20172303 2018-2019-1《程序设计与数据结构》第6周学习总结
教材学习内容总结
在了解了查找和排序后,我们又重新将目光放回数据结构上,本章我们将学习一种非线性数据结构——树。
一、树的概述
1.树的概念
- 概念:树是一种由结点和边组成的,通过结点来存储元素,边来连接结点构成层次结构的非线性数据结构。
- 相关术语:
- 根:位于树的顶层的唯一结点,一棵树只有一个根结点。
- 双亲和孩子:在树的某两层上下结构中,位于较高层的结点是位于较低层结点的双亲,位于较低层的结点是位于较高层结点的孩子。一个结点只有一个双亲,但一个结点可以有多个孩子。
- 兄弟:有同一个双亲的多个结点相互为对方的兄弟。
- 叶子:没有孩子的结点称之为叶子。叶子不一定全部位于最底层。
- 内部结点:一颗树中既不是根结点也不是叶结点的称为内部结点。
- 祖先和子孙:用一个例子来具体说明,根是所有结点的祖先,所有结点都是根的子孙。
- 高度/深度:一颗树的层数。
- 度/阶:一棵树中任一结点所具有的最大孩子数目。

2.树的分类
- 按度来划分
- n元树:树的每个结点的孩子数不超过n个孩子。
- 二叉树:每个结点最多有两个结点的数。
- 按树是否平衡来划分
- 平衡:树的所有叶子之间相差层数不超过一层的树称为稳定的树。含有m个元素的平衡n元树具有的高度为lognm。
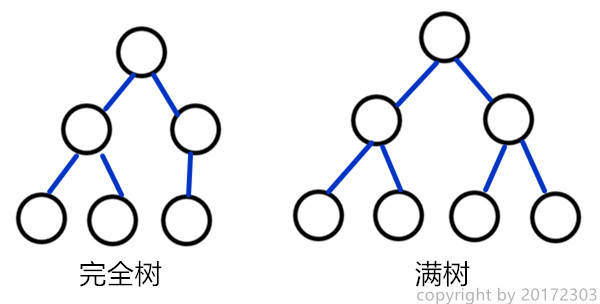
- 完全树:底层叶子都位于树的左边的平衡树称为完全树。
- 满树:在一颗n元树中,所有叶子都位于一层,且除叶子外的每个结点都有n个孩子,则该树被称作满树。
二、树的遍历
- 树的遍历均是从根结点开始的,然后遍历树内所有结点,共有四种方法。
- 前序遍历:从根结点开始,然后从左孩子开始访问每个结点的所有孩子。
public void preorder(ArrayIterator<T> iter){ iter.add(element); if(left != null) left.preorder(iter); if(right != null) right.preorder(iter); }- 中序遍历:先访问根结点的左孩子,然后是根结点,最后是根结点的右孩子。
public void inorder(ArrayIterator<T> iter){ if(left != null) left.inorder(iter); iter.add(element); if(right != null) right.inorder(iter); }- 后序遍历:从左到右遍历所有孩子,最后访问根结点。
public void postorder(ArrayIterator<T> iter){ if(left != null) left.postorder(iter); if(right != null) right.postorder(iter); iter.add(element); }- 层序遍历:从根结点开始,从左至右访问每一层的所有结点。
public void levelorder(TreeNode root) { ArrayDeque<TreeNode> deque=new ArrayDeque<TreeNode>(); deque.add(root);//根节点入队 while(!deque.isEmpty()){ TreeNode temp=deque.remove(); System.out.print(temp.val+"--"); if(temp.left!=null){ deque.add(temp.left); } if(temp.right!=null){ deque.add(temp.right); } } } - 通过下图来看四种遍历方法的不同:

- 前序遍历:A、B、D、E、C
- 中序遍历:D、B、E、A、C
- 后序遍历:D、E、B、C、A
- 层序遍历:A、B、C、D、E
三、二叉树
1.二叉树相关
- 二叉树的基本形态

- (a)为空树
- (b)为仅有一个结点的二叉树
- (c)为仅有左子树而右子树为空的二叉树
- (d)为仅有右子树而左子树为空的二叉树
- (e)为既有左子树又有右子树的二叉树。
- 这里应特别注意的是,二叉树的左子树和右子树是严格区分并且不能随意颠倒的,(c)与(d)就是两棵不同的二叉树。
- 二叉树的性质(假设二叉树的根结点位于第1层)
- (1)二叉树的第i层最多有2^(i-1)个结点。
- (2)深度为k的二叉树最多有2^k-1个结点。
- (3)对任何一颗二叉树,如果其叶子个数为n0,度为2的结点数为n2,则有n0=n2+1。
- (4)具有n个结点的完全二叉树的高度为[log2n]+1
2.实现树的策略
- 数组实现
- 计算策略:存储在数组中位置为n的元素,元素的左子结点存储在(2n+1)的位置,右子结点存储在(2*(n+1))的位置。
- 模拟链接策略:每一个元素都是一个结点类,每一个结点存储其孩子的数组索引,而不是孩子指针的对象引用变量。
- 链表实现
- 设置一个新的
TreeNode类,每一结点都将包含一个指针,它指向将要存储在该结点的元素,以及该结点所有可能孩子的指针。
- 设置一个新的
3.二叉树的操作
- 二叉树ADT

- 在二叉树的操作中,并没有添加和删除元素的操作。因为依据二叉树的用途和结构的不同,添加元素和删除元素的位置也会有所不同。除此之外,尤其是删除操作,会对二叉树结构产生很大的影响,删除的结点为根、内部结点或叶子时其余剩余的元素该如何处理是个很大的问题。
4.二叉树的应用
- 表达式树
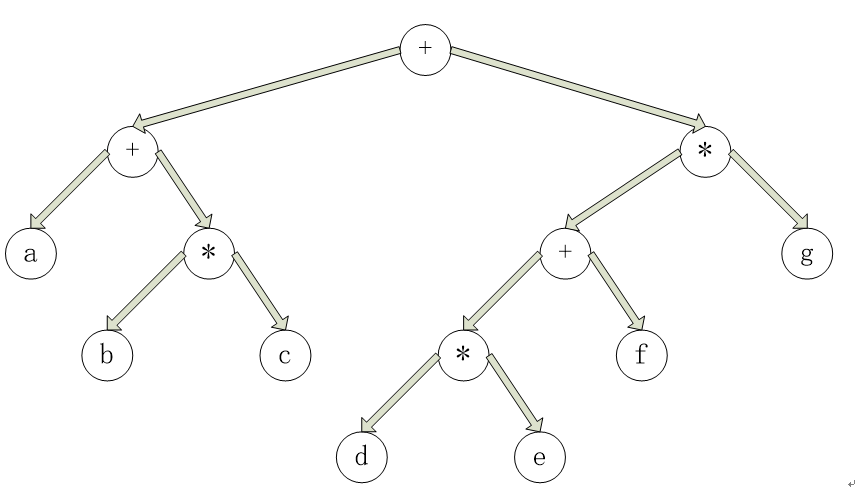
- 原理:表达式树是使用栈来实现的,它实现了将输入的后缀表达式输出成树的形式。每次将操作数压入栈并创建单结点树中,遇到操作符时弹出两个单结点树(元素为操作数)构成一颗二叉树,之后不断反复两种操作(遇到操作数和遇到操作符的两种操作)直至最后栈中只存储了一颗完整的表达式树。
- 此篇博客中有一个图文并茂的非常直观的例子,要比书上的例子好懂得多。
- 决策树

- 原理:决策树的结点用于表示决策点,其子结点表示在该决策点的可选项,叶结点表示决策的结果。使用决策树进行决策的过程就是从根结点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子。二叉树可以用于实现简单决策树(回答只有是和否)
教材学习中的问题和解决过程
- 问题1:在上一篇博客的问题三中我曾经提问说为什么有些方法要先定义一个私有方法,然后再定义一个公用方法来调用私有方法?
- 问题1解决方案:当时我的回答是觉得为了格式一致才设置两个方法,但是在第十章中我找到了正确答案:当某些方法是以递归式编写的时候,它们通常需要使用一个私有支持方法,因为第一个调用和随后每个调用的签名或行为可能是不同的。
- 问题2:决策树中提到的
is-a关系是什么关系? - 问题2解决方法:
is-a(英语:subsumption,包含架构)指的是类的父子继承关系,例如类D是另一个类B的子类(类B是类D的父类)。换句话说,通常"D is-a B"(B把D包含在内,或是D被包含在B内)指的是,概念体D物是概念体B物的特殊化,而概念体B物是概念体D物的一般化。举例来说,水果是苹果、橘子、芒果与其他水果的一般化。
代码调试中的问题和解决过程
- 问题1:在测试背部疼痛诊断器时,总是抛出错误
- 问题1解决方法:依据抛出的错误来看应该是因为数据类型不同,但是不论我怎么修改
toString都无法消除错误。后来发现是由于LinkedBinaryTree中的getLeft()和getRight()方法出现了问题,因为按照书上代码所写的它原本一直返回的是原本设置的right和left而不是实际应该返回的根结点的左孩子或右孩子。
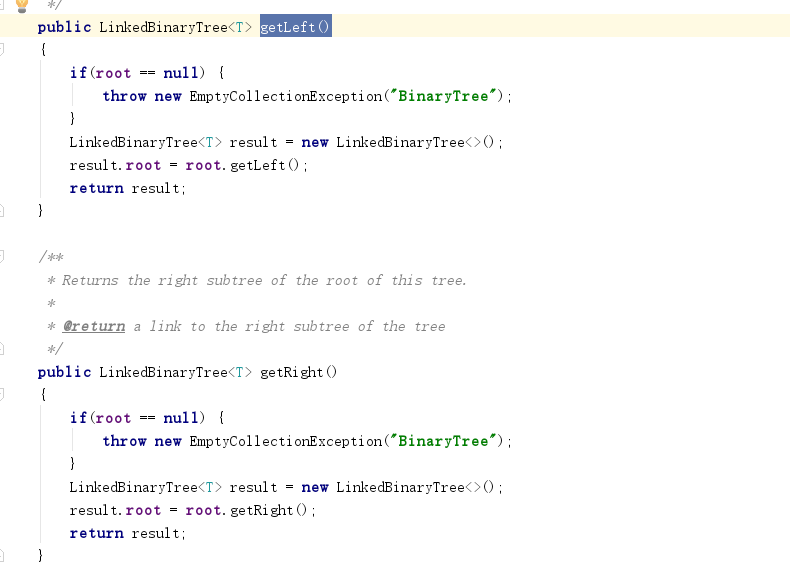
public BinaryTreeNode<T> getLeft()
{
return left;
}
public BinaryTreeNode<T> getRight()
{
return right;
}
- 将
getLeft()和getRight()作出修改即可实现。

- 问题2:在完成PP10.3时,不论选择哪的结点进行判断输出的都是true
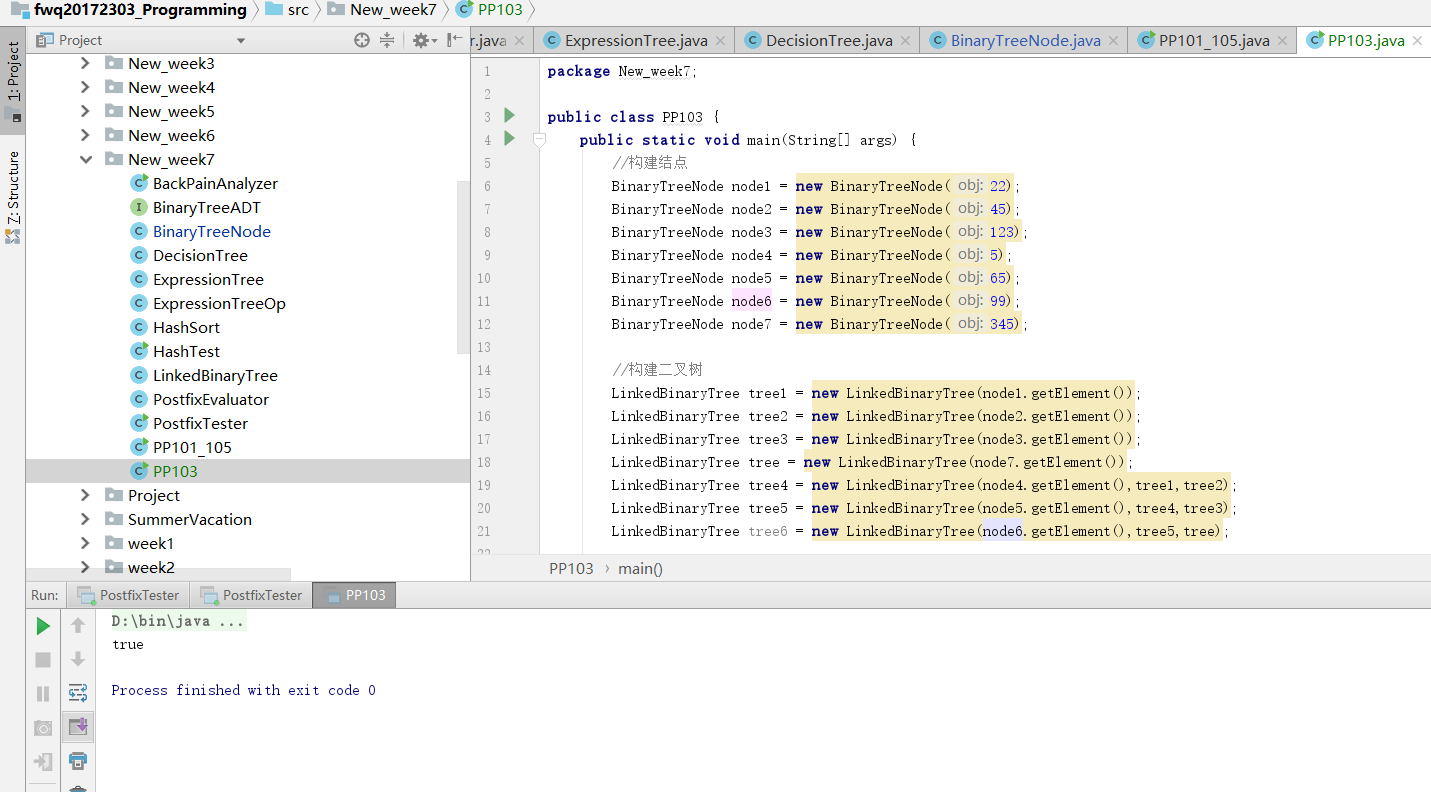
- 问题2解决方法:我原本想的是在
isLeaf的方法中输入所要判断的结点作为参数,但是后来发现这样引用的时候会特别丑。
System.out.println(node1.isLeaf(node1));
- 第一次修改的时候我只是把参数删掉了,此时的代码如下:
public boolean isLeaf(){
if (left == null && right == null){
return true;
}
else {
return false;
}
}
- 结果输出结果依然都为true,原因是
left和right都是开始时设定的结点其内容都为空,想要引用实际想要判断的结点的话要加上this。
public boolean isLeaf(){
if (this.left == null && this.right == null){
return true;
}
else {
return false;
}
}
- 之后就可以了:
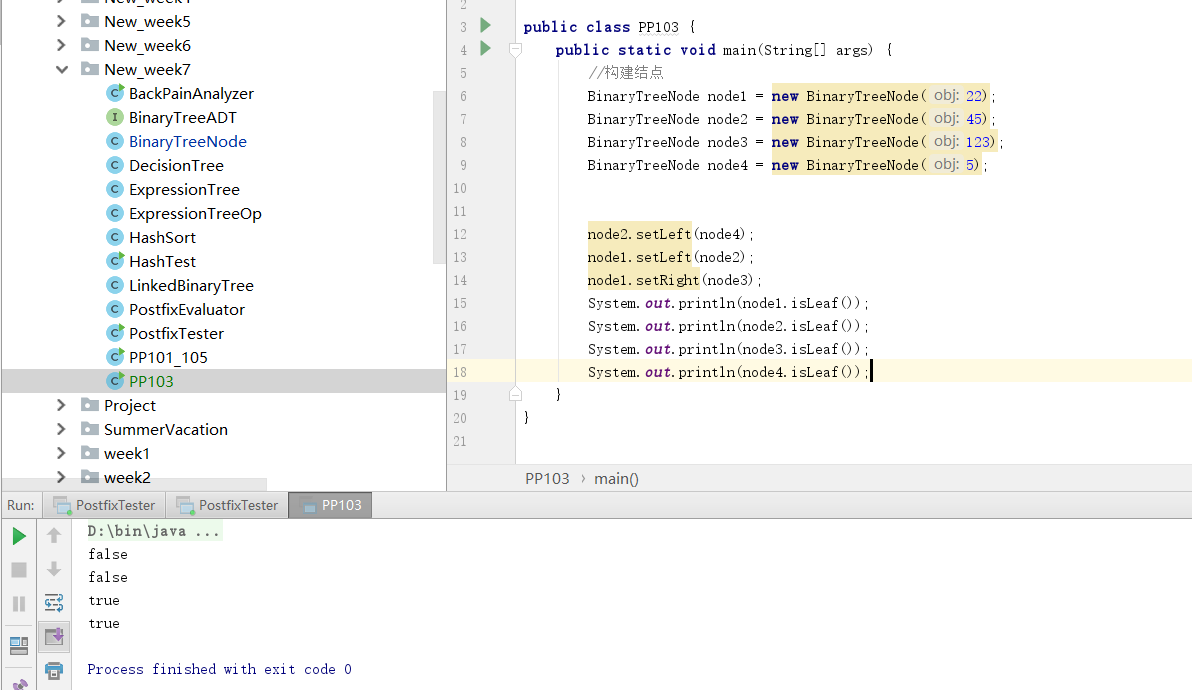
代码托管

上周考试错题总结(正确为绿色,错误为红色)
- 本周没有测试。
结对及互评
点评模板:
- 博客中值得学习的或问题:
- 本周的博客相比上周又增加了很多加粗和变红的标注,可以看出对所学内容有了比以前更加深刻的思考,所以会在博客中突出标记自己在学习过程中发现的重点。
- 代码中值得学习的或问题:
- 本周代码中规中矩,没有什么突出的优点或问题。
点评过的同学博客和代码
- 本周结对学习情况
- 20172322
- 结对学习内容
- 共同讨论了课后的PP项目。
其他(感悟、思考等,可选)
- 相比于之前本章学习的最大感触就是代码不是那么看得很懂了,之前的几章代码都看得很细很透彻,每一步是干什么的基本上都清楚,但是本章不知道是由于代码数量过多还是什么其他的原因,时常看着看着就不知道在干什么了。可能这就是线性数据结构和非线性数据结构的差异吧。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 10/10 | 1/1 | 10/10 | |
| 第二周 | 246/366 | 2/3 | 20/30 | |
| 第三周 | 567/903 | 1/4 | 10/40 | |
| 第四周 | 2346/3294 | 2/6 | 20/60 | |
| 第五周 | 2346/3294 | 2/8 | 30/90 | |
| 第六周 | 1343/4637 | 2/10 | 20/110 |
- 计划学习时间:30小时
- 实际学习时间:20小时
- 改进情况:由于各种原因导致本周的学习时间没有达到预期标准,所以感觉本章学的不是很好,之后要尽快补起来。