

每天坚持 一天一篇 点个订阅吧 灰常感谢 当个死粉也阔以
week summer:
Python人工智能从入门到精通
字符串 str # 不可变序列,只能存字符
列表 list # 可变的序列,可以存任意数据
元组 tuple # 不可变序列,可以存任意数据
字典dict # 可变无序,可以存任意数据
集合set #可变无序,只能存不可变数据
(可变就是id不变的情况下改变数据)
序列相关函数: len(x), max(x), min(x), sum(x), any(x), all(x)
序列有5种:
star 字符串
list 列表
tuple 元组
bytes
bytearray
列表 list:
L = [ ]
L = list() 创建函数 括号内放可迭代对象、可以空
L [ ] 括号内放下标
L [:: ] 第一个参数开始位置,第二个结束、第三个步长(步长决定方向)
列表推导式: [表达式 for 变量 in 可迭代对象](可以嵌套)
del L[ ] 删除指定下表索引
列表可以索引下标 、切片 可以增、删、改、查
可以索引赋值、切片赋值(不是顺序切片时赋值一定要个数相等)
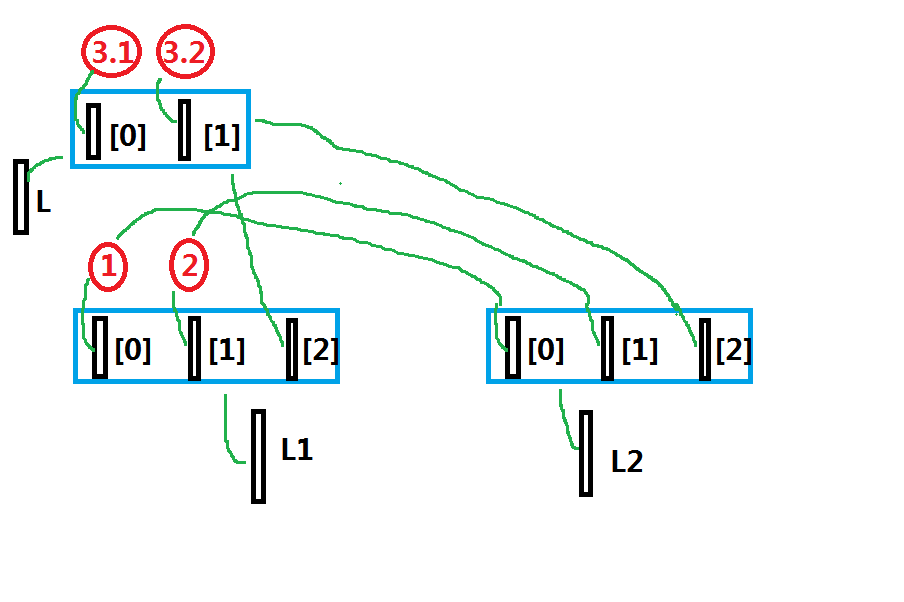
潜拷贝
浅拷贝是指在复制过程中,只复制一层变量,不会复制深层变量绑定的对象的复制过程
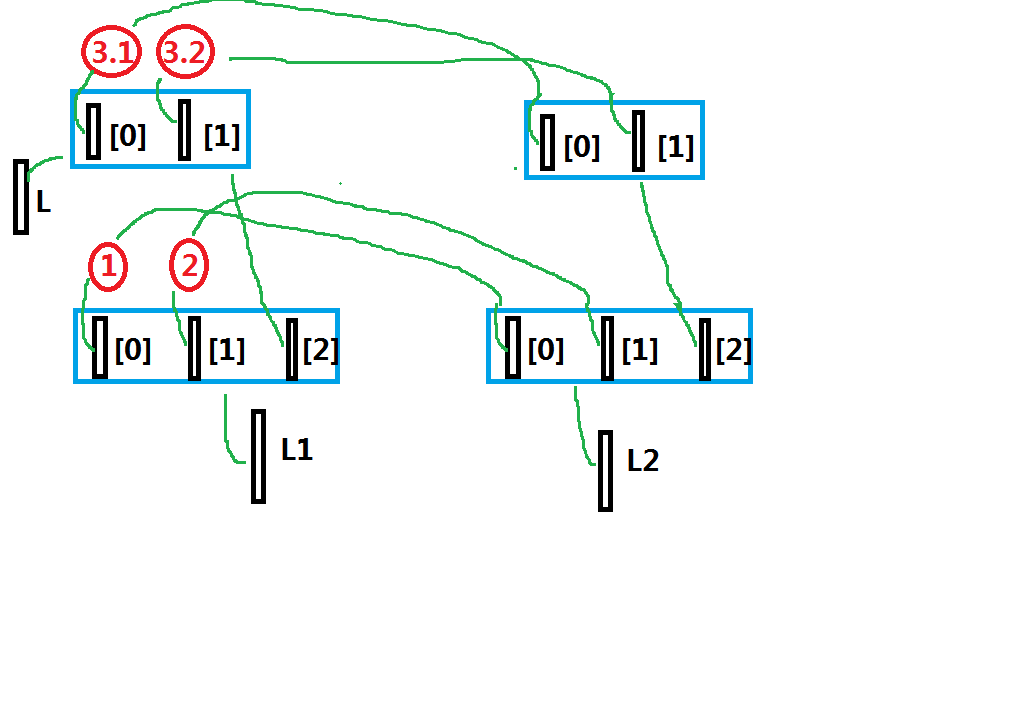
深拷贝
深拷贝通常只对可变对象进行复制,不可变对象通常不会复制
元组 type
t = (1, ) 低于连个元素必须用, 号
t = type(x) 同列表一样
元组可以索引和切片和列表一样 但是但是不能赋值
T.index(v[, begin[, end]]) 返回对应元素的索引下标
T.count(x) 返回元组中对应的元素个数
字典 dict:
d = { }
d = {“a”:1} 键值对形式存在
d[ ] 括号里放键 ,字典索引只索引键(key)
索引赋值 : 只能修改值 ,存在修改 否者添加
dict() 生成一个字的字典 等同于 {}
dict(iterable) 用可迭代对象初始化一个字典
dict(**kwargs) 用关键字传参形式创建一个字典
字典的键(key) 必须为不可变类型 且不能重复
不可变类型:bool, int, float, complex, str, tuple, frozenset, bytes(后面再讲)
in 在什么什么里面 not in 不在什么什么里面(判断键存在:只判断键)
is 是 is not 不是
所有可迭代对象都可以用for 遍历 (字典只访问键)
字典推导式 : d = {x : x ** 2 for x in range(10)}
{键表达式 : 值表达式 for 变量 in 可迭代对象 if 真值表达式}(可嵌套)
字典 VS 列表
1. 都是可变对象
2. 索引方式不同,列表用整数索引,字典用键索引
3. 字典的插入,删除,修改数据的速度可能会快于列表(重要)
4. 列表的存储是有序的,字典的存储是无序的
可变的数据类型有四种:
list 列表、dict 字典
set 集合、bytearray 字节数组
集合 set:
s = set( )
s = set( ) 构造函数
数据不可重复 相当于只有键的字典
集合运算:
& 生成两个集合的交集
| 生成两个集合的并集
- 生成两个集合的补集
^ 生成两个集合的对称补集
> 判断一个集合是另一个集合的超集
< 判断一个集合是另一个集合的子集 (包含关系)
== != 集合相同/不同 (与顺序无关)
集合推导式:{表达式 for 变量 in 可迭代对象 [if 真值表达式]}(可嵌套)
固定集合 frozenset:
固定集合是不可变的,无序的, 含有唯一元素的集合
(可以做字典键也可以做集合的值)
frozenset()
f = frozenset() 括号内放可迭代对象
相当于集合的全部方法(包括运算符)去掉修改集合的方法
常用字符串方法
方法 说明
S.isdigit() 判断字符串中的字符是否全为数字
S.isalpha() 判断字符串是否全为英文字母
S.islower() 判断字符串所有字符是否全为小写英文字母
S.isupper() 判断字符串所有字符是否全为大写英文字母
S.isspace() 判断字符串是否全为空白字符
S.center(width[,fill]) 将原字符串居中,左右默认填充空格 width:所居中字符串的长度 fill:默认填充空格
S.count(sub[, start[,end]]) 获取一个字符串中子串的个数 sub:所要获取的字符串 start:起始位置 end:结束位置
S.find(sub[, start[,end]]) 获取字符串中子串sub的索引,失败返回-1 start:起始位置 end:结束位置
S.strip() 返回去掉左右空白字符的字符串
S.lstrip() 返回去掉左侧空白字符的字符串
S.rstrip() 返回去掉右侧空白字符的字符串
S.upper() 生成将英文转换为大写的字符串
S.lower() 生成将英文转换为小写的字符串
S.replace(old, new[, count]) 将原字符串的old用new代替,生成一个新的字符串 count:更换的次数
S.startswith(prefix[, start[, end]]) 返回S是否是以prefix开头,如果以prefix开头返回True,否则返回False,
S.endswith(suffix[, start[, end]]) 返回S是否是以suffix结尾,如果以suffix结尾返回True,否则返回False
以下是不常用的
S.title() 生成每个英文单词的首字母大写字符串
S.isnumeric() 判断字符串是否全为数字字符
文本解析:
S.split(sep=None) 拆分字符串 sep是拆分符号
S.join(iterable) S是分隔字符串 扩号内跟可迭代对象
列表的方法 :
L.index(v [, begin[, end]]) 返回对应元素的索引下标, begin为开始索引,end为结束索引,当 value 不存在时触发ValueError错误
L.insert(index, obj) 将某个元素插放到列表中指定的位置
L.count(x) 返回列表中元素的个数
L.remove(x) 从列表中删除第一次出现在列表中的值
L.copy() 复制此列表(只复制一层,不会复制深层对象)
L.append(x) 向列表中追加单个元素
L.extend(lst) 向列表追加另一个列表
L.clear() 清空列表,等同于 L[:] = []
L.sort(reverse=False) 将列表中的元素进行排序,默认顺序按值的小到大的顺序排列
L.reverse() 列表的反转,用来改变原列表的先后顺序
L.pop([index]) 删除索引对应的元素,如果不加索引,默认删除最后元素,同时返回删除元素的引用关系
字典的方法
D代表字典对象
D.clear() 清空字典
D.pop(key) 移除键,同时返回此键所对应的值
D.copy() 返回字典D的副本,只复制一层(浅拷贝)
D.update(D2) 将字典 D2 合并到D中,如果键相同,则此键的值取D2的值作为新值
D.get(key, default) 返回键key所对应的值,如果没有此键,则返回default
D.keys() 返回可迭代的 dict_keys 集合对象
D.values() 返回可迭代的 dict_values 值对象
D.items() 返回可迭代的 dict_items 对象
Python3 集合的方法:
方法 意义
S.add(e) 在集合中添加一个新的元素e;如果元素已经存在,则不添加
S.remove(e) 从集合中删除一个元素,如果元素不存在于集合中,则会产生一个KeyError错误
S.discard(e) 从集合S中移除一个元素e,在元素e不存在时什么都不做;
S.clear() 清空集合内的所有元素
S.copy() 将集合进行一次浅拷贝
S.pop() 从集合S中删除一个随机元素;如果此集合为空,则引发KeyError异常
S.update(s2) 用 S与s2得到的全集更新变量S
S.difference(s2) 用S - s2 运算,返回存在于在S中,但不在s2中的所有元素的集合
S.difference_update(s2) 等同于 S = S - s2
S.intersection(s2) 等同于 S & s2
S.intersection_update(s2) 等同于S = S & s2
S.isdisjoint(s2) 如果S与s2交集为空返回True,非空则返回False
S.issubset(s2) 如果S与s2交集为非空返回True,空则返回False
S.issuperset(...) 如果S为s2的子集返回True,否则返回False
S.symmetric_difference(s2) 返回对称补集,等同于 S ^ s2
S.symmetric_difference_update(s2) 用 S 与 s2 的对称补集更新 S
S.union(s2) 生成 S 与 s2的全集
Python运算符优先级
运算符 描述
(), [], {key: value}, {} 元组表达式、列表表达式、字典表达式、集合表达式
x[index], x[index:index],
x(arguments...), x.attribute 索引,切片,函数调用,属性引用
** 指数 (最高优先级)
~, +, - 按位翻转, 正号,负号
*, /, %, // 乘,除,取模和地板除
+, - 加法, 减法
>>, << 右移, 左移运算符
& 位与(AND)
^ 位异或(XOR)
| 位或(OR)
<=, <, >, >=, ==, !=,
is, is not, in, not in 比较,身份测试,成员资格测试
not 布尔非
and 布尔与
or 布尔或
if - else 条件表达式
lambda lambda表达式
数据类型:
数值类型:
int, float, complex, bool
容器:
不可变的容器
str, tuple, frozenset, bytes(字节串)
可变的容器
list, dict, set, bytearray(字节数组)
值:
None, False, True
运算符
算术运算符
+ - * / // % **
比较运算符:
< <= > >= == !=
in / not in
is, is not
布尔运算:
not, and, or
+(正号) -(负号)
& | ^
[] (索引,切片,键索引)
表达式:
1
1 + 2
max(1,2,3) # 函数调用是表达式
x if x > y else y, 条件表达式
三种推导式:
列表,字典,集合推导式(三种)
语句:
表达式语句:
所有的表达式都可以单独写在一行,形成一个语句,例:
print("hello world")
1 + 2
赋值语句:
a = 100
a = b = c = 100
x, y = 100, 200
a[0] = 100
dict['name'] = 'tarena'
del 语句
if 语句
while 语句
for 语句
break 语句
continue语句
pass 语句
内建函数:
len(x), max(x), min(x), sum(x), any(x), all(x)
构造函数(用来创建同类型的数据对象)
bool(x), int(x), float(x), complex(x),
list(x), tuple(x), str(x), dict(x), set(x),
frozenset(x)
abs(x)
round(x)
pow(x, y, z=None)
bin(x), oct(x), hex(x)
chr(x), ord(x)
range(start, stop, step)
input(x), print(x)
>>> help(__builtins__)
函数:
就是把语句块封装起来 形成一个语句块 利用函数变量直接调用语句块的方式
用户自定义级别的函数是为了提高代码的可用性 重用性 以及逻辑清晰 维护方便
(def 函数名(形参列表):冒号)
形参列表可以为空 函数是一个空间,空间内变量不重复就不会冲突
函数调用:
函数名(实参)
return语句 用于返回非None对象语句
函数的参数传递:
传参方式:(2种)
位置传参(包含关系 )
序列传参
关键字传参(包含关系)
字典关键字传参
位置传参:
实参与形参的位置要对应
序列传参:
用 * 将序列拆解 然后位置传参
关键字传参
将字典用“**”拆解后 实参和形参必须按形参名复制
拆解后键名要在形参中存在必须一致
键名必须是字符串且标识符
综合传参:
在能确定形参能唯一匹配到相应实参的情况下 所有传参方式可以任意组合
位置传参(序列传参)一定要在关键字传参(字典关键字传参)的左侧
函数的缺省参数:
缺省参数必须从右至左依次存在的
命名关键字形参:
语法:
def 函数名(*, 命名关键字形参):
语句块
或
ef 函数名(*args, 命名关键字形参):
语句块
(关键字形参 必须用关键字传参)
作用:
收集多余关键字传参
双星号字典传参:
语法:
def 函数名(**字典形参名):
语句块
作用:
强制所有的参数都参数都必须用关键字传参或字典关键字传参
函数的参数说明:
位置形参、星号元组形参、命名关键字形参、双星号字典形参可以混合使用
函数自左到右的顺序为:
1.位置形参
2.星号元组形参
3.命名关键字形参
4.双星号字典形参
全局变量:global variable:
函数外,模块内的变量
全局变量所有函数都可以直接访问
局部变量:local variable:
函数内的变量
调用时才被创建,在函数调用之后销毁
传参的排序规则:
从左到右 1.位置形参 2.星号元组形参 3.命名关键字形参 4.双星号字典形参
函数:
globals()/locals()
globals()返回当前全局作用域内变量的字典
locals() 返回当前局部作用域内变量的字典
函数名是变量 创建时绑定函数
函数的变量名可以序列交换算法
函数可以作为另一个函数的实参
函数可以作为另一个函数返回值
函数可以嵌套
python的4个作用域:
作用域: 英文解释 缩写
局部作用域(函数内) Local(function) L
外部嵌套函数作用域 Enclosing functio loc E
函数定义所在模块(文件)作用域 Global(module) G
python内建模块作用域 Builtin(python) B
包含关系(内建>模块>外部嵌套函数>函数内)
变量名查找规则:
访问变量时,先查找本地变量,然后是包裹此函数外的函数内部的变量
,之后是全局变量,最后是内建变量
L ---> E ---> G ---> B
在默认情况下,变量名赋值会创建或者改变当前作用域的变量
global语句:
声明一个全局变量
nonlocal语句:
外部嵌套函数变量
调用不可修改外部嵌套函数作用域内的变量进行操作
lambda表达式: 创建一个匿名函数对象
lambda[ 参数1, 参数...]: 表达式
函数:
eval () / exec() 函数
eval(srouce,globals=None, locals=None)
把一个字符串srouce
当成一个表达式来执行,返回表达式结果
eval(source, globals=None, local=None) 把一个字符串 srouce 当成一个表达式来执行,返回表达式执行的结果
exec(source, globals=None, locals=None) 把一个字符串source 当成程序来执行
全部划重点 加粗 加长 加大 
 溜了 不吹NB了....
溜了 不吹NB了....