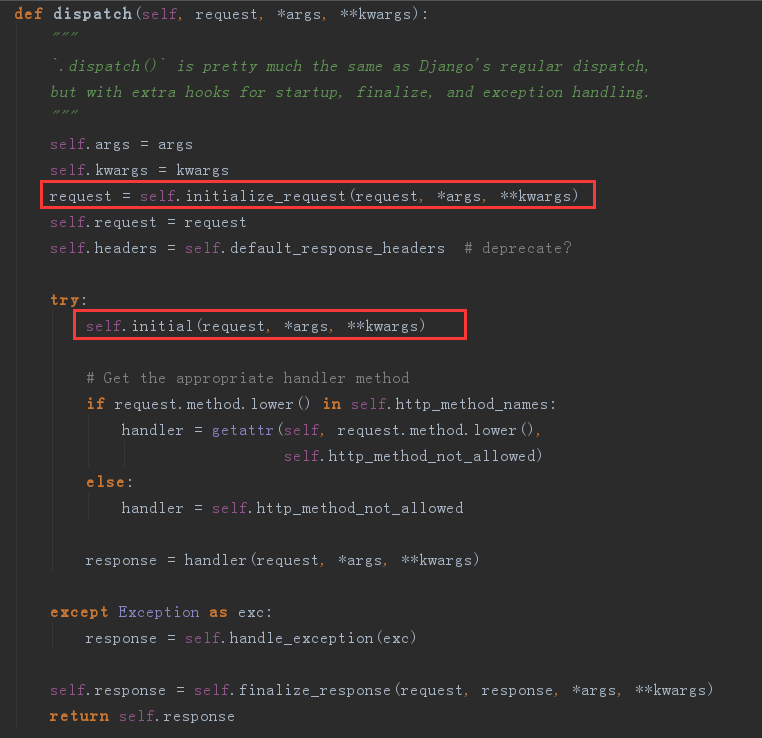
现在我们来看看初始化操作self.initial方法做了什么
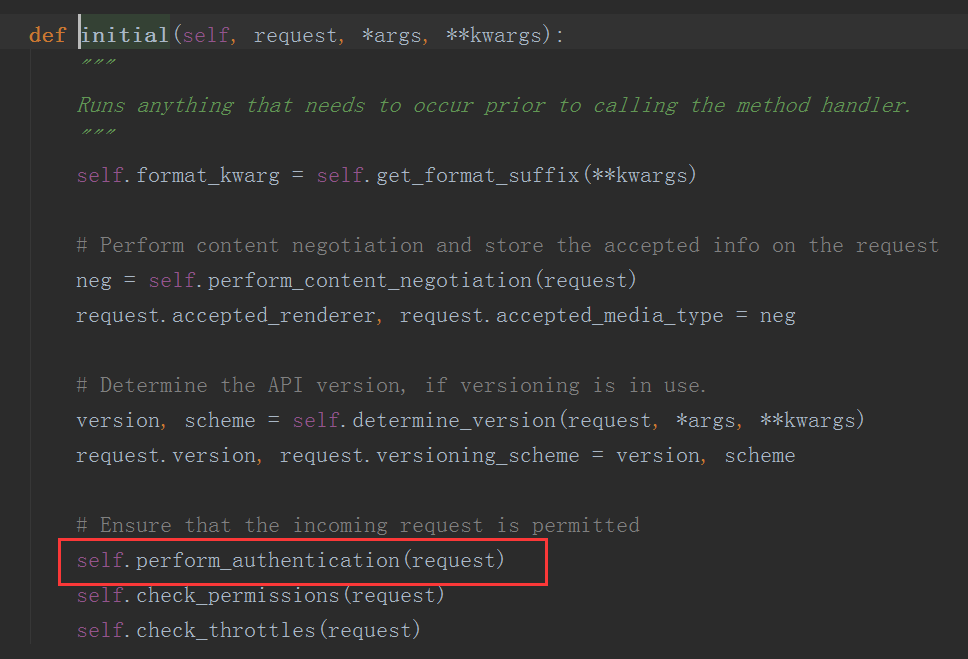
上面的操作我们先不管,我们发现这里有一步关于认证的操作self.perform_authentication(request),这里到底做了什么呢
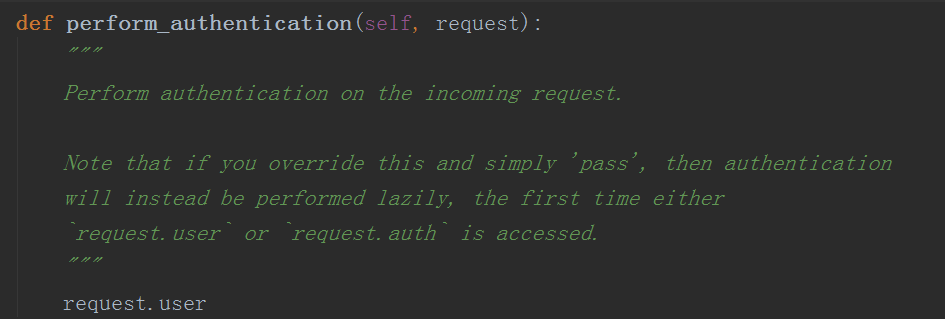
我们发现这里只有一个request.user,我们猜想这是一个静态方法,这时我们就要去重新定义request的类中找这个方法了
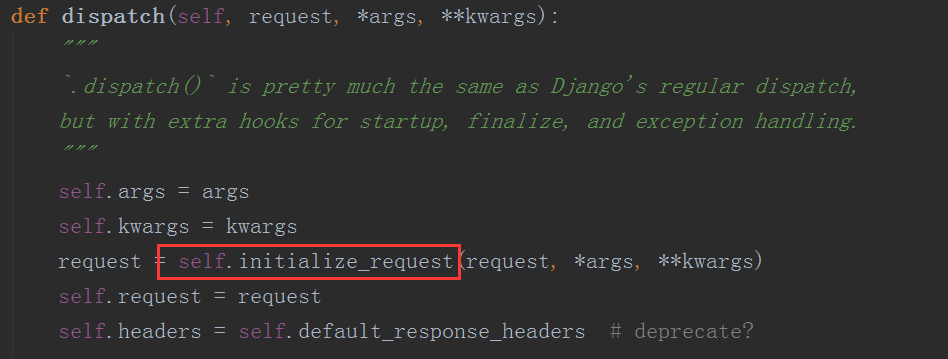

可以看到这里其实就是执行了self._authenticate()方法
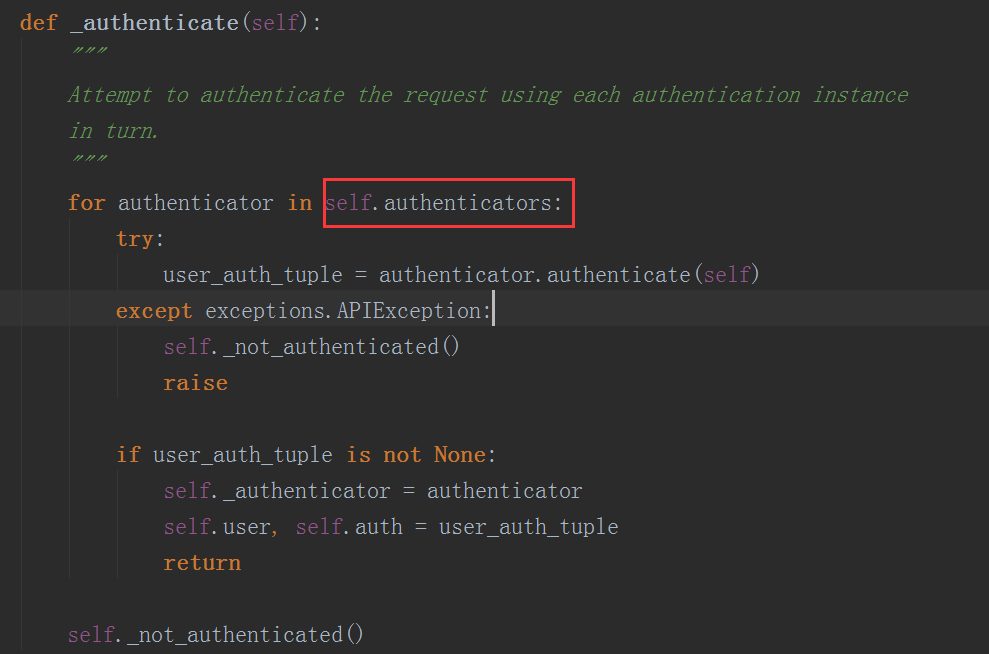
在这个方法中我们看到在for循环self.authenticators,那么这个self.authenticators是什么呢,我们注意到在Request类的初始化方法__init__中我们对它进行了定义
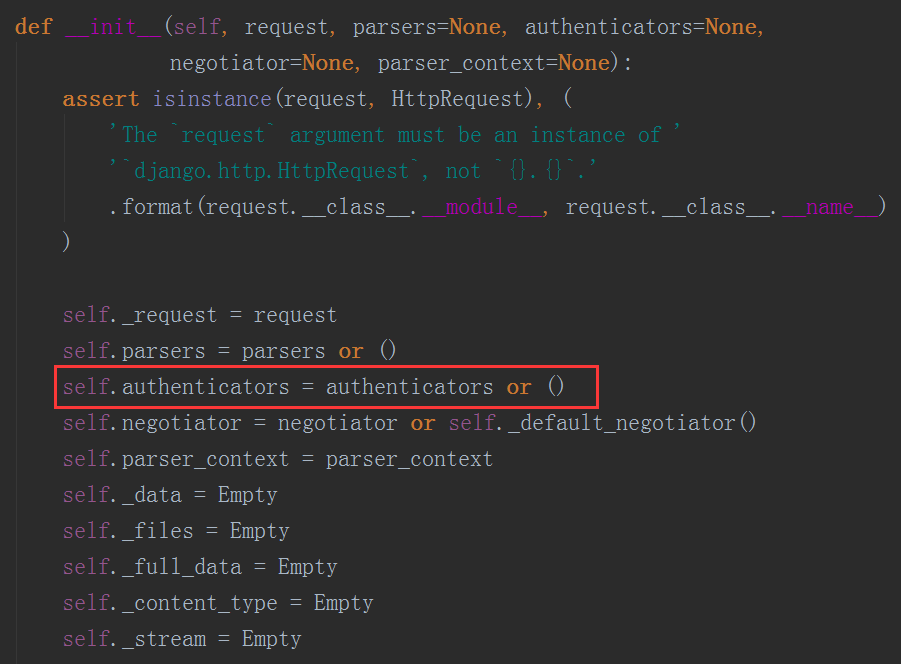
那么我们在实例化的过程中传了什么呢
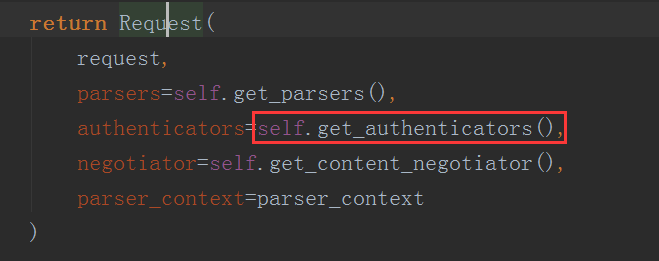
这里我们可以看到这里调用了self.get_authenticators()的方法

这个方法其实就是放回了一个列表,这个列表解析式中我们发现self.authentication_classes就是我们在局部认证时加在我们的视图类中的内容,是一个列表中放着认证类
所以这里返回的列表中放着的其实就是我们的认证类对象
知道了这个内容后,我们在上图所示的方法中其实就是在循环认证类对象的列表,然后调用对象的authenticate方法,所以我们在创建认证类时必须要有这个方法,而这个方法返回的是一个元组,在下面分别给self.user和self.auth赋值这个元组中的值
到这里我们就明白了为什么局部认证时要在视图类中设置authentication_classes,并且认证类中一定要有authenticate方法了,那么全局认证时又是为什么呢
我们发现,如果我们在视图类中没有定义authentication_classes属性,那么在找authentication_classes时,我们会在APIView中找到
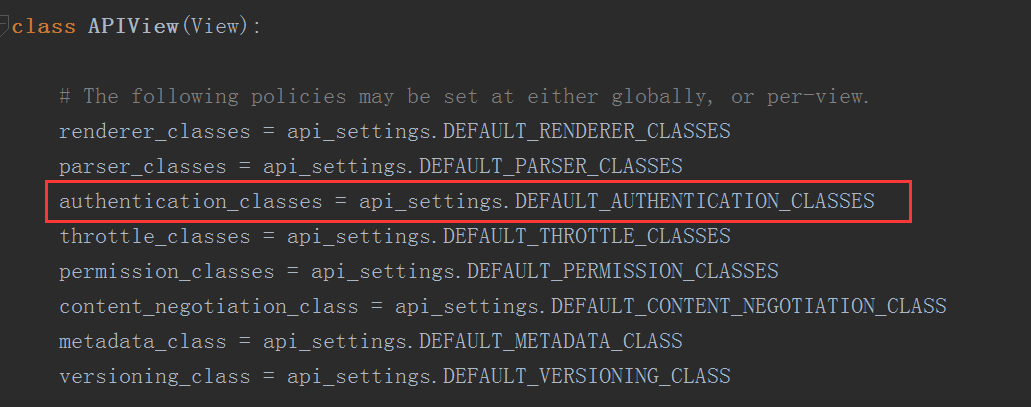
这里的api_settings是一个实例化的对象

在这个类中都有什么内容呢
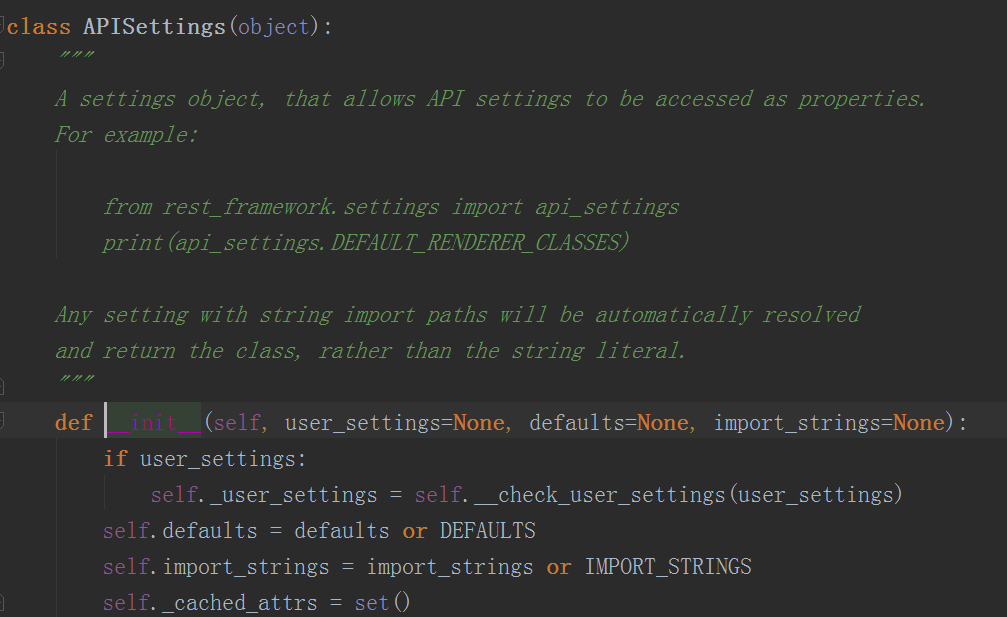
首先我们发现,如果我们没有传值,这个defaults会有一个默认的内容DEFAULTS
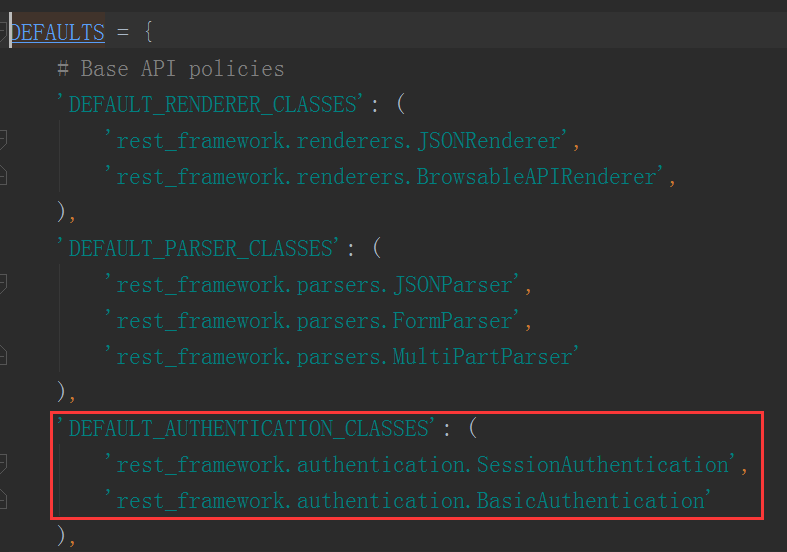
这就是我们不做任何配置时系统自动进行的认证内容,但是这是个字典的内容,我们为什么能直接点出它的内容呢,我们发现在这个类中有个__getter__方法
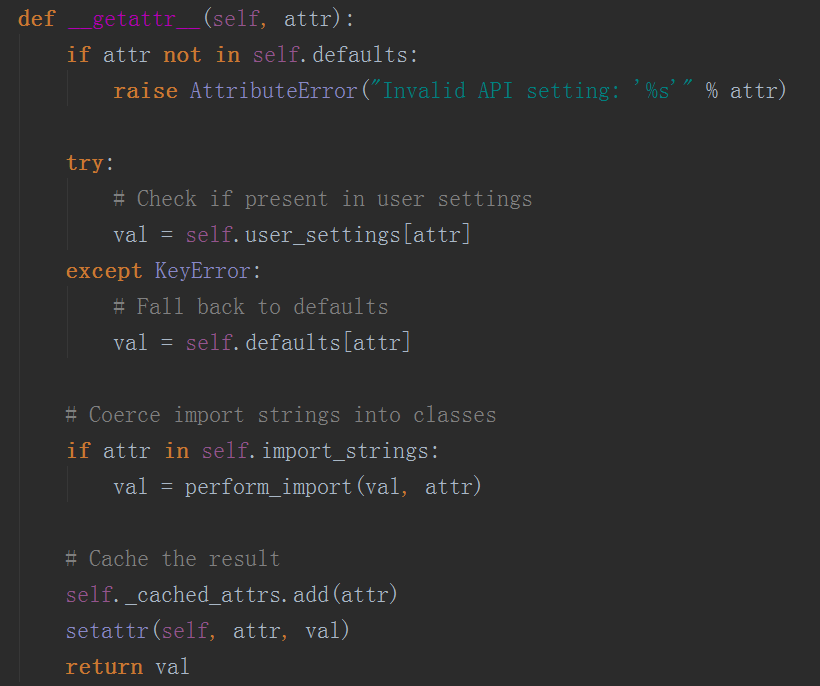
在这个方法中,我们发现他通过val = self.defaults[attr]直接取值了,那么上面还有一个val = self.user_settings[attr],当它取值出错时才会去默认的defaults中取值
那么这个user_settings是什么呢
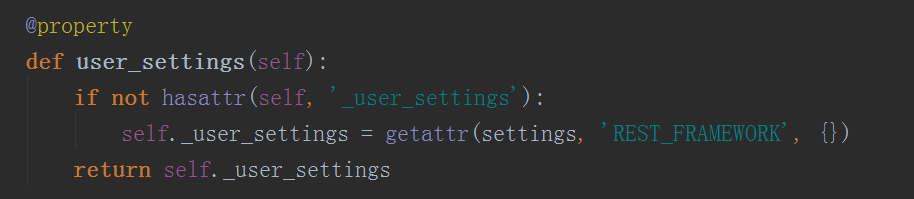
可以看到它就是我们在settings中配置的REST_FRAMEWORK,所以当我们要做全局认证时只要在settings中配置REST_FRAMEWORK并且里面的键叫做DEFAULT_AUTHENTICATION_CLASSES即可
权限组件
局部视图权限
from rest_framework.permissions import BasePermission
class SVIPPermission(BasePermission):
message="SVIP才能访问!"
def has_permission(self, request, view):
if request.user.user_type==3:
return True
return False
权限组件的原理与上面的认证组件类似,这里就不再赘述,可以参考源码
可以看到也是先定义一个权限类,类中必须有has_permission方法,这个方法返回Ture或者False
from app01.service.permissions import *
class BookViewSet(generics.ListCreateAPIView):
permission_classes = [SVIPPermission,]
queryset = Book.objects.all()
serializer_class = BookSerializers
在视图类中同样是加一个参数permission_classes
全局视图权限
在settings中配置
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",],
"DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",]
}
hrottle(访问频率)组件
局部视图throttle
和认证、权限组件一样,首先我们要定义一个频率类
from rest_framework.throttling import BaseThrottle,SimpleRateThrottle
import time
VISITED_RECORD={}
class VisitThrottle(BaseThrottle):
def __init__(self):
self.history=None
def allow_request(self,request,view):
print("ident",self.get_ident(request))
#visit_ip=request.META.get('REMOTE_ADDR')
visit_ip=self.get_ident(request)
print(visit_ip)
ctime=time.time()
#第一次访问请求
if visit_ip not in VISITED_RECORD:
VISITED_RECORD[visit_ip]=[ctime]
return True
# self.history:当前请求IP的记录列表
self.history = VISITED_RECORD[visit_ip]
print(self.history)
# 第2,3次访问请求
if len(VISITED_RECORD[visit_ip])<3:
VISITED_RECORD[visit_ip].insert(0,ctime)
return True
if ctime-VISITED_RECORD[visit_ip][-1]>60:
VISITED_RECORD[visit_ip].pop()
VISITED_RECORD[visit_ip].insert(0,ctime)
print("ok")
return True
return False
def wait(self):
import time
ctime = time.time()
return 60 - (ctime - self.history[-1])
这个类中必须有一个allow_request方法和wait方法,期中allow_request中放我们的逻辑,这里我们限制同一个ip每分钟只能进行3次访问,如果超过了就返回False,不超过在返回True
在逻辑中我们先定义了一个空的字典,当一个ip来访问时,我们先判断这个ip在不在字典中,如果不在,说明是第一次访问,那么在字典中添加一个键值对,键为这个ip,值为当前访问时间戳的列表
当这个ip第2次或第3次来访问时,由于列表中的时间戳小于3个,所以直接将访问的时间戳插入进去就行了,第4次访问时,我们就拿访问的时间戳减去列表中的最后一个值,如果大于60,说明当前这次访问与第一次访问的间隔超过了1分钟,没有超过我们的访问频率要求,所以我们将新的时间戳加入列表,并将原来列表最后的值删掉(保证列表中最多只有3个值),如果结果小于60则表示访问频率过高,返回False限制访问
wait函数的返回值就是我们还有多少秒能再次访问,定义好这个类后,在我们视图类中像使用
class BookViewSet(ModelViewSet):
authentication_classes = [MyAuthentication,]
permission_classes = [SVIPPermission]
throttle_classes = [VisitThrottle]
queryset = Book.objects.all()
serializer_class = BookSerializers
这里我们用到的是throttle_classes参数,这样book表就能享受到访问频率限制了
全局视图throttle
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",],
"DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",],
"DEFAULT_THROTTLE_CLASSES":["app01.service.throttles.VisitThrottle",]
}
和上面两个组件一样,在settings中配置DEFAULT_THROTTLE_CLASSES
内置throttle类
BaseThrottle,在上面的局部使用中,我们可以看到我们继承了BaseThrottle类,这个类中有几个方法
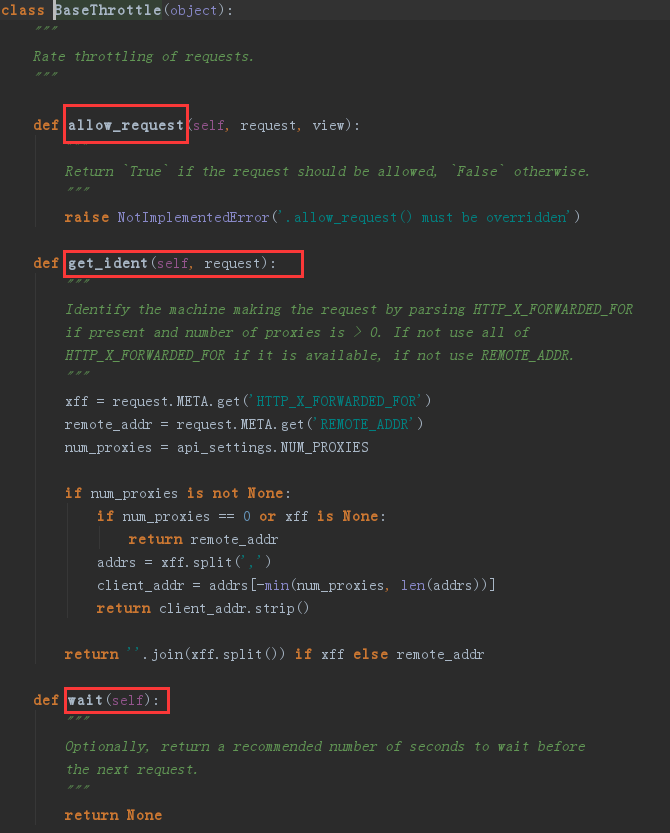
可以看到里面已经有了我们用到的allow_request和wait方法,所以我们可以不写wait,但是allow_request要求要被覆盖,这里还有一个get_ident方法,通过这个方法我们可以直接获取访问的ip地址
SimpleRateThrottle
class VisitThrottle(SimpleRateThrottle):
scope="visit_rate"
def get_cache_key(self, request, view):
return self.get_ident(request)
继承这个类后,我们在其中定义一个scope属性,通过这个属性的值我们可以在settings中配置访问频率,还要定义一个get_cache_key方法,返回访问的ip地址
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",],
"DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",],
"DEFAULT_THROTTLE_CLASSES":["app01.service.throttles.VisitThrottle",],
"DEFAULT_THROTTLE_RATES":{
"visit_rate":"5/m",
}
}
在settings中配置DEFAULT_THROTTLE_RATES
解析器
request类
django的request类和rest-framework的request类的源码解析
django的request对象是通过from django.core.handlers.wsgi import WSGIRequest类实例化来的,通过它我们可以找到许多我们在request中使用的方法
而rest-framework中对request又进行了封装
在使用django的request对象时,如果数据是以application/x-www-form-urlencoded格式发来的,那么我们可以在request.POST和request.GET中拿到数据,如果是别的形式的数据,那么我们能从request.body中拿到源数据
而在rest-framework的request中,不论数据什么格式,我们都是从request.data中拿数据,其实rest-framework的request中有好几个解析器,分别解析不同格式的数据,如果我们要定义一个解析器,可以在视图类中加上一个参数
from rest_framework.parsers import JSONParser,FormParser
class PublishViewSet(generics.ListCreateAPIView):
parser_classes = [FormParser,JSONParser]
queryset = Publish.objects.all()
serializer_class = PublshSerializers
def post(self, request, *args, **kwargs):
print("request.data",request.data)
return self.create(request, *args, **kwargs)
parser_classes参数就是来定义我们使用的解析器的,我们来看看rest-framework中都自带了哪些解析器
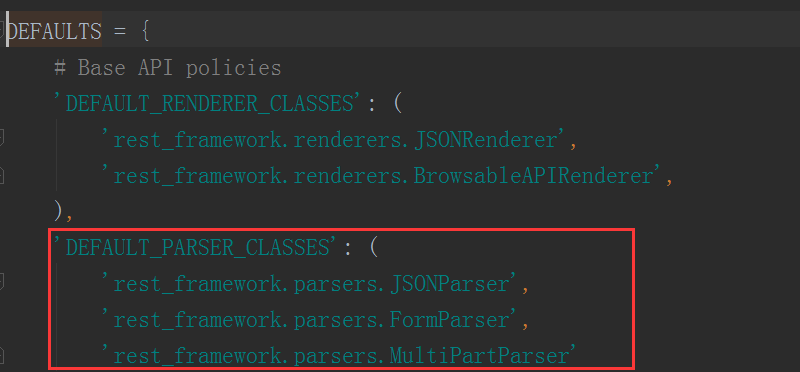
可以看到默认情况下,有3个解析器,分别解析json、formdata和另外形式的数据,基本已经够我们使用了,一般情况下我们是不需要再自己定义的
我们可以使用的一共有这么几个解析器from rest_framework.parsers import JSONParser,FormParser,FileUploadParser,MultiPartParser
如果要在全局配置中定义使用的解析器,可以在settings中配置
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",],
"DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",],
"DEFAULT_THROTTLE_CLASSES":["app01.service.throttles.VisitThrottle",],
"DEFAULT_THROTTLE_RATES":{
"visit_rate":"5/m",
},
"DEFAULT_PARSER_CLASSES":['rest_framework.parsers.FormParser',]
}
分页
简单分页
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination
class PNPagination(PageNumberPagination):
page_size = 1 # 每一页显示的数量
page_query_param = 'page' # url上的分页参数
page_size_query_param = "size" # 在url上可以通过这个参数来调整每一页显示的数量
max_page_size = 5 # 每一页上最多显示的数量,不论上面设置的size定多少都不会超过这个
class BookViewSet(viewsets.ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookSerializers
def list(self,request,*args,**kwargs):
book_list=Book.objects.all()
pp=LimitOffsetPagination()
pager_books=pp.paginate_queryset(queryset=book_list,request=request,view=self)
print(pager_books)
bs=BookSerializers(pager_books,many=True)
#return Response(bs.data)
return pp.get_paginated_response(bs.data)
这里我们使用了分页类PageNumberPagination,我们可以直接使用它来实例化,也可以写一个类来继承它,这样可以重新定义一些参数
我们在视图类中重新写了list方法,先拿到book_list,然后通过分页类实例化一个对象,然后通过这个对象的paginate_queryset方法获得新的数据类型,利用序列化类进行序列化
在return时再利用get_paginated_response方法返回更多的信息
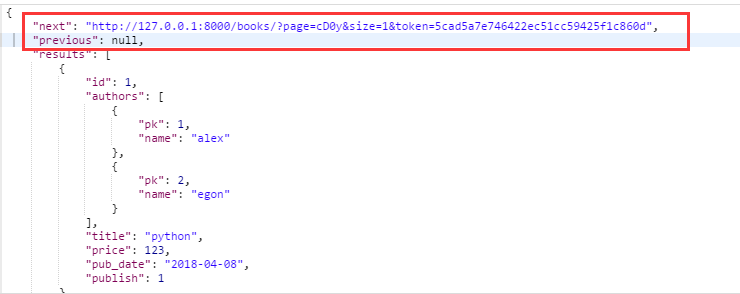
可以看到返回的数据上多出了上一页和下一页的链接
上面的方法我们需要重写我们的list等方法才能实现分页,其实我们也可以像用其它组件一样,在视图类中加一个参数来实现局部的分页
class BookViewSet(ModelViewSet):
renderer_classes = [JSONRenderer,BrowsableAPIRenderer]
authentication_classes = [MyAuthentication,]
permission_classes = [SVIPPermission]
throttle_classes = [VisitThrottle]
queryset = Book.objects.all()
serializer_class = BookSerializers
pagination_class = MyPageNumberPagination
pagination_class参数就是我们要定义的
偏移分页
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination class MyPageNumberPagination(LimitOffsetPagination):pass
继承了这个类后我们来看看有什么参数
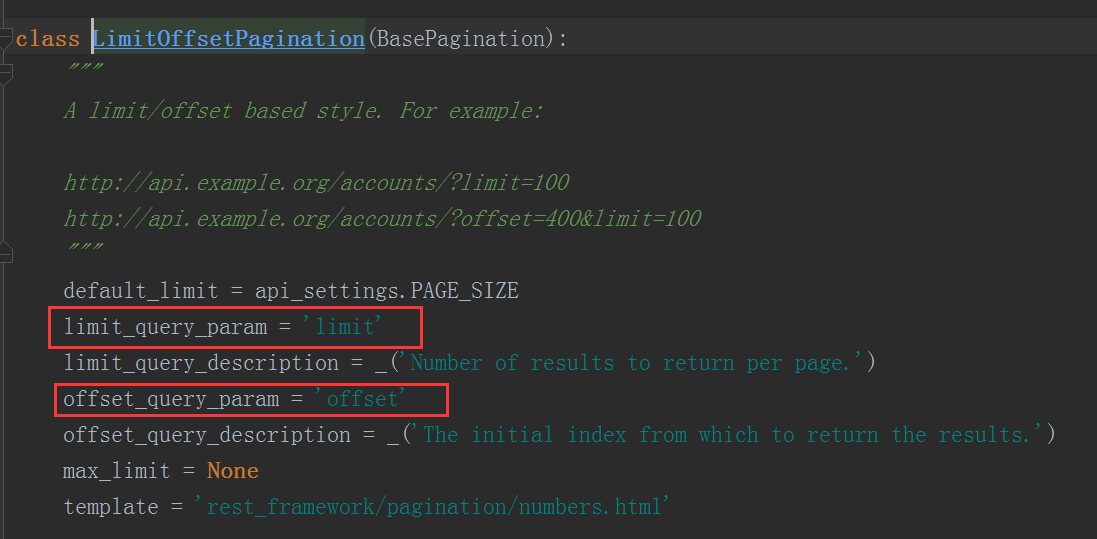
offset是开始时的索引,limit是显示几条,这样就能决定在页面上显示多少信息
CursorPagination
class MyPageNumberPagination(CursorPagination):
cursor_query_param="page"
page_size=2
ordering="id"
继承这个类后,我们在看到页面上数据的上一页和下一页的信息时,会对页码进行加密
路由
在前面的代码中路由都是我们自己写的,其实rest-framework已经帮我们做了封装,我们只要引用就可以自动生成路由了
from django.conf.urls import url,include
from django.contrib import admin
from api import views
from rest_framework import routers
router = routers.DefaultRouter()
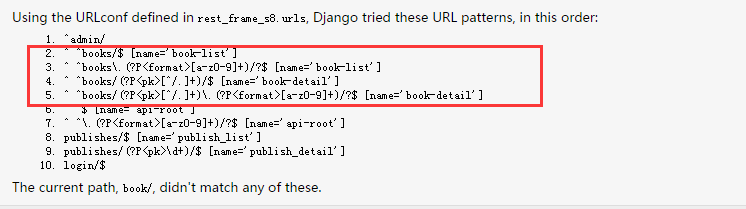
router.register(r'books', views.BookViewSet)
urlpatterns = [
url(r'^admin/', admin.site.urls),
# url(r"books.(?P<format>w+)$",views.BookViewSet.as_view({"get":"list","post":"create"}),name="book_list"),
# url(r"books/$",views.BookViewSet.as_view({"get":"list","post":"create"}),name="book_list"),
# url(r"books/(?P<pk>d+)/$",views.BookViewSet.as_view({"get":"retrieve","delete":"destroy","put":"update"}),name="book_detail"),
# url(r"books/(?P<pk>d+).(?P<format>w+)$",views.BookViewSet.as_view({"get":"retrieve","delete":"destroy","put":"update"}),name="book_detail"),
url(r'^', include(router.urls)),
url(r"publishes/$",views.PublishView.as_view(),name="publish_list"),
url(r"publishes/(?P<pk>d+)/$",views.PublishDetailView.as_view(),name="publish_detail"),
url("login/$",views.LoginView.as_view())
]
这里导入routers,然后通过DefaultRouter实例化一个对象,再通过register注册,最后在url中写上url(r'^', include(router.urls)),就会自动帮我们生成books相关的路由了,一共4条,就是上面注释的内容
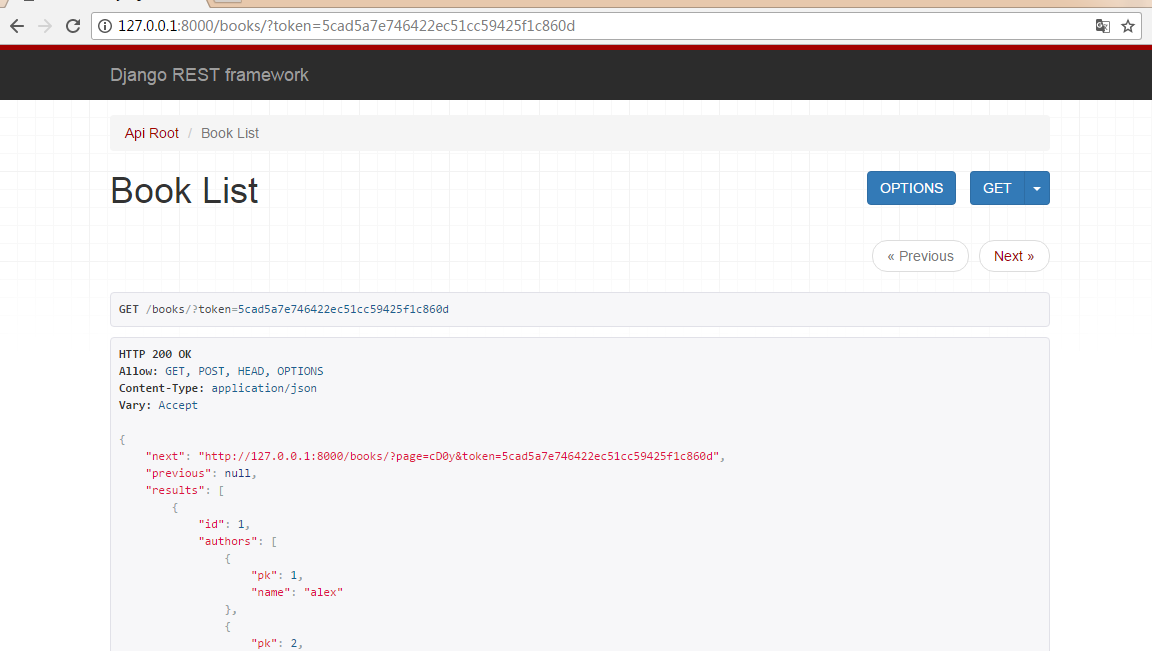
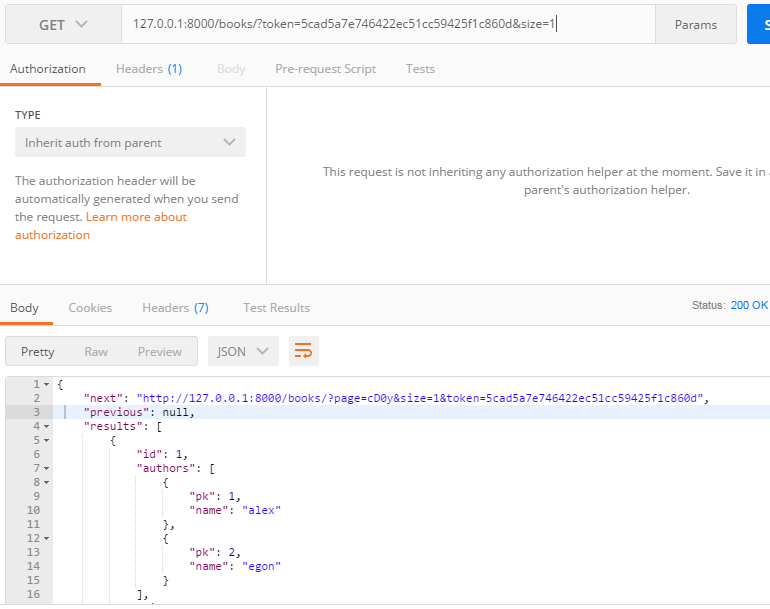
响应器
我们可以发现,当我们用浏览器访问时是会返回页面的(必须在settings中注册rest-framework,否则会报错),而用postman等工具返回时只会返回json数据,这是为什么呢
浏览器访问
postman访问
其实这是由响应器决定的
from api.service.page import *
from rest_framework.renderers import BrowsableAPIRenderer,JSONRenderer
class BookViewSet(ModelViewSet):
renderer_classes = [JSONRenderer,BrowsableAPIRenderer]
authentication_classes = [MyAuthentication,]
permission_classes = [SVIPPermission]
#throttle_classes = [VisitThrottle]
queryset = Book.objects.all()
serializer_class = BookSerializers
pagination_class = MyPageNumberPagination
# parser_classes = [JSONParser]
这里renderer_classes参数定义的就是响应器,其中JSONRenderer是用来响应postman等工具的,响应结果就是json数据,而BrowsableAPIRenderer响应的浏览器页面,如果想要改变响应的形式只要修改这个参数即可