- DAG,有向无环图,Directed Acyclic Graph的缩写,常用于建模。
- Spark中使用DAG对RDD的关系进行建模,描述了RDD的依赖关系,这种关系也被称之为lineage,RDD的依赖关系使用Dependency维护,参考Spark RDD之Dependency,DAG在Spark中的对应的实现为DAGScheduler。
- DAGScheduler
- 作业(Job)调用RDD的一个action,如count,即触发一个Job,spark中对应实现为ActiveJob,DAGScheduler中使用集合activeJobs和jobIdToActiveJob维护Job
-
调度阶段(Stage ) 代表一个Job的DAG,会在发生shuffle处被切分,切分后每一个部分即为一个Stage,Stage实现分为ShuffleMapStage和ResultStage,一个Job切分的结果是0个或多个ShuffleMapStage加一个ResultStage,
-
任务(Task ) 最终被发送到Executor执行的任务,和stage的ShuffleMapStage和ResultStage对应,其实现分为ShuffleMapTask和ResultTask
-
DAG中每个节点是一个RDD
- RDD依赖关系
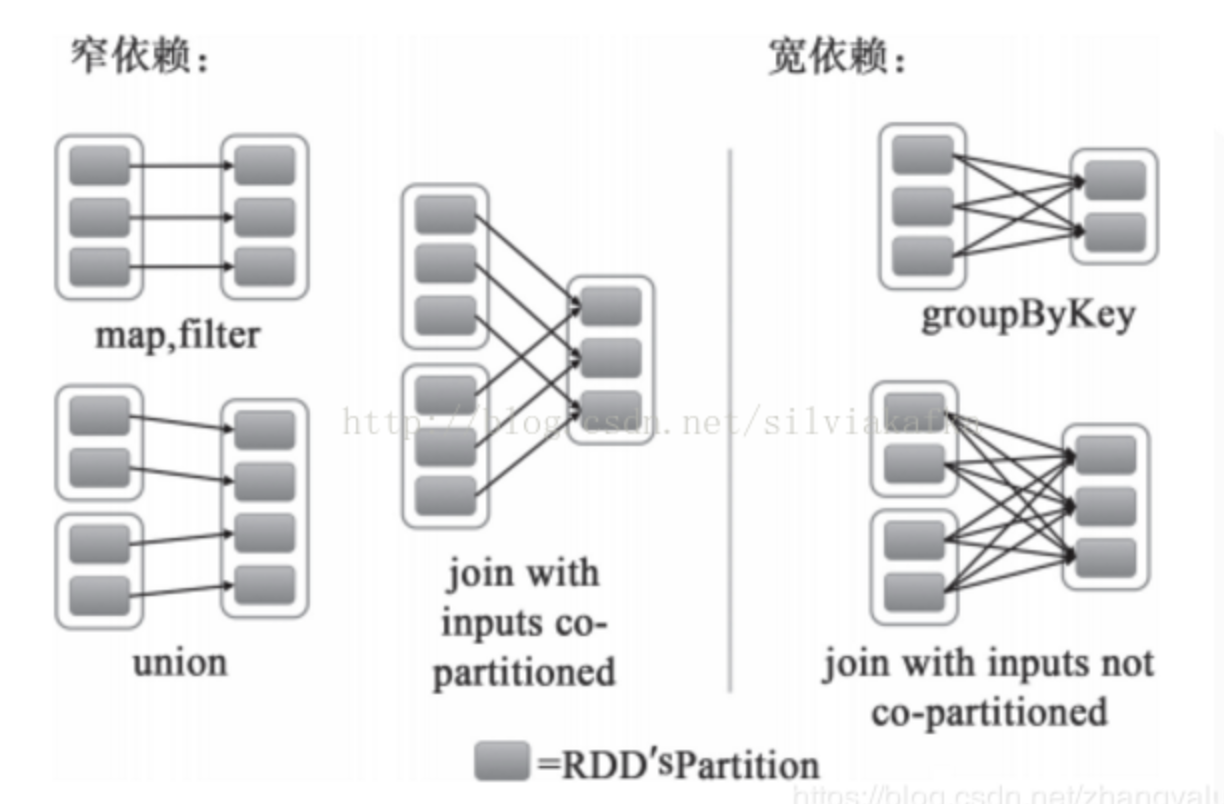
- 窄依赖 Narrow Dependency:
- 从父RDD角度看:一个父RDD只被一个子RDD分区使用。父RDD的每个分区最多只能被一个Child RDD的一个分区使用
- 从子RDD角度看: 依赖上级RDD的部分分区,精确知道依赖的上级RDD分区,会选择和自己在同一节点的上级RDD分区,没有网络IO开销,高效。如map,flatmap,filter
宽依赖 Shffule Dependency:
-
从父RDD角度看:一个父RDD被多个子RDD分区使用。父RDD的每个分区可以被多个Child RDD分区依赖
- 从子RDD角度看:依赖上级RDD的所有分区 无法精确定位依赖的上级RDD分区,相当于依赖所有分区(例如reduceByKey) 计算就涉及到节点间网络传输
- 需要shuffle
-
窄依赖可以支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败恢复也更有效,因为它只需要重新计算丢失的parent partition即可。
-
宽依赖需要所有的父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能开始计算,可能还需要调用类似MapReduce之类的操作进行跨节点传递。从失败恢复的角度看,宽依赖牵涉RDD各级的多个parent partition。
- 窄依赖 Narrow Dependency:
- 划分stage
- 由于宽依赖必须等RDD的parent RDD partition数据全部ready之后才能开始计算,因此spark的设计是让parent RDD将结果写在本地,完全写完之后,通知后面的RDD。后面的RDD则首先去读之前的本地数据作为input,然后进行运算。
- 由于上述特性,将shuffle依赖就必须分为两个阶段(stage)去做
- 第一个阶段(stage)需要把结果shuffle到本地,例如reduceByKey,首先要聚合某个key的所有记录,才能进行下一步的reduce计算,这个汇聚的过程就是shuffle
- 第二个阶段(stage)则读入数据进行处理
-
对于transformation操作,以宽依赖为分隔,分为不同的Stages。
窄依赖------>tasks会归并在同一个stage中,(相同节点上的task运算可以像pipeline一样顺序执行,不同节点并行计算,互不影响)
宽依赖------>前后拆分为两个stage,前一个stage写完文件后下一个stage才能开始
action操作------>和其他tasks会归并在同一个stage(在没有shuffle依赖的情况下,生成默认的stage,保证至少一个stage)。
-
job划分原则
-
每个action函数内会调用runJob,进而调用submitJob,所以每个action会触发一个job。
job间按顺序执行,待前一个job完全成功,才能执行下一个job,所有job执行成功后,本application执行完成
- DAG划分:
- 各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分,DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,在Worker节点上启动task。
- 当RDD触发一个Action操作(如:colllect)后,导致SparkContext.runJob的执行。而在SparkContext的run方法中会调用DAGScheduler的run方法最终调用了DAGScheduler的submit方法:
- 设计:尽量多设计窄依赖,减少宽依赖。最大化本地化处理优势,减少网络IO.