requests
https://www.cnblogs.com/lei0213/p/6957508.html
我是看的上边的网址学习的
目前分不清get跟post的区别!以后再补充,刚开始,先写着为了后边的查询
用这个request方法
import requests response = requests.get("https://www.baidu.com") print(response.content) print(response.content.decode("utf-8")) #response.text返回的是Unicode格式,通常需要转换为utf-8格式,否则就是乱码。response.content是二进制模式,可以下载视频之类的,如果想看的话需要decode成utf-8格式。 不管是通过response.content.decode("utf-8)的方式还是通过response.encoding="utf-8"的方式都可以避免乱码的问题发生
基本GET:
import requests url = 'https://www.baidu.com/' response = requests.get(url) print(response.text)
带参数的GET请求:
如果想查询http://httpbin.org/get页面的具体参数,需要在url里面加上,例如我想看有没有Host=httpbin.org这条数据,url形式应该是http://httpbin.org/get?Host=httpbin.org
下面提交的数据是往这个地址传送data里面的数据。
import requests url = 'http://httpbin.org/get' data = { 'name':'zhangsan', 'age':'25' } response = requests.get(url,params=data) print(response.url) print(response.text)
基本post请求:
通过post把数据提交到url地址,等同于一字典的形式提交form表单里面的数据
import requests url = 'http://httpbin.org/post' data = { 'name':'jack', 'age':'23' } response = requests.post(url,data=data) print(response.text)
结果
{ "args": {}, "data": "", "files": {}, "form": { "age": "23", "name": "jack" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Content-Length": "16", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.13.0" }, "json": null, "origin": "118.144.137.95", "url": "http://httpbin.org/post" }
Json数据:
从下面的数据中我们可以得出,如果结果:
1、requests中response.json()方法等同于json.loads(response.text)方法
import requests import json response = requests.get("http://httpbin.org/get") print(type(response.text)) print(response.json()) print(json.loads(response.text)) print(type(response.json()) #获取二进制数据 在上面提到了response.content,这样获取的数据是二进制数据,同样的这个方法也可以用于下载图片以及 视频资源
添加header
首先说,为什么要加header(头部信息)呢?例如下面,我们试图访问知乎的登录页面(当然大家都你要是不登录知乎,就看不到里面的内容),我们试试不加header信息会报什么错。
import requests url = 'https://www.zhihu.com/' response = requests.get(url) response.encoding = "utf-8" print(response.text)
结果:
提示发生内部服务器错误(也就说你连知乎登录页面的html都下载不下来)。
<html><body><h1>500 Server Error</h1>
An internal server error occured.
</body></html>
如果想访问就必须得加headers信息。
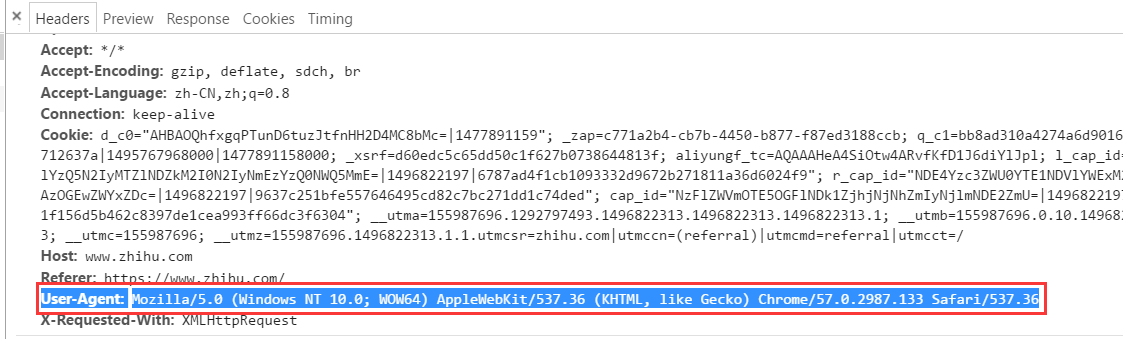
import requests url = 'https://www.zhihu.com/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36' } response = requests.get(url,headers=headers) print(response.text)
响应:
import requests response = requests.get("http://www.baidu.com") #打印请求页面的状态(状态码) print(type(response.status_code),response.status_code) #打印请求网址的headers所有信息 print(type(response.headers),response.headers) #打印请求网址的cookies信息 print(type(response.cookies),response.cookies) #打印请求网址的地址 print(type(response.url),response.url) #打印请求的历史记录(以列表的形式显示) print(type(response.history),response.history)