复制数据的快速方法std::copy
C++复制数据各种方法大家都会,很多时候我们都会用到std::copy这个STL函数,这个效率确实很不错,比我们一个一个元素复制或者用迭代器复制都来的要快很多。
比如,我写了一段下面的代码,复制100000000数据量,std::copy的性能要比前两个性能要好。
const int size = 100000000; int *k = new int[size]; int *p = new int[size]; //const int size = 5F5E100h; DWORD t1, t2; t1 = GetTickCount(); for (int i = 0; i != size; i++) p[i] = k[i]; t2 = GetTickCount(); cout << t2 - t1 << "ms" << std::endl; t1 = GetTickCount(); int *pStart = k, *pEnd = k + size, *pDest = p; for (; pStart != pEnd; pDest++, pStart++) *pDest = *pStart; t2 = GetTickCount(); cout << t2 - t1 << "ms" << std::endl; t1 = GetTickCount(); std::copy(k, k + size, p); t2 = GetTickCount(); cout << t2 - t1 << "ms" << std::endl;
在我的机子上表现如下:
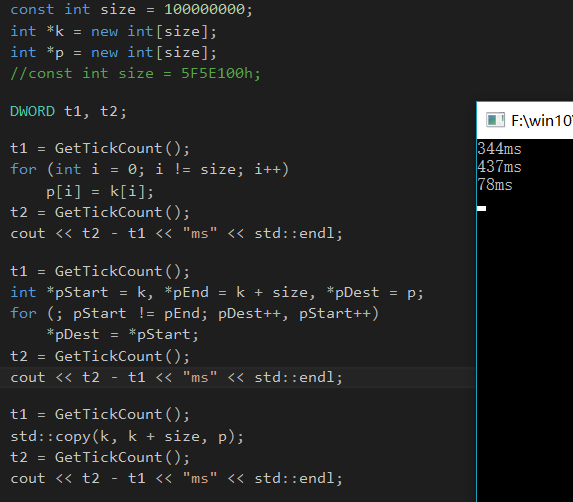

很多时候我们知道用是可以这么用,可是为什么std::copy的效率要比我们这其他两种方法的效率要好呢?为了找到真正的原因,我们必须做机器级分析了,我们不妨跟踪一下前两个方法的汇编(VS编译器,x86)
下标取值的方法(A方法):
for (int i = 0; i != size; i++) 00F0A8B1 mov dword ptr [ebp-54h],0 00F0A8B8 jmp main+0A3h (0F0A8C3h) 00F0A8BA mov eax,dword ptr [ebp-54h] 00F0A8BD add eax,1 00F0A8C0 mov dword ptr [ebp-54h],eax 00F0A8C3 cmp dword ptr [ebp-54h],5F5E100h 00F0A8CA je main+0C0h (0F0A8E0h) p[i] = k[i]; 00F0A8CC mov eax,dword ptr [ebp-54h] 00F0A8CF mov ecx,dword ptr [p] 00F0A8D2 mov edx,dword ptr [ebp-54h] 00F0A8D5 mov esi,dword ptr [k] 00F0A8D8 mov edx,dword ptr [esi+edx*4] 00F0A8DB mov dword ptr [ecx+eax*4],edx 00F0A8DE jmp main+9Ah (0F0A8BAh)
迭代器方法(B方法):
int *pStart = k, *pEnd = k + size, *pDest = p; 00F0A944 mov eax,dword ptr [k] 00F0A947 mov dword ptr [pStart],eax 00F0A94A mov eax,dword ptr [k] 00F0A94D add eax,17D78400h 00F0A952 mov dword ptr [pEnd],eax 00F0A955 mov eax,dword ptr [p] 00F0A958 mov dword ptr [pDest],eax for (; pStart != pEnd; pDest++, pStart++) 00F0A95B jmp main+14Fh (0F0A96Fh) 00F0A95D mov eax,dword ptr [pDest] 00F0A960 add eax,4 00F0A963 mov dword ptr [pDest],eax 00F0A966 mov ecx,dword ptr [pStart] 00F0A969 add ecx,4 00F0A96C mov dword ptr [pStart],ecx 00F0A96F mov eax,dword ptr [pStart] 00F0A972 cmp eax,dword ptr [pEnd] 00F0A975 je main+163h (0F0A983h) *pDest = *pStart; 00F0A977 mov eax,dword ptr [pDest] 00F0A97A mov ecx,dword ptr [pStart] 00F0A97D mov edx,dword ptr [ecx] 00F0A97F mov dword ptr [eax],edx 00F0A981 jmp main+13Dh (0F0A95Dh)
这两段汇编都有一个共同的特性就是都会有这么一种操作:
A在10-15行中,每次都取[ebp-54h]这个位置的值(也就是i),然后每次都取p和k的指针,然后再取i的值,然后以i的值(eax和edx)定位到数组相应位置[esi + eax*4]和[ecx + edx*4],然后再把[ecx + edx*4]放到[esi + eax*4]中。B在11到24行中,也是差不多的用法,只是他把下标位置改成了指针指向的位置。
分析到这里我们可以发现,这两个方法是在太累赘了,比如A,这么简单的赋值居然要访问存储器5次,大大降低了运行效率。
那么为什么std::copy会那么快呢?我们先来跟踪一下std::copy的源代码:
template<class _InIt, class _OutIt> inline _OutIt _Copy_memmove(_InIt _First, _InIt _Last, _OutIt _Dest) { // implement copy-like function as memmove const char * const _First_ch = reinterpret_cast<const char *>(_First); const char * const _Last_ch = reinterpret_cast<const char *>(_Last); char * const _Dest_ch = reinterpret_cast<char *>(_Dest); const size_t _Count = _Last_ch - _First_ch; _CSTD memmove(_Dest_ch, _First_ch, _Count); return (reinterpret_cast<_OutIt>(_Dest_ch + _Count)); } template<class _InIt, class _OutIt> inline _OutIt _Copy_unchecked1(_InIt _First, _InIt _Last, _OutIt _Dest, _General_ptr_iterator_tag) { // copy [_First, _Last) to [_Dest, ...), arbitrary iterators for (; _First != _Last; ++_Dest, (void)++_First) *_Dest = *_First; return (_Dest); } template<class _InIt, class _OutIt> inline _OutIt _Copy_unchecked1(_InIt _First, _InIt _Last, _OutIt _Dest, _Trivially_copyable_ptr_iterator_tag) { // copy [_First, _Last) to [_Dest, ...), pointers to trivially copyable return (_Copy_memmove(_First, _Last, _Dest)); } template<class _InIt, class _OutIt> inline _OutIt _Copy_unchecked(_InIt _First, _InIt _Last, _OutIt _Dest) { // copy [_First, _Last) to [_Dest, ...) // note: _Copy_unchecked is called directly elsewhere in the STL return (_Copy_unchecked1(_First, _Last, _Dest, _Ptr_copy_cat(_First, _Dest))); } template<class _InIt, class _OutIt> inline _OutIt _Copy_no_deprecate1(_InIt _First, _InIt _Last, _OutIt _Dest, input_iterator_tag, _Any_tag) { // copy [_First, _Last) to [_Dest, ...), arbitrary iterators return (_Rechecked(_Dest, _Copy_unchecked(_First, _Last, _Unchecked_idl0(_Dest)))); } template<class _InIt, class _OutIt> inline _OutIt _Copy_no_deprecate1(_InIt _First, _InIt _Last, _OutIt _Dest, random_access_iterator_tag, random_access_iterator_tag) { // copy [_First, _Last) to [_Dest, ...), random-access iterators _CHECK_RANIT_RANGE(_First, _Last, _Dest); return (_Rechecked(_Dest, _Copy_unchecked(_First, _Last, _Unchecked(_Dest)))); } template<class _InIt, class _OutIt> inline _OutIt _Copy_no_deprecate(_InIt _First, _InIt _Last, _OutIt _Dest) { // copy [_First, _Last) to [_Dest, ...), no _SCL_INSECURE_DEPRECATE_FN warnings _DEBUG_RANGE_PTR(_First, _Last, _Dest); return (_Copy_no_deprecate1(_Unchecked(_First), _Unchecked(_Last), _Dest, _Iter_cat_t<_InIt>(), _Iter_cat_t<_OutIt>())); } template<class _InIt, class _OutIt> inline _OutIt copy(_InIt _First, _InIt _Last, _OutIt _Dest) { // copy [_First, _Last) to [_Dest, ...) _DEPRECATE_UNCHECKED(copy, _Dest); return (_Copy_no_deprecate(_First, _Last, _Dest)); }
我们发现,copy最后要么执行的是_Copy_unchecked1,要么执行的是_Copy_memmove,那究竟执行的是谁呢?我们来看中间函数_Copy_no_deprecate的返回值:
return (_Copy_no_deprecate1(_Unchecked(_First), _Unchecked(_Last), _Dest, _Iter_cat_t<_InIt>(), _Iter_cat_t<_OutIt>()));
这里运用的是C++ 的traits技术,_Iter_cat_t<_InIt>其实是一个模板的别名:
template<class _Iter> using _Iter_cat_t = typename iterator_traits<_Iter>::iterator_category;
iterator_traits可以用来显示一个STL里面广泛运用的用来判别迭代器的属性的东西,它一共有5个属性,其中iterator_category就是说明了这个迭代器是以下哪五种迭代器之一:
input_iterator_tag //输入迭代器,单向一次一步移动,读取一次output_iterator_tag //输出迭代器,单向一次一步移动,涂写一次forward_iterator_tag //向前迭代器,单向一次一步移动,多次读写,继承自输入迭代器bidirectional_iterator_tag //双向迭代器,双向一次一步移动,多次读写,继承自向前迭代器random_access_iterator_tag //随机迭代器,任意位置多次读写,继承自双向迭代器
而在我们的例子里,由于我们是int *类型,所以这个东西的iterator_category是random_access_iterator_tag,所以我们会跳到_Copy_unchecked上,然后执行_Ptr_copy_cat
template<class _Source, class _Dest> inline _General_ptr_iterator_tag _Ptr_copy_cat(const _Source&, const _Dest&) { // return pointer copy optimization category for arbitrary iterators return {}; } template<class _Source, class _Dest> inline conditional_t<is_trivially_assignable<_Dest&, _Source&>::value, typename _Ptr_cat_helper<remove_const_t<_Source>, _Dest>::type, _General_ptr_iterator_tag> _Ptr_copy_cat(_Source * const&, _Dest * const&) { // return pointer copy optimization category for pointers return {}; }
因为我们的_Source和_Dest类型都是指针类型(而不是常量引用),所以会匹配第二个重载版本,然后经过conditional_t的转换,最后会转换成_Trivially_copyable_ptr_iterator_tag(那个转换太长了,大家可以去STL一个一个翻),然后调用_Copy_memmove,然后_Copy_memmove我们一眼就发现了一个很熟悉的东西:
_CSTD memmove(_Dest_ch, _First_ch, _Count);
memcpy与memmove其实差不多,目的都是将N个字节的源内存地址的内容拷贝到目标内存地址中,但是,当源内存和目标内存存在重叠时,memcpy会出现错误,而memmove能正确地实施拷贝,但这也增加了一点点开销。memmove与memcpy不同的处理措施:
当源内存的首地址等于目标内存的首地址时,不进行任何拷贝当源内存的首地址大于目标内存的首地址时,实行正向拷贝当源内存的首地址小于目标内存的首地址时,实行反向拷贝
这下我们就明白了,当我们对动态数组调用std::copy的时候,实际上就是调用的memmove的C标准库,用memmove可以加快复制过程。
memmove机器级实现方式
实际上我们其实可以在http://www.gnu.org/prep/ftp找到其实现代码,但是由于C标准库的代码真的杂乱无章,阅读难度实在是太高,我们能不能有另一种方法去感知memmove的实现方式呢?
首先我们有一个直觉就是,作为一个C标准库,在memmove内部,一定是有用了内联汇编的方式实现,如果直接用C/C++代码去实现,我们很难生成高质量的代码,网上有很多所谓的memmove的实现,其实都只是在C/C++层面上对功能进行了模拟而已,效率肯定是没有汇编高的。
现在我们的问题就是怎么实现汇编级的memmove,一看到这里我们就可以立马反映过来这不就是x86汇编的内容吗?在x86汇编中,我们要实现内存的复制,最常见的指令就是movsb,movsw,movsd(分别移动字节,字,双字)
这三个指令每一次执行都会将源地址到目的地址的数据的复制目标地址由di决定(对于movsb,movsw是di,movsd是edi),每执行一次,根据DF的值+1(DF == 0)或者-1(DF ==1)源地址由si决定(对于movsb,movsw是si,movsd是esi),每执行一次,根据DF的值+1(DF == 0)或者-1(DF ==1)
这三个指令还要配合rep来用,rep是重复指令,当ecx>0时它会一直执行被请求重复的指令。
我们可以在VS上进行内联汇编(x86下,x64还要配置太复杂了)
__asm { mov esi, dword ptr[k]; mov edi, dword ptr[p]; mov ecx, 5F5E100h; rep movsd; };
好吧,其实上面是memcpy。如果要实现memmove,还需要多进行一些判断,就像memmove要求的那样
事实上,我们只要单步调试就可以看到memmove执行的代码了,在VS里面看,的确是进行了汇编优化(注意VS编译器用的memmove的并不是在memmove.c定义的C的版本,而是在memcpy.asm的汇编版本),在我们的例子中,汇编代码如下:
ifdef MEM_MOVE
_MEM_ equ <memmove>
else ; MEM_MOVE
_MEM_ equ <memcpy>
endif ; MEM_MOVE
% public _MEM_
_MEM_ proc
dst:ptr byte,
src:ptr byte,
count:IWORD
; destination pointer
; source pointer
; number of bytes to copy
OPTION PROLOGUE:NONE, EPILOGUE:NONE
push edi ; save edi
push esi ; save esi
; size param/4 prolog byte #reg saved
.FPO ( 0, 3 , $-_MEM_ , 2, 0, 0 )
mov esi,[esp + 010h] ; esi = source
mov ecx,[esp + 014h] ; ecx = number of bytes to move
mov edi,[esp + 0Ch] ; edi = dest
;
; Check for overlapping buffers:
; If (dst <= src) Or (dst >= src + Count) Then
; Do normal (Upwards) Copy
; Else
; Do Downwards Copy to avoid propagation
;
mov eax,ecx ; eax = byte count
mov edx,ecx ; edx = byte count
add eax,esi ; eax = point past source end
cmp edi,esi ; dst <= src ?
jbe short CopyUp ; no overlap: copy toward higher addresses
cmp edi,eax ; dst < (src + count) ?
jb CopyDown ; overlap: copy toward lower addresses
;
; Buffers do not overlap, copy toward higher addresses.
CopyUp:
cmp ecx, 020h
jb CopyUpDwordMov ; size smaller than 32 bytes, use dwords
cmp ecx, 080h
jae CopyUpLargeMov ; if greater than or equal to 128 bytes, use Enhanced fast Strings
bt __isa_enabled, __ISA_AVAILABLE_SSE2
jc XmmCopySmallTest
jmp Dword_align
CopyUpLargeMov:
bt __favor, __FAVOR_ENFSTRG ; check if Enhanced Fast Strings is supported
jnc CopyUpSSE2Check ; if not, check for SSE2 support
rep movsb
mov eax,[esp + 0Ch] ; return original destination pointer
pop esi
pop edi
M_EXIT
因为我们的例子中没有重叠的内存区,而且大小也比128bytes要大,自然就进入了CopyUpLargeMov过程,我们可以很清楚地发现rep movsb了,memmove实现过程就是我们所想的那样。实际上memmove汇编版本还有其他大量的优化,有兴趣的朋友可以点进去memcpy.asm去看一看。
这样感觉很不错,用movsd指令以后我们可以很直观地发现我们已经减少了很多无谓的寄存器赋值操作(movsd指令还有被CPU进行加速的)我们接下来试下效果:
效果很不错,已经可以达到memmove的C标准库效果了。
Reference :