现在有一个需求,爬取http://www.chinaooc.cn/front/show_index.htm中所有的课程数据。
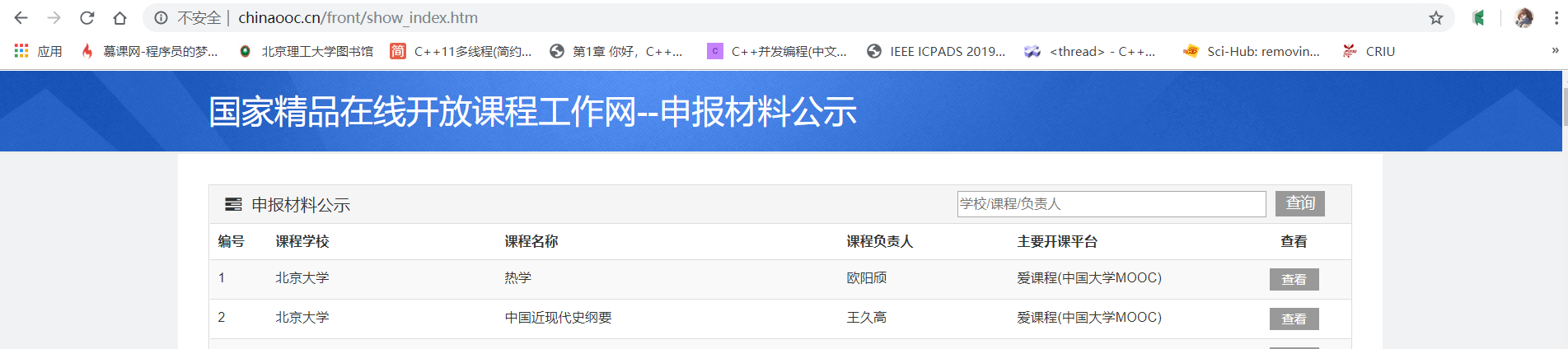
但是,按照常规的爬取方法是不可行的,因为数据是分页的:

最关键的是,不管是第几页,浏览器地址栏都是不变的,所以每次爬虫只能爬取第一页数据。为了获取新数据的信息,点击F12,查看页面源代码,可以发现数据是使用JS动态加载的,而且没有地址,只有一个skipToPage(..)函数。

所以,解决方案是:
- 获得请求信息,包括header和 form data(表单信息)
- 模拟请求,获得数据
- 分析数据,获得结果
以下为实施步骤:
1.获取请求信息,如下图所示,控制台选择Network->XHR,此时,点击页面跳转按钮,控制台会出现发出的请求,然后选择发出请求的文件(第三步),然后选择Headers,下方显示的就是请求头文件信息。
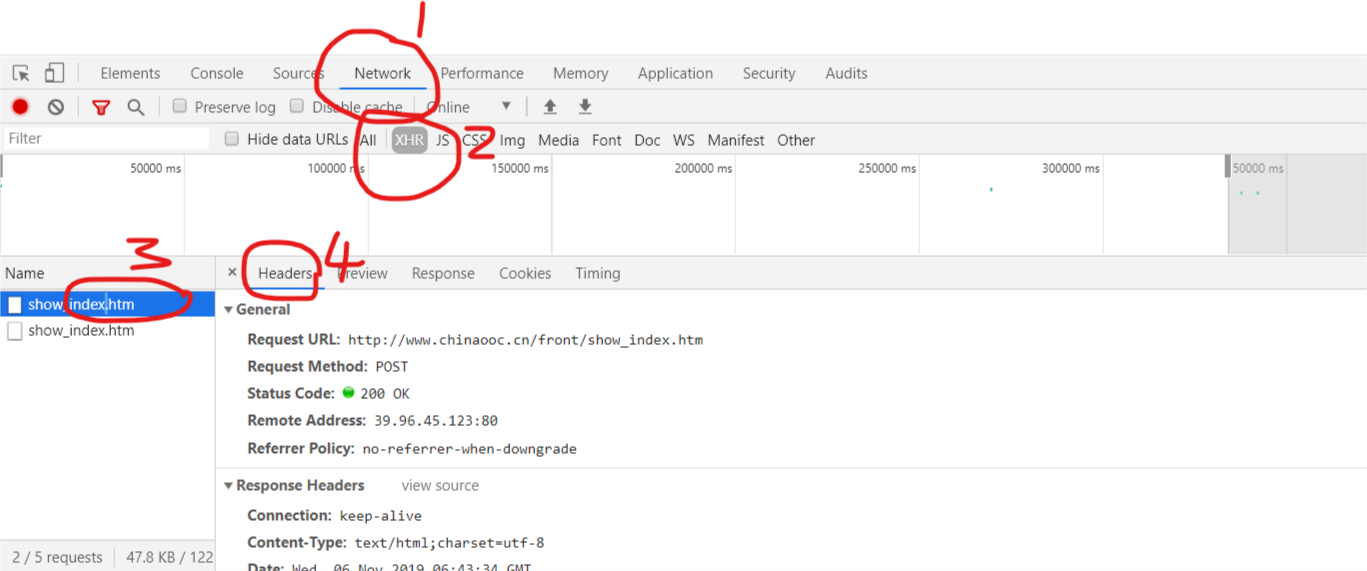
2,使用Python 模拟请求,在Headers下找到 Request Headers 部分,这是请求的头数据。

然后找到Form Data

复制以上内容,形成如下代码
headers = { 'Accept': 'text/html, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,ko;q=0.7', 'Connection': 'keep-alive', 'Content-Length': '61', 'Cookie': 'route=bd118df546101f9fcee5c1a58356a008; JSESSIONID=047BD79E9754BAED525EFE860760393E', 'Host': 'www.chinaooc.cn', 'Origin': 'http://www.chinaooc.cn', 'Pragma': 'no-cache', 'Referer': 'http://www.chinaooc.cn/front/show_index.htm', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest', 'Content-type': 'application/x-www-form-urlencoded; charset=UTF-8' } form_data = { 'pager.pageNumber':'2', 'pager.pageSize': '50', 'pager.keyword': '', 'mode': 'page' }
模拟发送请求,每次改变form_data中的页码就能获得不同的数据,代码如下:
form_data['pager.pageNumber']=times url = 'http://www.chinaooc.cn/front/show_index.htm' response = requests.post(url, data=form_data, headers=headers)
3,分析response中返回的信息即可获得数据。
完整代码如下:
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests import re from bs4 import BeautifulSoup class item: def __init__(self): self.num=0 self.school='' self.clazz='' self.url=''
headers = { 'Accept': 'text/html, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,ko;q=0.7', 'Connection': 'keep-alive', 'Content-Length': '61', 'Cookie': 'route=bd118df546101f9fcee5c1a58356a008; JSESSIONID=047BD79E9754BAED525EFE860760393E', 'Host': 'www.chinaooc.cn', 'Origin': 'http://www.chinaooc.cn', 'Pragma': 'no-cache', 'Referer': 'http://www.chinaooc.cn/front/show_index.htm', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36', 'X-Requested-With': 'XMLHttpRequest', 'Content-type': 'application/x-www-form-urlencoded; charset=UTF-8' } form_data = { 'pager.pageNumber':'2', 'pager.pageSize': '50', 'pager.keyword': '', 'mode': 'page' } times =20 while times < 34: form_data['pager.pageNumber']=times url = 'http://www.chinaooc.cn/front/show_index.htm' response = requests.post(url, data=form_data, headers=headers) soup = BeautifulSoup(response.content, "html.parser") tr_list = soup.find_all('tr') my_tr_list = tr_list[1:-1] for tr in my_tr_list: td_list = tr.find_all('td') a = item() a.num = td_list[0].contents[0] a.school = td_list[1].contents[0] a.clazz = td_list[2].contents[0].replace('"',' ') a.url = td_list[5].find_all('a')[0]["href"] #name = with open('E:/data/'+'['+a.num+']['+a.school+']['+a.clazz+'].html','wb') as f: res = requests.get(a.url) res.encoding = res.apparent_encoding f.write(res.content) times= times+1