GlusterFS实战
预装glusterfs软件包
yum -y install centos-release-gluster37.noarch
yum --enablerepo=centos-gluster*-test install glusterfs-server glusterfs-cli glusterfs-geo-replication
1.理论基础
1.1 分布式文件系统的出现
计算机通过文件系统存储数据
分布式文件系统可以有效解决数据存储和管理的难题,将固定于某个地点的文件系统,扩展到任意多个地点,只有
有网络的地方就可以访问
1.2典型代表NFS
NFS及网络文件系统
1,节约磁盘空间
2,节约硬件资源
3,用户目录设定
1.3面临的问题
存储空间不足,需要更大容量的存储
有一定风险,存在单点故障
某些场景不能满足要求,大量的访问磁盘IO是瓶颈
1.4GlusterFS概述
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力
,通过扩展能够支持数FB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存
储资源聚集在一起,使用单一全局命名空间来管理数据。
1.5GlusterFS在企业的应用场景
GlusterFS目前主要适用大文件存储场景,对于小文件尤其是海量小文件,存储效率和访问性能表现不佳。海量小文件LOSF问题是工业界和学术界公认的难题,GlusterFS作为通用的分布式文件系统,并没有对小文件做额外的优化措施,性能
不好也是可以理解的。
Media
- 文档,图片,音频,视频
Shared storage
- 云存储,虚拟化存储,HPC(高性能运算)
Big data
- 日志文件,数据
2.GlusterFS安装
2.1GlusterFS安装前准备
虚拟机(CentOS6.5)数台
关闭iptables和selinux
修改主机名
10.0.0.153 mystorage1
10.0.0.154 mystorage2
修改hosts添加解析
2.2安装
yum -y install centos-release-gluster37.noarch
PS:如果是centos7则可以先使用yum list|grep gluster查看最新的版本然后再安装
使用CentOS7.4需要安装yum -y install centos-release-gluster39.noarch否则在下一步安装的时候会报依赖错误
yum --enablerepo=centos-gluster*-test install glusterfs-server glusterfs-cli glusterfs-geo-replication
2.3启动(CentOS6和7启动命令不同)
启动:/etc/init.d/glusterd start
停止:/etc/init.d/glusterd stop
查看版本
glusterfs -V
2.3存储主机加入存储池
gluster peer probe 10.0.0.154
PS:在其中一台主机操作即可,其次这里需要使用IP不能使用主机名,使用主机名可能会导致挂载不成功报错为Mount failed. Please check the log file for more details
查看主机状态
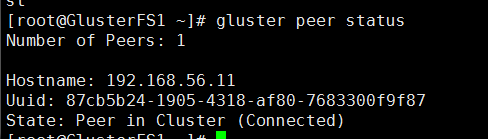
gluster peer status
第一台主机查看
可以看到有一台IP是另外一台主机的IP 状态是连接状态
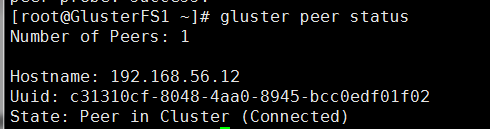
第二台主机查看
安装xfs支持包(centos7系统不需要安装,ext4也可以,大容量需要xfs)
yum -y install xfsprogs
新加一块数据盘(可以不分区直接格式化)
mkfs.xfs /dev/sdb
建立挂载的目录
mkdir -p /storage/brick1/
挂载
mount /dev/sdb /storage/brick1/
自动挂载
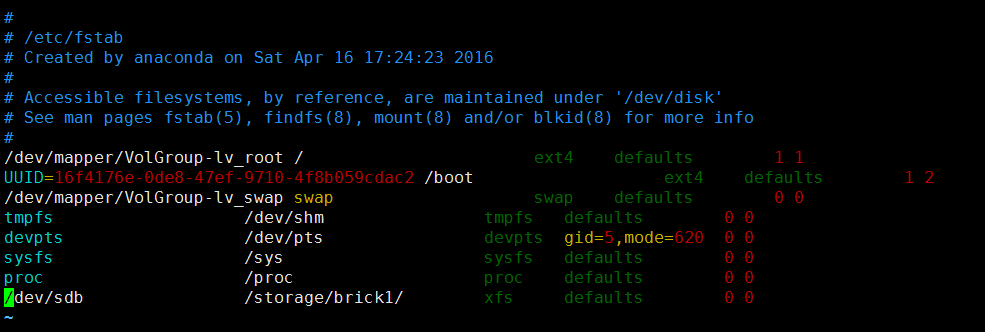
创建volume及其他操作
分布式卷,复制式卷,条带式卷,分布式条带卷,分布式的复制卷
创建分布卷
gluster volume create gv1 10.0.0.153:/storage/brick1 10.0.0.154:/storage/brick1 force
启动卷
gluster volume start gv1
查看状态
gluster volume info(两台机器都能看到)
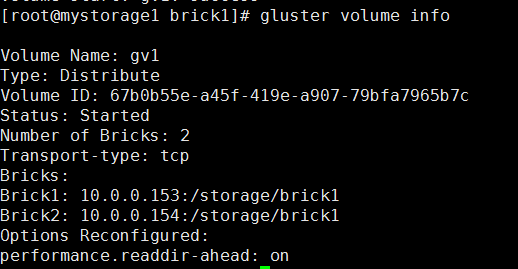
挂载
mount -t glusterfs 127.0.0.1:/gv1 /mnt
PS:对应glusterfs客户端需要安装支持glusterfs文件的软件才能挂载
|
1
|
mount -t glusterfs 192.168.0.13:/gv1 /mnt |
测试分布式
在期中一台机器的mnt什么随便创建几个文件在另外一台机器能看见
在挂载的目录一次性创建10个文件
touch {1..10}
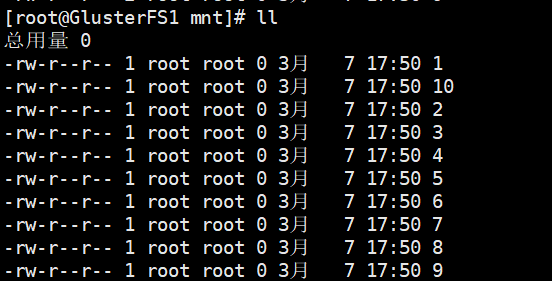
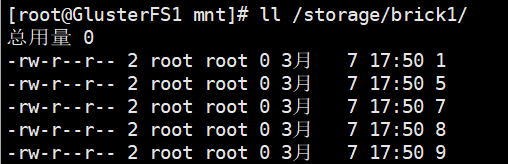
节点1的挂载目录
节点2的挂载目录
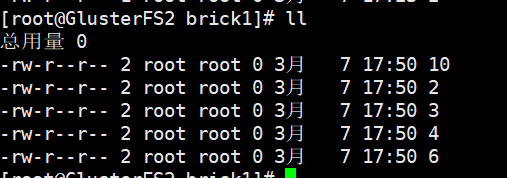
PS:分布式卷创建文件将分别在各个节点上面,假如一个节点宕机该节点存储的文件将暂时无法访问,所以在生产中一般不适应分布式卷而使用分布式复制卷
挂载以后如果gluster宕掉,只要不卸载挂载对挂载不影响,如果卸载了重新挂载那么宕机的那台服务器存储的文件将无法访问,如果是分布式复制卷则没影响
也可以使用NFS方式挂载
![]()
创建分布式复制卷
再分别新加一块硬盘(15G)
格式化,挂载
mkfs.xfs /dev/sdc
mount /dev/sdc /storage/brick2/
gluster volume create gv2 replica 2 10.0.0.153:/storage/brick2/ 10.0.0.154:/storage/brick2 force
查看信息
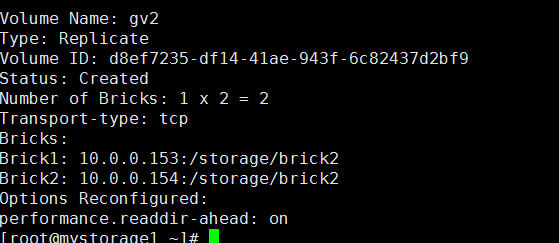
启动gluster volume start gv2
mount -t glusterfs 127.0.0.1:/gv2 /opt
同样在其中一台/opt创建文件在另外一台可以同步
PS:分布式复制卷在节点各复制一份完整文件
创建分布式条带卷
在新加一块硬盘
mkfs.xfs /dev/sdd
mkdir -p /storage/brick3
mount /dev/sdd /storage/brick3/
gluster volume create gv3 stripe 2 10.0.0.153:/storage/brick3/ 10.0.0.154:/storage/brick3/ force
gluster volume start gv3
新建一个文件夹用于挂载
mount -t glusterfs 127.0.0.1:/gv3 /gv3/
在gv3创建文件测试
dd if=/dev/zero bs=1024 count=10000 of=/gv3/10M.file
dd if=/dev/zero bs=1024 count=20000 of=/gv3/20M.file
然后在到原始的挂载目录可以看到文件大小平分了
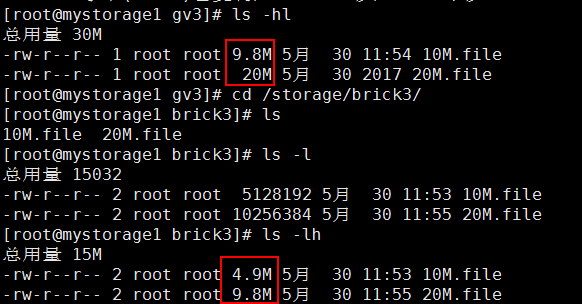
同理gv2是复制卷就没有切片
添加卷(需要停止原来的卷,添加完重新启动并挂载)
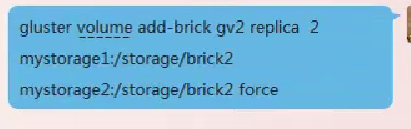
新加卷以后文件还会存储在旧的节点上面,需要做磁盘平衡
gluster volume rebalance gv2 start
移除brick(工作中使用少,复制卷需成对移除)

删除卷
先停止再删除
gluster volume stop gv1
gluster volume delete gv1
3,构架企业级分布式存储
3.1 硬件需求
一般选择2U,STAT磁盘,如果I/O要求比较高可以选择ssd硬盘,磁盘阵列卡,推荐raid10

企业一般使用分布式复制卷,不使用条带卷
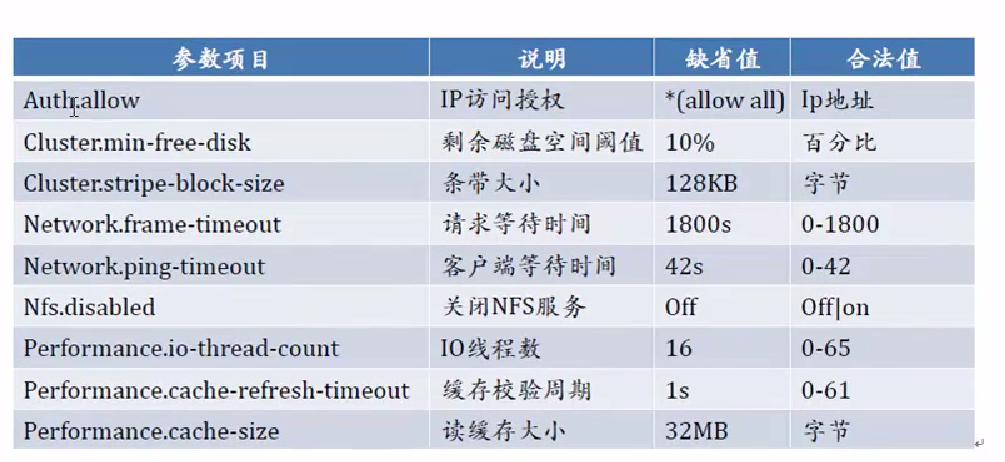
GlusterFS文件系统优化


排错:
分布式复制卷
使用mount挂载gluster卷不成功提示为Mount failed. Please check the log file for more details
原因:开始使用同样的磁盘做了分布卷,然后删除分布卷再重新创建分布式复制卷,可能原因是重装时新建的卷组和逻辑卷,导致分区后主机的uuid变了
解决办法:两个节点卸载挂载umount /storage/brick1/
把主机移除存储池gluster peer detach 192.168.0.14
重新加入存储池gluster peer probe 192.168.0.14
两个节点挂载mount /dev/vda /storage/brick1/
按照相同的步骤创建分布式复制卷