20172303 2018-2019-1 《程序设计与数据结构》实验一报告
- 课程:《程序设计与数据结构》
- 班级: 1723
- 姓名: 范雯琪
- 学号:20172303
- 实验教师:王志强
- 助教:张师瑜/张之睿
- 实验日期:2018年9月26日
- 必修/选修: 必修
实验内容
本次实验分为链表练习和数组练习两部分,是对我们从开学到现在学过的数据结构的一个练习及应用。虽然蓝墨云上分了五个节点,但实际上是用链表和数组的方式分别进行以下三个节点的步骤。
节点一
- 通过键盘输入一些整数,建立一个链表。
- 打印所有链表元素, 并输出元素的总数。
- 在程序中,请用一个特殊变量名来纪录元素的总数。
节点二
- 从磁盘读取一个文件,这个文件有两个数字。
- 在实验一的基础上实现节点插入、删除、输出操作:
- 从文件中读入数字1,插入到链表第5位,并打印所有数字和元素的总数。
- 从文件中读入数字2,插入到链表第0位,并打印所有数字和元素的总数。
- 从链表中删除刚才的数字1,并打印所有数字和元素的总数。
节点三
- 使用冒泡排序法或者选择排序法根据数值大小对链表进行排序(学号是单数,选择冒泡排序,否则选择选择排序)
- 在排序的每一个轮次中,打印元素的总数,和目前链表的所有元素。
实验过程及结果
实验一
实验一的要求是完成上述节点一所提到的内容。
1.链表的使用
- 本学期至今我们学过的使用链表实现的有栈和队列两种逻辑结构,由于题目提到的要求是要将输入的元素打印出来,因此要存储输入的元素的顺序,所以应该选择元素处理方式为FIFO(先进先出)的队列。
- 我选择了第五章学习的
LinkedQueue类来实现,主要使用了LinkedQueue类的构造方法、enqueue方法、size()方法和toString()方法。
2.实现将输入的字符串转换成链表
- 这里我使用了两种方法来实现,一种使用了
StringTokenizer类,另一种使用了String类的split方法。 - StringTokenizer类
- 我原本参照着以前的PP3.2中的代码来实现的。
StringTokenizer tokenizer = new StringTokenizer(str); while (tokenizer.hasMoreTokens()){ String transfer = tokenizer.nextToken(); for (int i = 0;i < transfer.length();i++){ queue.enqueue(transfer.charAt(i)); } }- 但是在测试的时候发现它变成了一个数字一个节点,即使我输入空格来进行划分,输出结果也是一样的。
- 在使用了DeBug之后发现是for循环的条件出了问题,同时,因为我之前使用的是
charAt()方法,所以导致了输出之后是一个数字一个节点的问题。
StringTokenizer tokenizer = new StringTokenizer(str); while (tokenizer.hasMoreTokens()){ String transfer = tokenizer.nextToken(); for (int i = 1;i < transfer.length();i++){ queue.enqueue(transfer); } } - split方法
- 这个方法相对来说比较简单,JDK中的介绍是这样的:

- 它其实就是按照指定的正则表达式(这里使用的空格)将输入的内容进行划分并放到一个字符串数组中,之后再通过一个循环将数组转化成链表即可。
String[] transfer = str.split(" "); for (int i = 0; i < transfer.length;i++){ queue.enqueue(transfer[i]); } - 这个方法相对来说比较简单,JDK中的介绍是这样的:
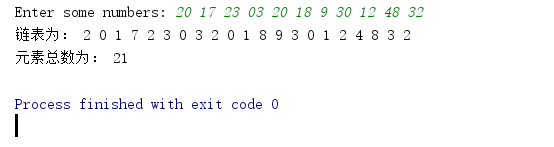
3.测试结果
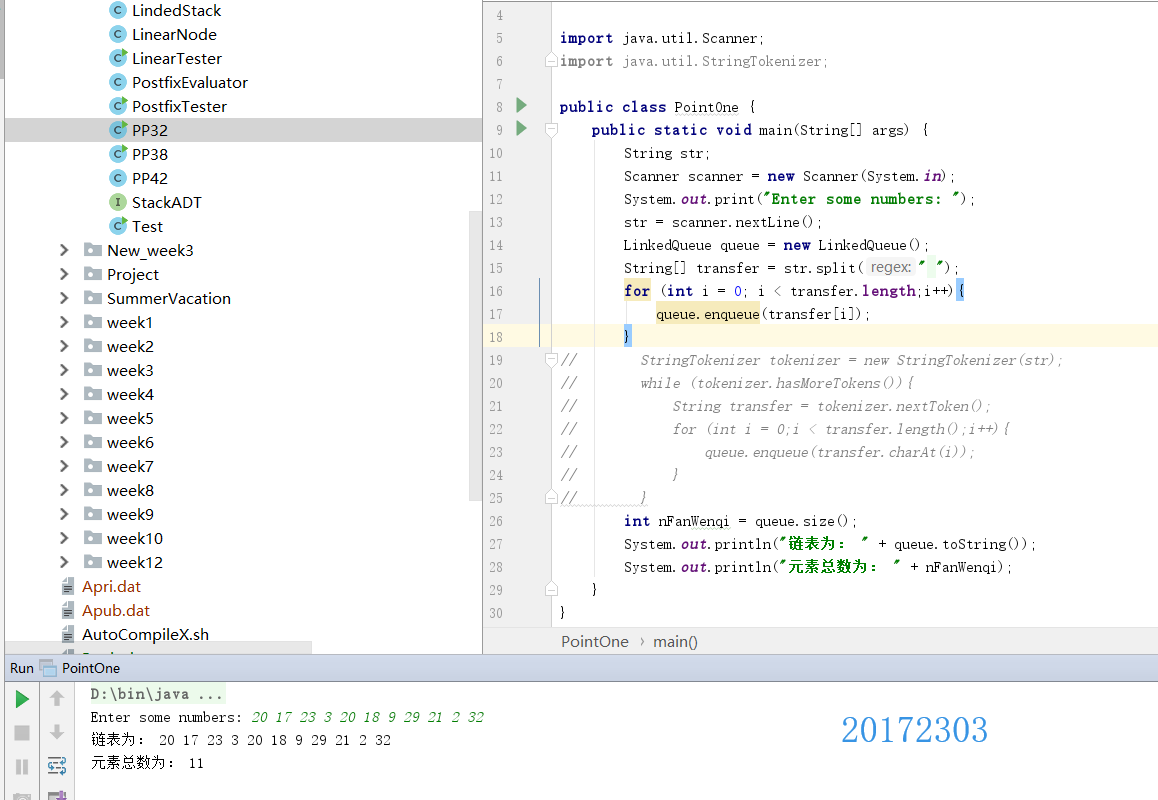
实验二
实验二的要求是完成上述节点二所提到的内容。
1.实现文件的读取
- 文件的读取和写入我们在上个学期已经学习并使用过,这回应该是让我们进行一个复习,此处附上学期学习IO流的记录博客
- 我使用的是字节缓冲流的方式。
//读取文件
BufferedInputStream in = new BufferedInputStream(new FileInputStream("E:\java\point2.txt"));
//一次性取多少字节
byte[] bytes = new byte[2048];
//接受读取的内容(n就代表的相关数据,只不过是数字的形式)
int n = -1;
String a = null;
//循环取出数据
while ((n = in.read(bytes,0,bytes.length)) != -1) {
//转换成字符串
a = new String(bytes,0,n,"GBK");
}
2.实现插入和删除的方法
- 之前在学习链表的时候,老师曾经布置过作业活动让我们来实现链表的插入和删除,这里的实现其实与当初的实现是大同小异的。所以要做的就是修改之前的
LinkedQueue类,在其中加入三个方法即可。 - 在开头插入
public void addFirst(T element){
LinearNode<T> node = new LinearNode<T>((T) element);
if (head == null) {
head = node;
tail = node;
}
else {
node.setNext(head);
head = node;
}
count++;
}
- 在中间插入
public void addMiddle(int index,T element){
LinearNode<T> node = new LinearNode<>(element);
LinearNode<T> current = head;
int j = 0;
while (current != null && j < index - 2){//使指针指向index-1的位置
current = current.getNext();
j ++;
}
node.setNext(current.getNext());
current.setNext(node);
count++;
}
- 删除
public void Delete(int index){
LinearNode<T> current = head;
LinearNode<T> temp = head;
if (index == 0){
head = head.getNext();
}
else {
for (int i = 0;i < index - 1;i++){
temp = current;
current = current.getNext();
}
temp.setNext(current.getNext());
}
count--;
}
3.测试结果
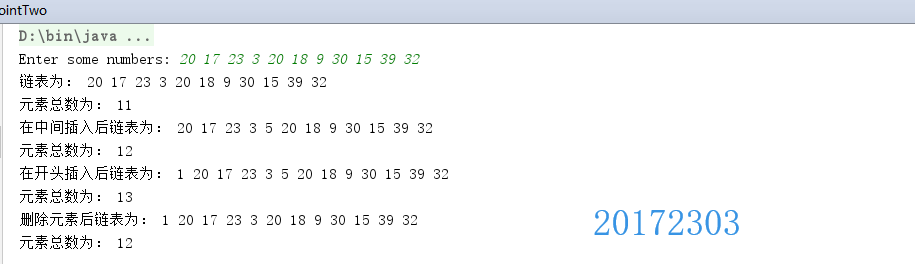
实验三
实验三的要求是完成上述节点三所提到的内容。
1.冒泡排序
- 原理:比较两个相邻的元素,将值大的元素交换至右端。
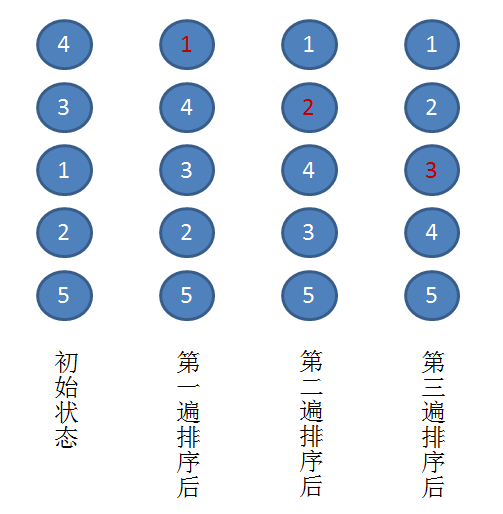
- 优点:每进行一趟排序,就会少比较一次,因为每进行一趟排序都会找出一个较大值。
- 时间复杂度:如果这个排序本来就是正序的,那么冒泡排序的时间复杂度就是O(n),但是显然在显示生活中这种情况是很少见的。如果很不幸我们的数据是反序的,则需要进行n-1趟排序。每趟排序要进行n-i次比较(1≤i≤n-1),且每次比较都必须移动记录三次来达到交换记录位置。在这种情况下,比较和移动次数均达到最大值:
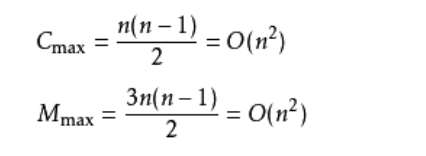
- 所以冒泡排序的最坏时间复杂度为O(n^2)。
- 因此,冒泡排序的平均时间复杂度为O(n^2),其实就是说:当数据越接近正序时,冒泡排序性能越好。
public void Sort(){
LinearNode<T> node = head,current = null;
if (head == null || head.getNext() == null){
return;
}
while (node.getNext() != current){
while (node.getNext() != current){
if (Integer.parseInt(String.valueOf(node.getElement())) > (Integer.parseInt(String.valueOf(node.getNext().getElement())))){
T temp = node.getElement();
node.setElement(node.getNext().getElement());
node.getNext().setElement(temp);
}
node = node.getNext();
}
current = node;
node = head;
LinearNode<T> temp = head;
String str = "";
int i = 0;
while (temp != null){
str += temp.getElement() + " ";
temp = temp.getNext();
i++;
}
System.out.println(str);
System.out.println("元素总数为: " + count);
}
return;
}
2.测试结果

实验四
实验四的要求是完成上述节点一和节点二所提到的内容。
1.数组的使用
- 因为书上所给出的用数组实现的队列是一个循环队列,放在这里不是很好用,所以我又重新写了一个
ArrayQueue类来完成接下来的实验,因为时间关系我只写了实验中要使用的方法,而一些Queue常规的方法比如dequeue并没有实现。 - 和实验一一样,要使用了
LinkedQueue类的构造方法、enqueue方法、size()方法和toString()方法,在编写这些方法中一些其他必要的方法比如isEmpty()、expandCapacity()等也都进行了实现。 - 由于
ArrayQueue类中的方法很多,此处就不再一一列出,放出码云链接。
2.实现插入和删除的功能
- 其他步骤与实验一、实验二相同,在此就不再赘述。
- 插入
- 数组的插入相比链表的插入要简单一些,因为不需要考虑插入元素所在的位置,因为数组的存储地址都是连续的,因此不害怕会存在像链表一样丢失某个节点的情况。
public void insert(int index,int element){ if (index != 0){ int i; for (i = count + 1; i >= index - 1; i--){ queue[i] = queue[i - 1]; } queue[i + 1] = element; } else { for (int i = count + 1;i > 0;i--){ queue[i] = queue[i - 1]; } queue[0] = element; } count++; } - 删除
- 数组的删除操作更为简单,只要将数组后一个的值赋给要删除的位置即可。
public void delete(int index){ for (int i = index;i < count;i++){ queue[i] = queue[i + 1]; } count--; }
3.测试结果

实验五
1.插入排序
- 插入排序是上学期学过的两种排序之一,当初课本上实现插入排序也是通过数组实现的,所以这里插入排序的实现也比较简单。
public void Sort(){
for (int i = 0;i < count;i++){
int k = i;
//找出最小值
for (int j = i + 1;j < count;j++){
if (queue[k] > queue[j]){
k = j;
}
}
//进行排序
if (k > i){
int temp = queue[i];
queue[i] = queue[k];
queue[k] = temp;
}
int b = i + 1;
System.out.println("第" + b + "次排序后的数组为: ");
for (int a = 0;a < count;a++){
String str = "";
str += queue[a] + " ";
System.out.print(str);
}
System.out.println();
System.out.println("元素总数为: " + count);
}
}
2.测试结果


实验过程中遇到的问题和解决过程
- 问题1:
split和StringTokenizer都能实现截取字符串的功能,那么在实际情况中应该如何选择呢? - 问题1解决方法:查找了很多资料发现都说
StringTokenizer要比split性能好.
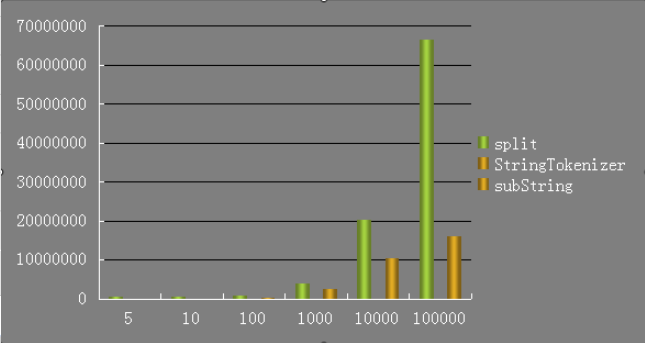
- 大家在对比时都是将
subString、split和StringTokenizer三者进行比较的,可能因为不同的人测试的方法不同,有时候subString比split效率高但是有时候split又更胜一筹,但是StringTokenizer肯定都是耗费时间最短的。不过当要截取的字符串不是很长时三者可以随意使用,因为大多数人在实验时使用的单位都是纳秒,其实差别不是很大。我找到一篇我认为讲解最详细的一篇博客:StringTokenizer、split、substring对比。 - 问题2:在实现冒泡排序时,输出错误

- 问题2解决方法:经过了特别多次DeBug之后终于发现,我设置的临时节点
temp的值会随着node的值的变化而变化。于是我修改了代码,不再设置一个节点而是设置一个泛型T来储存原本node的值。 - 注释内的是原来的错误代码。

其他(感悟、思考等)
- 这回的实验感觉难点主要还是集中在链表,其次是排序问题。问了很多同学发现大家都是实验一、实验二和实验四早早就做出来了,就是实验三和实验五比较难做。不过这回实验还是做得很开心的,因为让我复习到了很多以前的知识,突然就意识到了做课程总结的好处,这样我每次回去翻博客的时候总是能很快翻到。
- 不过在放假前一天在912花9个小时来做实验这种体验真的不希望再有第二回了。
