并发编程
进程
顾名思义,进程即正在执行的一个过程。进程是对正在运行程序的一个抽象。
进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的
必备的理论基础

#一 操作系统的作用:
1:隐藏丑陋复杂的硬件接口,提供良好的抽象接口
2:管理、调度进程,并且将多个进程对硬件的竞争变得有序
#二 多道技术:
1.产生背景:针对单核,实现并发
ps:
现在的主机一般是多核,那么每个核都会利用多道技术
有4个cpu,运行于cpu1的某个程序遇到io阻塞,会等到io结束再重新调度,会被调度到4个
cpu中的任意一个,具体由操作系统调度算法决定。
2.空间上的复用:如内存中同时有多道程序
3.时间上的复用:复用一个cpu的时间片
强调:遇到io切,占用cpu时间过长也切,核心在于切之前将进程的状态保存下来,这样
才能保证下次切换回来时,能基于上次切走的位置继续运行
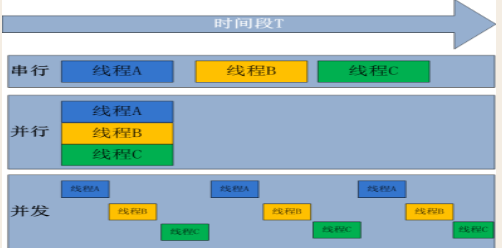
并行与并发
并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
并行:同时运行,只有具备多个cpu才能实现并行
IO阻塞
从磁盘读取数据是有延迟的,磁头寻道的平均延时为5毫秒,在磁道上找到数据的平均延时为4毫秒,在IO阻塞的时间里,cpu就不会继续工作,这是操作系统就会把cpu分配给其它程序
使用multiprocessing模块开启进程
from multiprocessing import Process
import time
# win 创建进程接口 CreateProcess linux为fork
# linux系统子进程的初始状态和父进程完全一样,win上不完全一样
def task(name):
print('%s is running'%name)
time.sleep(2)
print('%s is done' % name)
if __name__ == '__main__':
# Process(target=task,kwargs={'name':'egon'})
p = Process(target=task,args=('egon',))
p.start()
print('主')
开启进程的两种方式
# 方式一
from multiprocessing import Process
import time
def task(name):
print('%s is running'%name)
time.sleep(2)
print('%s is done' % name)
if __name__ == '__main__':
p = Process(target=task,args=('egon',))
p.start()
print('主')
# 方式二
from multiprocessing import Process
import time
class Myprocess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print('%s is running' % self.name)
time.sleep(2)
print('%s is done' % self.name)
if __name__ == '__main__':
p = Myprocess('egon')
p.start()
print('主')
Process对象的属性和方法
# 运行一个python文件其实是用python解释器去执行
# import time,os
# print(os.getpid(),os.getppid()) # pid当前进程的进程号,ppid父进程的进程号
# time.sleep()
from multiprocessing import Process
import time
def task(name):
print('%s is running'%name)
time.sleep(2)
print('%s is done' % name)
if __name__ == '__main__':
p = Process(target=task,args=('egon',),name='xxx')
p.start()
# print(p.name) # 打印进程的名字
# print(p.pid) # 进程号
# print(p.is_alive()) # 是否存活
# p.terminate() # 杀死进程,向操作系统发出指令,不要用
# p.join() # join(p) 等待p执行完 p.join(timeout=2) 可以指定超时时间,一般不用
print('主')
进程池
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。多进程是实现并发的手段之一,需要注意的问题是:
- 很明显需要并发执行的任务通常要远大于核数
- 一个操作系统不可能无限开启进程,通常有几个核就开几个进程
- 进程开启过多,效率反而会下降(开启进程是需要占用系统资源的,而且开启多余核数目的进程也无法做到并行)
例如当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个。。。手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
我们就可以通过维护一个进程池来控制进程数目,比如httpd的进程模式,规定最小进程数和最大进程数
创建进程池的类:如果指定numprocess为3,则进程池会从无到有创建三个进程,然后自始至终使用这三个进程去执行所有任务,不会开启其他进程
'''
提交/调用任务的方式有两种:
同步调用:提交/调用一个任务,然后就在原地等着,等到该任务执行完毕拿到结果,再执行下一行代码
异步调用:提交/调用一个任务,不在原地等着,直接执行下一行代码,结果
'''
# from multiprocessing import Process,Pool
from concurrent.futures import ProcessPoolExecutor
import time,random,os
def piao(name):
print('%s is piaoing %s'%(name,os.getpid()))
time.sleep(random.randint(1,3))
if __name__ == '__main__':
p = ProcessPoolExecutor(4) # 从始至终只有4个进程干活,进程号不变
objs = []
for i in range(10):
obj = p.submit(piao,'alex%s'%i)
# obj.result() # 进程运行的结果
# res = p.submit(piao,'alex%s'%i).result() # 同步调用,要等待任务的执行结果
# obj = p.submit(piao, 'alex%s'%i) # 异步调用
objs.append(obj)
for i in objs:
print(i.result())
p.shutdown(wait=True) # 等待进程池中的任务都干完,同时禁止往池中添加任务了
# 使用Pool时,分两步 pool.close() pool.join()
print('主',os.getpid())