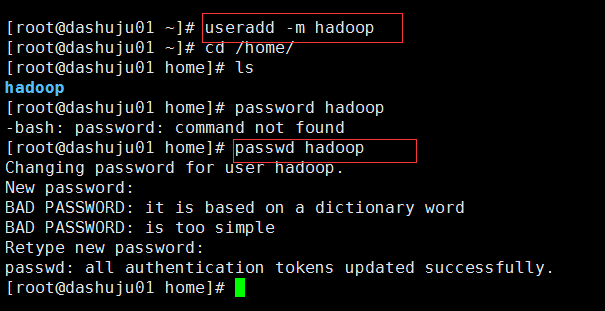
1.创建hadoop账户,创建用户的home目录并设置密码。(useradd -m hadoop )
2.本步骤可以不做(我是为了方便,给hadoop赋予了root权限)(vi /etc/sudoers)



以上的设置使用sudo不用输入密码
(注意:要在root用户下且修改完成要esc :wq保存)
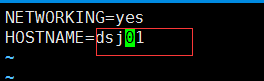
3.修改主机名(如果你不想修改,跳过此步骤)
(1)0本次有效的方法,重启后就失效(hostname dsj01)

用户重新登陆下

(2)永久修改的方法(vi /ec/sysconfig/network),然后重启(init 6或者reboot)。


4.检查防火墙状态,如果是打开的,就关闭它。
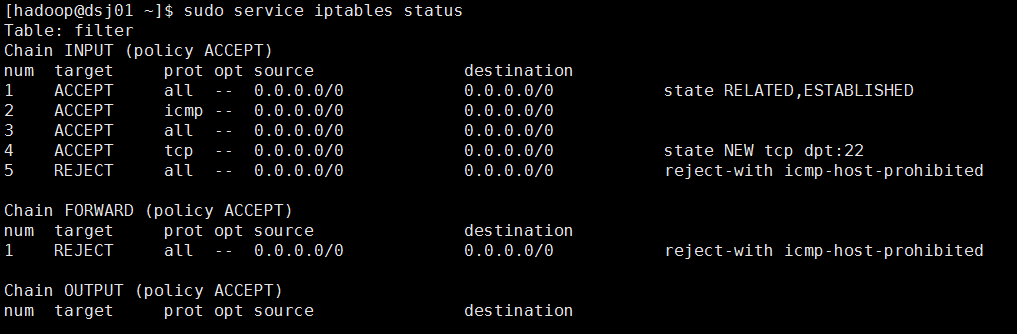
(1)单次启动/关闭防火墙(service iptables on/off)
(2)永久启动/关闭防火墙(chkconfig iptables on/off),关闭后要重启。


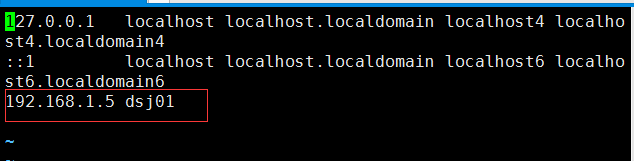
5.将ip与主机名对应信息写入到/etc/hosts文件

6.配置ssh免密码登录(Hadoop 启动或者停止脚本时需要通过SSH发送命令启动相关守护进程,为了避免每次启动或者停止Hadoop输入密码进行验证,需设置免密码登录。)
(1)在hadoop根目录下创建.ssh文件目录。
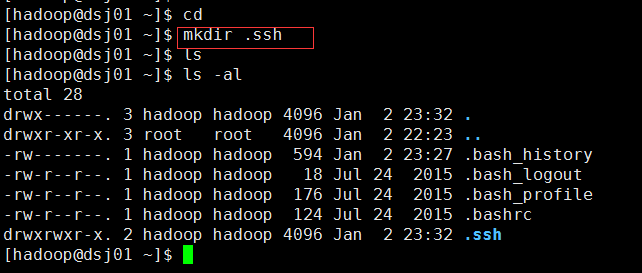
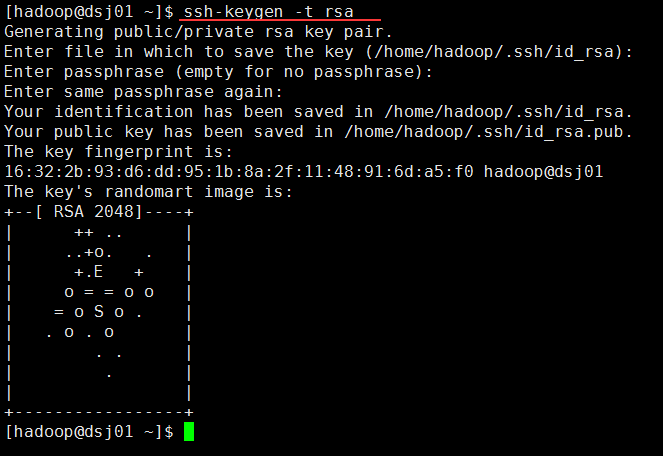
(2)生成公钥文件id_rsa.pub和私钥文件id_rsa,此操作一直按回车键即可。
(3)将公钥文件id_rsa.pub 中的内容复制到相同目录下的authorized_keys文件中

(4)切换到hadoop用户的根目录,为.ssh目录授权

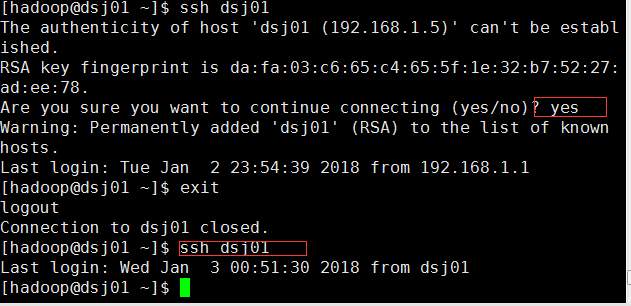
(5)使用ssh 登录djt,第一次登陆需要输入yes,第二次以后登录就不需要密码,此时表明设置成功
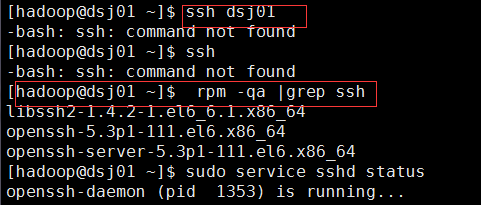
检查是因为openssh-client这个客户端没安装。
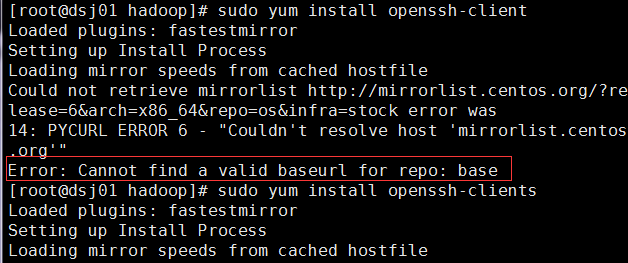
依然报错了,是依赖的问题。(配置DNS来解决)
在物理机的网络中心配置:
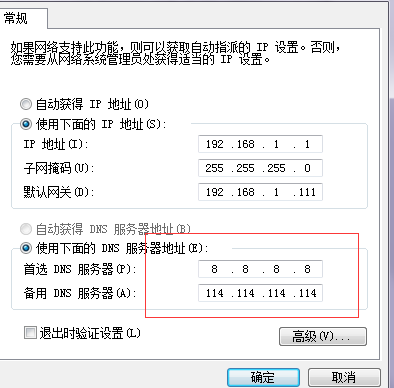
在ifcfg-eth0中配置:
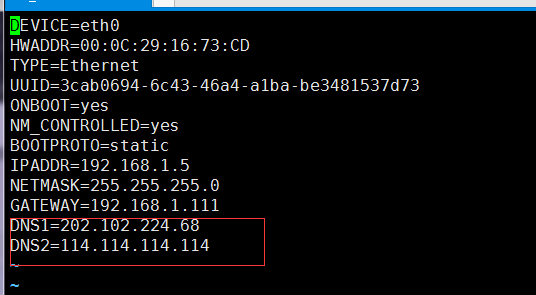
然后安装客户端:
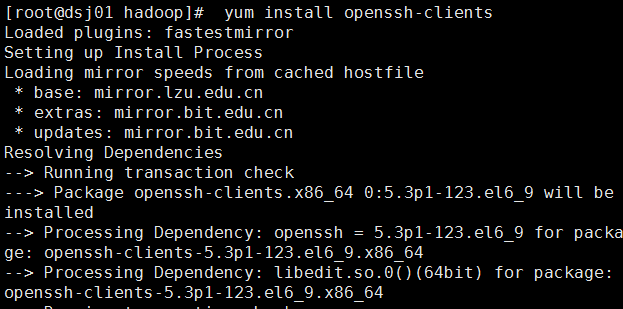
完成后,ssh登录。
7.下载jdk1.7并上传到/home/hadoop/app目录下将其解压并重命名为jdk。
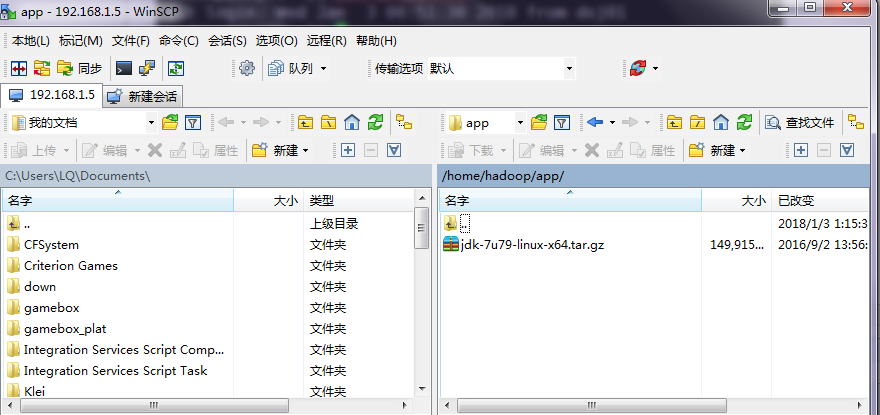
解压:

重命名:
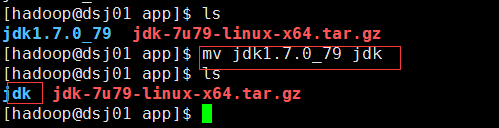
配置环境变量:


jdk安装成功:

8.下载hadoop2.6安装包并上传,解压并重命名为hadoop。
解压:

重命名:

配置环境变量:
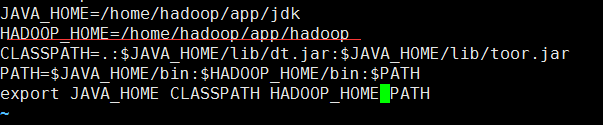
进入hadoop/etc/hadoop目录,查看相关配置文件:
(1)修改core-site.xml配置文件
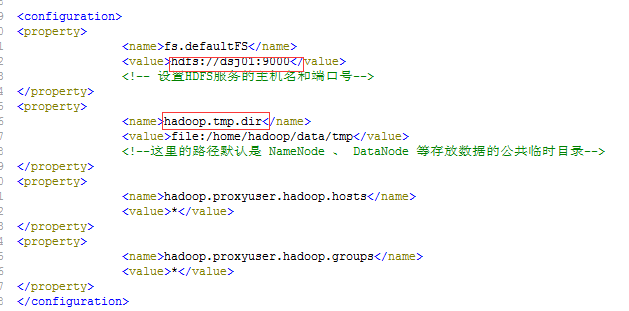
(2)修改hdfs-site.xml配置文件

(3)修改hadoop-env.sh配置文件
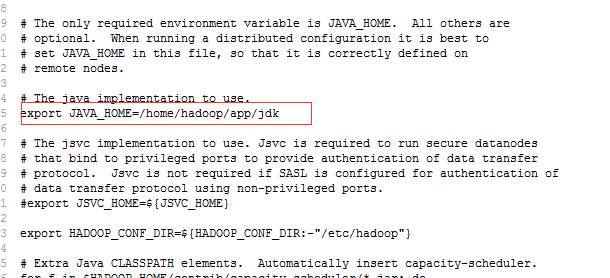
(4)修改mapred-site.xml配置文件

(5)修改yarn-site.xml配置文件

(6)修改slaves配置文件

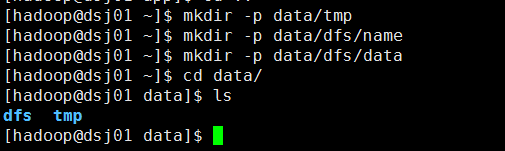
创建hadoop相关目录:
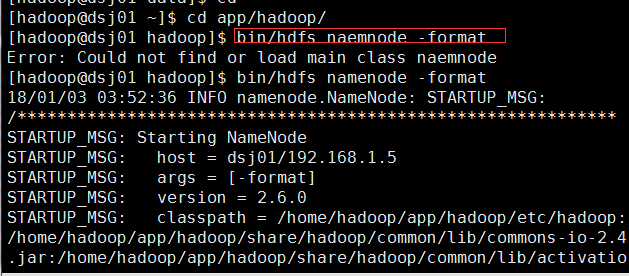
格式化namenode:第一次安装Hadoop集群的时候需要格式化Namenode,以后直接启动Hadoop集群即可,不需要重复格式化Namenode。
启动伪分布集群:
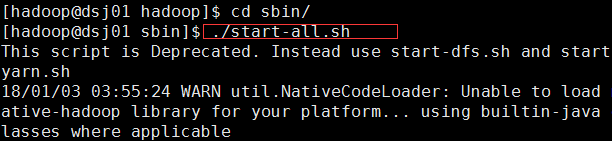
启动成功后:
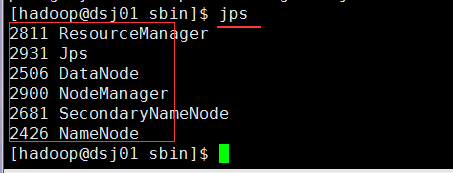
通过WEB UI查看结果:
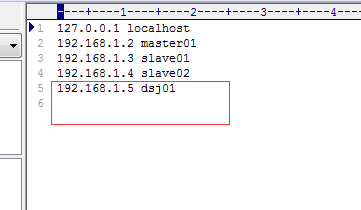
进入C:WindowsSystem32driversetc 目录下,将ip与主机名添加到hosts文件里。
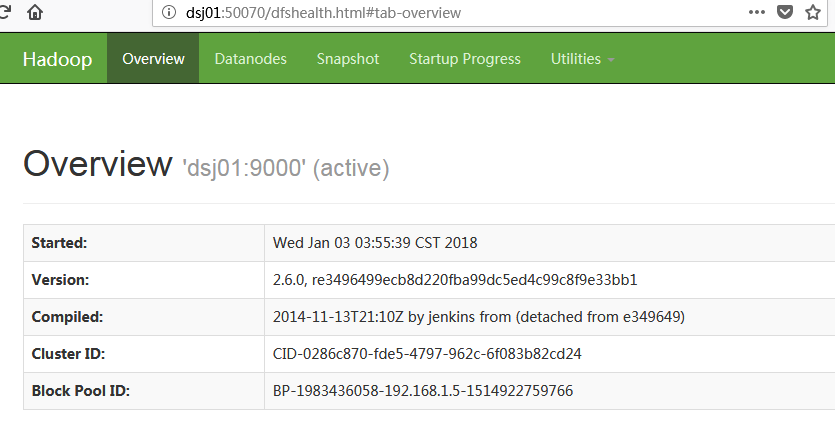
通过dsj01:50070进行访问hdfs:
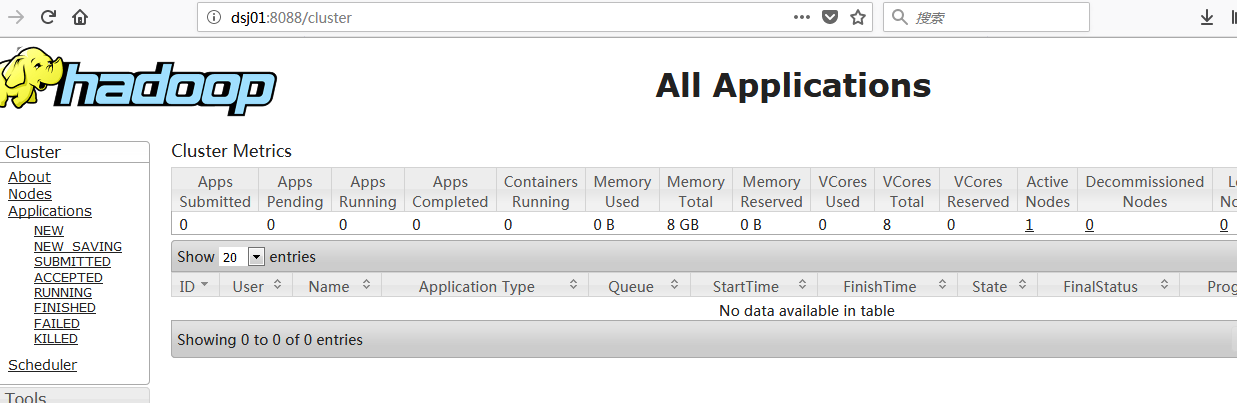
通过dsj01:8080访问yarn:
9.测试运行伪分布式
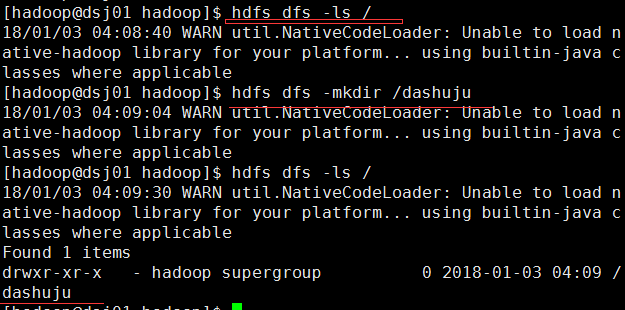
创建dashuju目录:
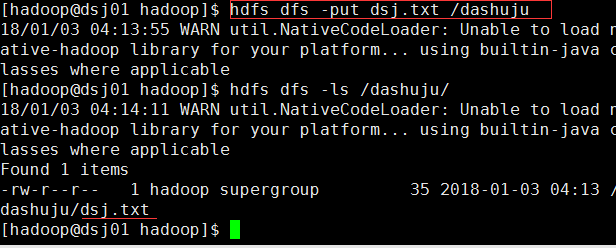
创建一个dsj.txt文件并上传到dashuju目录下:
运行Hadoop例子中自带的wordcount程序:
使用 bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /dashuju/dsj.txt /dashuju/output命令,其中/dashuju/dsj.txt是输入的原文件,/dashuju/output是输出路径。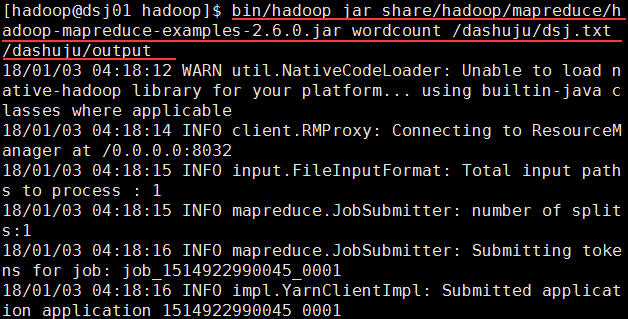
查看统计结果:
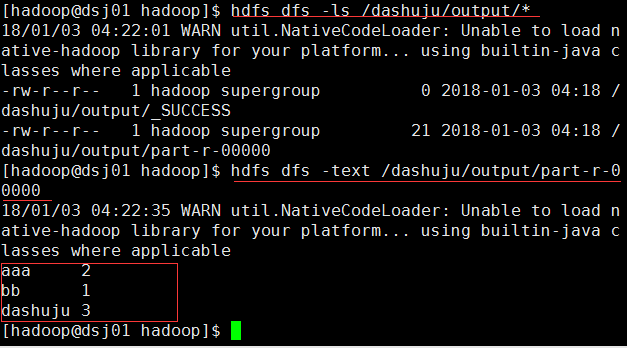
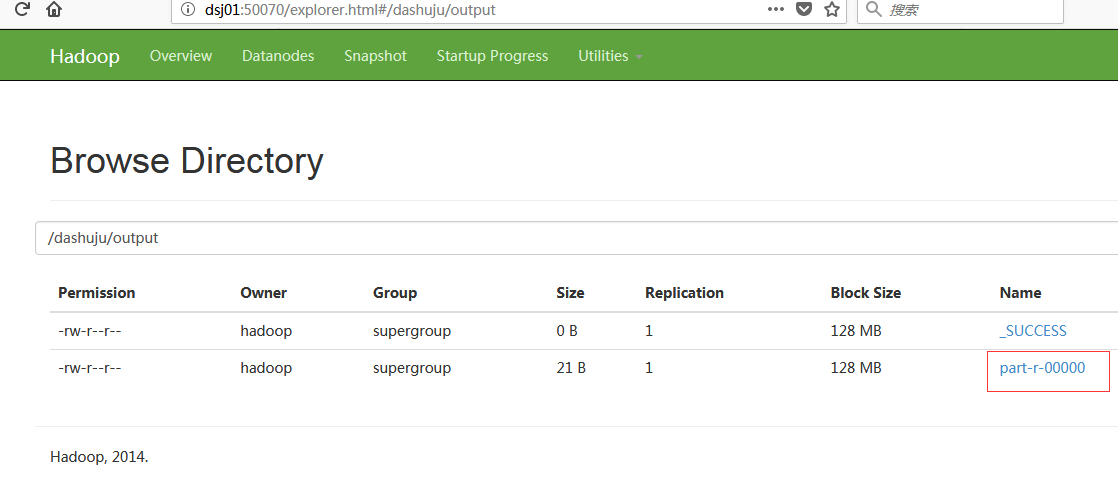
通过WEB UI查看统计结果:
到此,hadoop伪分布式搭建完成。