大家好,好久没看到喵了,是不是想我了。
这是本喵看到的一篇好文章,所以忍不住想要拿过来。
知乎上有一种说法是「编译器、图形学、操作系统是程序员的三大浪漫」。
先不管这个说法是对是错,我们假设一个程序员在国内互联网公司写代码,业余时间不看相关书籍。那么三年之后,他的这些知识会比在校时损耗多少?
很显然,损耗的比例肯定非常高,毕竟国内互联网公司日常开发工作中,程序员基本很少接触这三块知识。大部分程序员工作几年后对编译原理相关的概念只能生理上起反应,脑海里很难再串联起相关概念了。
编译原理的概念有让人看到就头痛的特质,学校里要死记硬背,考试过了巴不得赶紧全忘掉,相信不少同学现在看到下面概念还会觉得蛋疼:
-
非确定性有限自动机/确定性有限自动机
-
四元式序列
-
上下文无关文法/BNF
-
终结符/非终结符
-
LL(1)/LR(1)
-
特设语法制导转换
-
局部优化
其实本喵在学习这门课的时候也很烦脑,毕竟这是号称最难学的一门学科之一。本喵是在大四的时候学的这门课,经过半个学期死命的看书,也还是懵懵懂懂,不怎么明白。但好在考试的时候过了。
-
什么是编译器?
广义的编译器可以指任意把一种语言代码转为另一种语言代码的程序
-
做编译器实际上都需要做什么?
编译器是一整套工具链,从前端的词法分析、语法分析,到中间表示生成、检查、分析、优化,再到代码生成。
如果是编译器从业者,大部分时间在做中间这块;如果是业余爱好者,大部分时间在做前端和代码生成。
先确定源语言:
这是一门看起来像lisp的四则运算语言,四个双目运算符分别是「add」「sub」「mul」「div」。
多项四则运算可以这样写:
(mul (sub 5 (add 1 2)) 4
再来确定目标语言:
同样是一门四则运算语言,但是看起来可读性更强,对应的四个双目运算符分别是「+」「-」「*」「/」。
上面源语言的例子编译完后应该是这样:
((5 - (1 + 2)) * 4)
最后确定我们写编译器要用的语言:
喵选择Haskell,有两个原因,一是写Haskell有大名鼎鼎的ParseC,写Parser非常方便;二是Haskell的代数数据类型的定义本身就是AST。
ParseC的全称是Parser组合子。Parser,抽象理解就是一个输入为字符串输出为类型T的值的函数。ParseC库实现了大量基础Parser和Parser组合子,Parser组合子可以将库自带的基础Parser和用户定义的Parser随意组合成新的更强大的Parser。
举个例子,你实现了一个Parser,功能是根据输入文本返回解析到的标识符名称。ParseC库实现了一个名叫many的parser组合子,跟你自己的Parser组合起来就产生了一个新的Parser:可以根据输入文本返回解析到的标识符名称list。
为什么要用ParseC呢?因为用ParseC定义Parser具有PEG(解析表达式文法,原理不细讲,不影响接下来学习)的所有好处,同时还不用再学习语言之外的知识(比如用flex和bison前要先学习这两者自己的「DSL」)。
当然,其他语言也有类似的库,比如c++有boost::spirit,Java/C#/F#/JS有Haskell的ParseC的工业级实现。这些语言跟Haskell的区别无非在于要写一些额外的逻辑把Parser的解析结果转成AST。
如果没有接触过Haskell的话也没关系,接下来的示例代码都非常declarative,非常self-descriptive,请放心食用。
接下来就开始写代码了,首先我们要定义AST的结构,目的是为了能用这个结构描述一切源语言表达式。
简单分析一下源语言,我们可以直接得出表达式这个概念的递归定义:一个表达式要么是一个字面值,要么是一个双目运算符和两个表达式的求值结果。
然后是字面值这个概念的递归定义:一个字面值要么是一个整型值,要么是一个浮点型值。
在Haskell里面这两个定义写成下面这样:

跟前面的文字定义对应一下:
-
表达式Exp,要么是一个字面值表达式ConstExp,由一个Val组成;要么是一个双目运算表达式BinOpExp,由一个操作符和两个Exp组成。
-
值Val,要么是一个整型值IntVal,由一个Integer组成;要么是一个浮点型值FloatVal,由一个Float组成。
接下来开始写Parser。流程是先为AST中的每个节点类型写一个parser,然后再把这些parser组合起来形成能parse出整棵AST的parser。
我们先给自己定个小目标,比如先实现一个int_parser。

p_int是能从文本中Parse出Integer的Parser定义。而p_int_val改造了p_int,定义了能从文本中Parse出IntVal的Parser。
然后我们把int和float的parser组合起来成为一个val_parser。

listplus可以简单理解为并,在具体实现上会做回溯。
同理,我们先分别实现ConstExp的parser和BinOpExp的parser,再把两者组合为exp_parser。
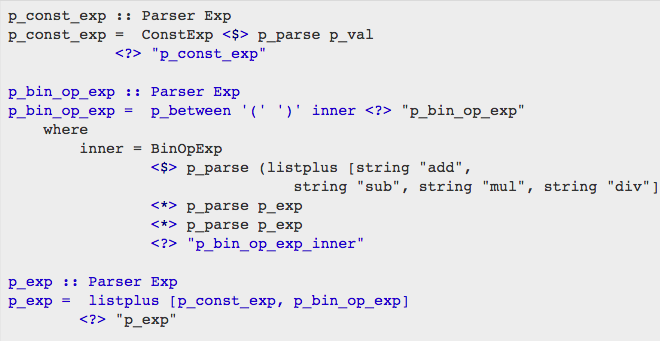
到目前为止,我们的parser部分就完工了。
对Haskell有兴趣的同学,可以安装下ghci,是haskell的REPL,然后加载刚才写好的Parser.hs,在命令行里试一下
可以看到输出结果。稍微排版下,输出结果变成了我们熟悉的树形结构,Op为「mul」的BinOpExp就是树的根节点。整个输出就是一棵AST。

有了这棵AST,我们就可以开始做后续的代码生成了。
CodeGenerator的主体是把Exp转换成目标语言代码的函数:

利用模式匹配这个语言特性实现多态既容易又优雅。
最后再套个壳,比如读源文件,写目标文件,整个编译器就大功告成了
好了,到了和大家说再见的时候了。如果有兴趣可以去:http://mp.weixin.qq.com/s?__biz=MzIwNDU2MTI4NQ==&mid=2247483679&idx=1&sn=8df4b40386fb6182051f4926ab043636#rd这个网址看看。