20172303 2018-2019-1 《程序设计与数据结构》实验三报告
- 课程:《程序设计与数据结构》
- 班级: 1723
- 姓名: 范雯琪
- 学号:20172303
- 实验教师:王志强
- 助教:张师瑜/张之睿
- 实验日期:2018年11月19日
- 必修/选修: 必修
实验内容
节点一
- 定义一个
Searching和Sorting类,并在类中实现LinearSearch(教材P162),SelectionSort方法(P169),最后完成测试。
- 要求不少于10个测试用例,提交测试用例设计情况(正常,异常,边界,正序,逆序),用例数据中要包含自己学号的后四位
提交运行结果图。
节点二
- 重构你的代码,把
Sorting.java Searching.java放入cn.edu.besti.cs1723.(姓名首字母+四位学号)包中(例如:cn.edu.besti.cs1723.G2301)
- 把测试代码放test包中,重新编译,运行代码,提交编译,运行的截图(IDEA,命令行两种)
节点三
- 参考七大查找算法在Searching中补充查找算法并测试,提交运行结果截图。
节点四
- 补充实现课上讲过的排序方法:希尔排序,堆排序,二叉树排序等(至少3个)
- 测试实现的算法(正常,异常,边界)
- 提交运行结果截图
- (3分,如果编写多个排序算法,即使其中三个排序程序有瑕疵,也可以酌情得满分)
节点五(选做)
- 编写Android程序对各种查找与排序算法进行测试。
- 提交运行结果截图。
- 推送代码到码云。
实验过程及结果
节点一
Searching类——LinearSearch
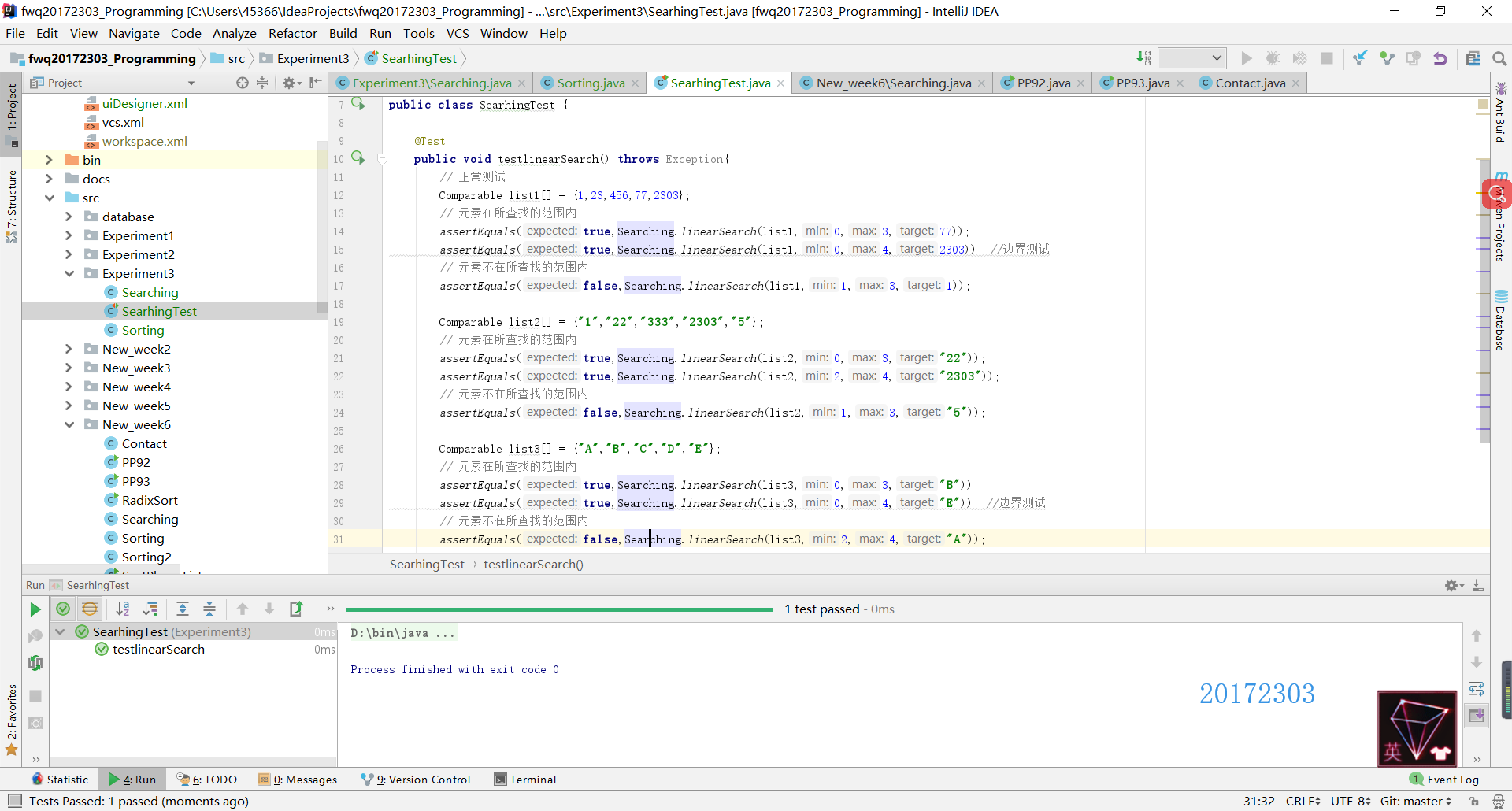
- 概念:在一个元素类型相同的项目组中,从头开始依次比较每一个值直至结尾,若找到指定元素返回索引值,否则返回false。
- 此处LinearSearch方法的实现用的是教材162页的方法,回去翻博客20172303 2018-2019-1《程序设计与数据结构》第5周学习总结发现当时没有进行代码分析,在这里补上。
- 代码分析:课本上实现的linearSearch方法要求用户输入所查找的数组、数组中的最小索引值(通常为0)、最大索引值和所要查找的元素。初始时设定一个boolean值为false,使用一个while循环对数组从头至尾进行遍历,将数组中的每一个元素与目标查找元素
target进行比较,当比较的结果为true时,将true赋值给found输出,否则返回false。
public static <T> boolean linearSearch(T[] data, int min, int max, T target)
{
int index = min;
boolean found = false;
while (!found && index <= max)
{
found = data[index].equals(target);
index++;
}
return found;
}
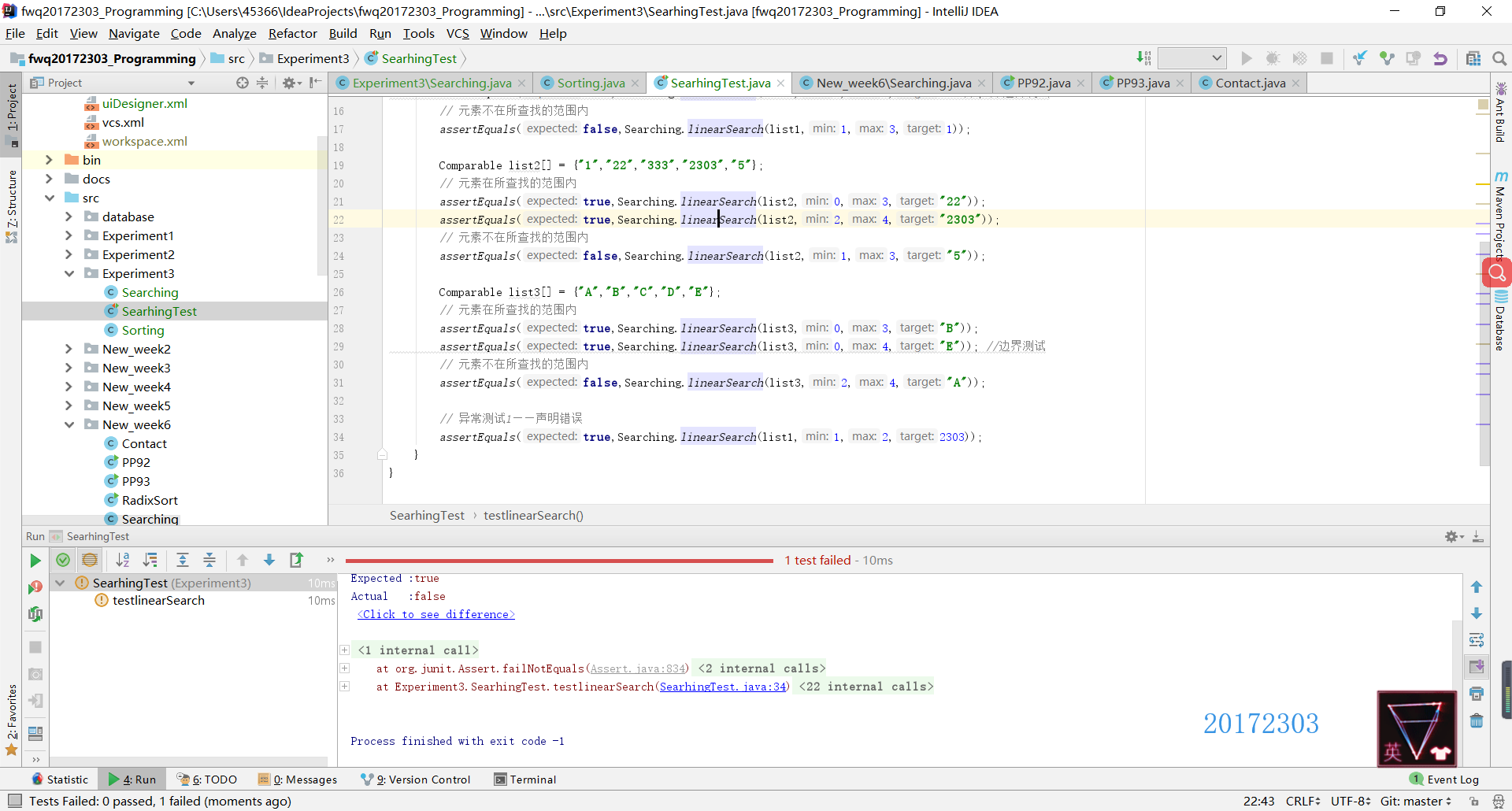
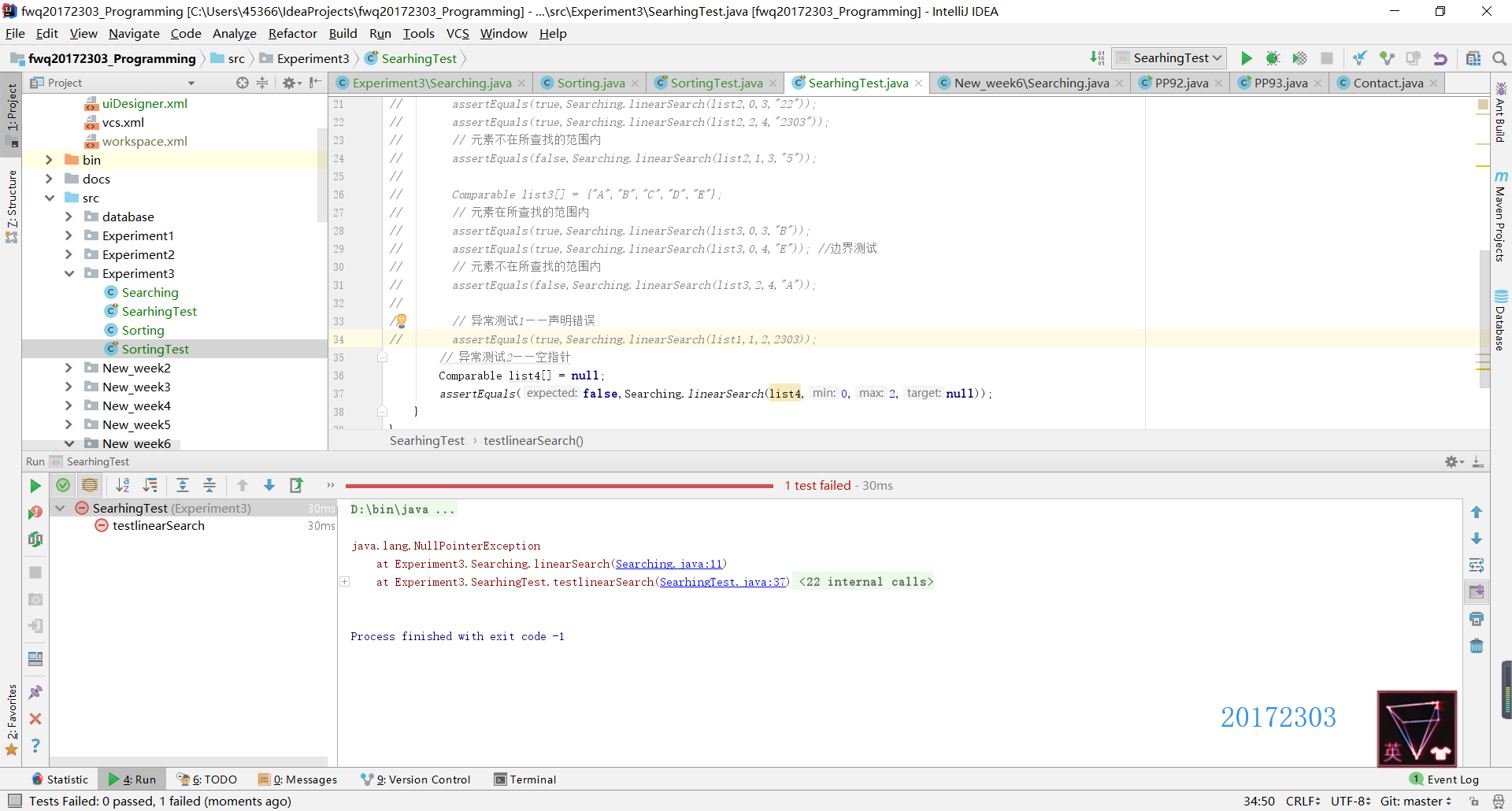
- JUnit测试:在正常测试中,我使用了int和String两种数据类型共测试了四组,其中每一组都测试了两种情况:元素在查找的范围内(包括正常情况和边界情况)和元素不在所查找的范围内。在异常测试中,测试了两种异常错误,一是声明异常(即应该输入的信息和实际输入的信息不符),二是空指针异常(即NullPointerException错误)
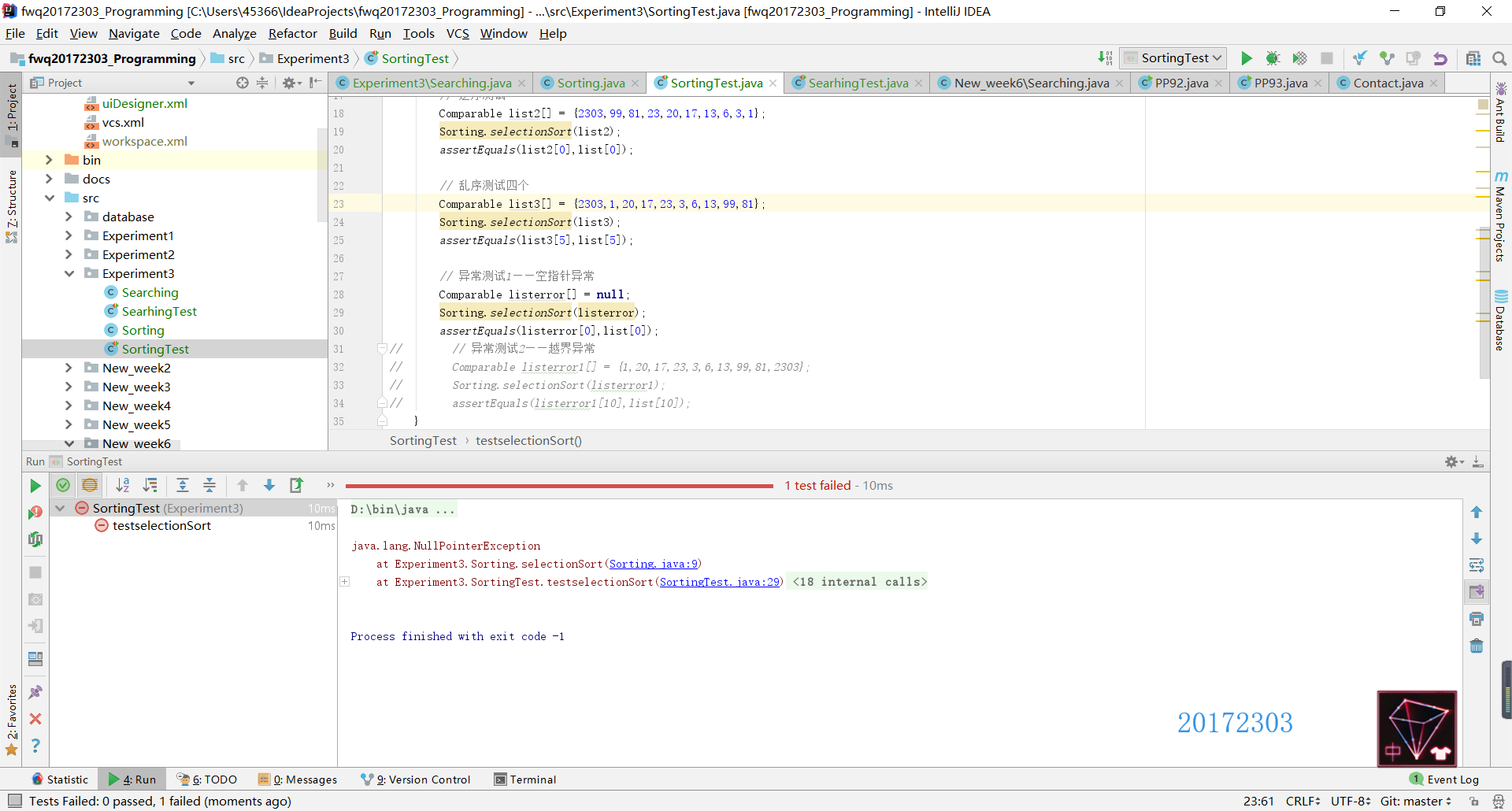
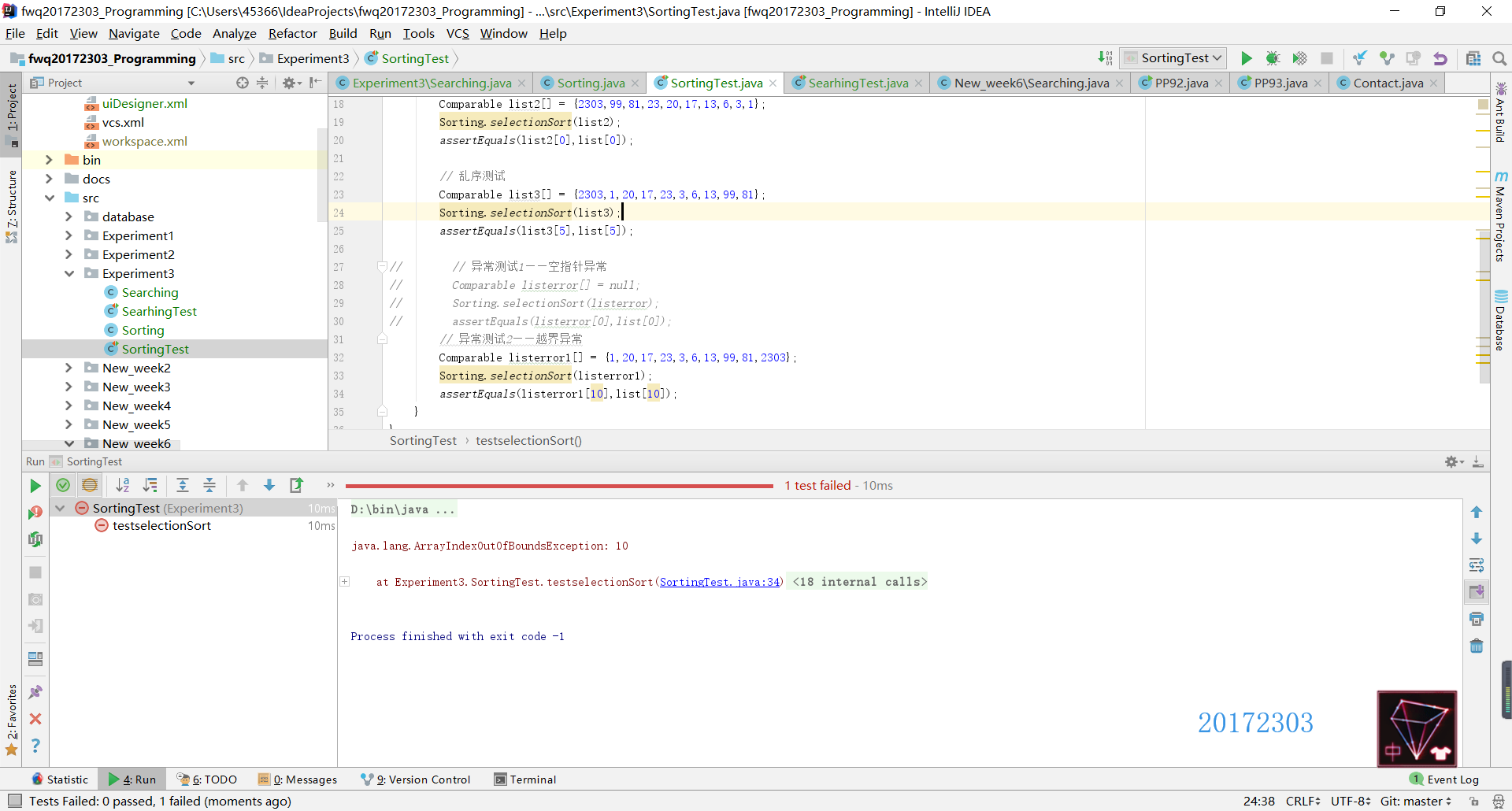
Sorting类——SelectionSort
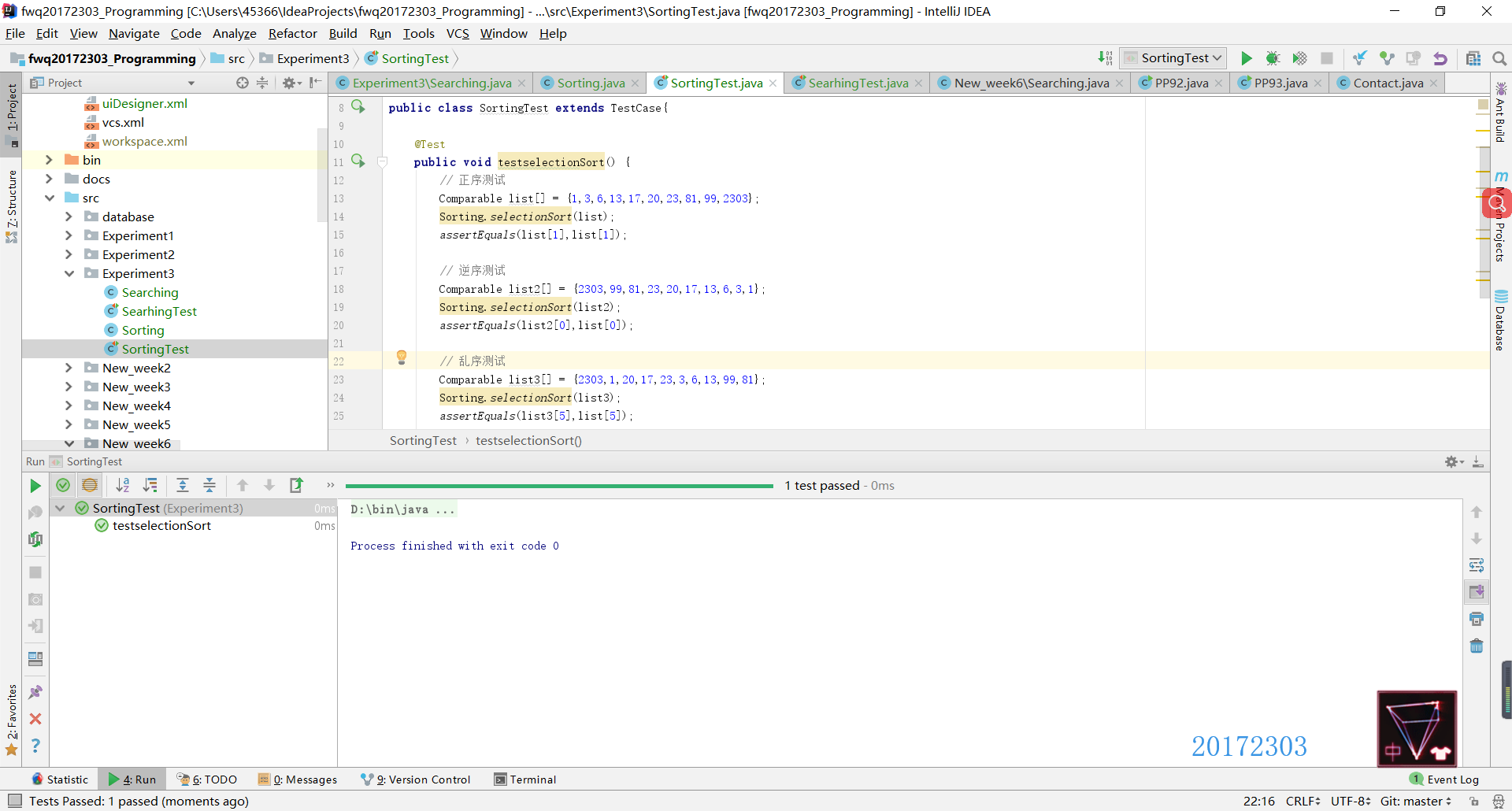
- SelectionSort方法的正常测试中有三种:正序测试、逆序测试和乱序测试。在异常测试中也测试了两种错误,一是空指针异常(即NullPointerException错误),二是越界异常(即查找的数组索引值超出实际数组的索引值范围)
节点二
在IDEA中重构
- 在IDEA中重构比较简单,只要重新按命名要求建一个包,然后将相应的文件复制粘贴到新的包中再运行即可。
- Searching类测试
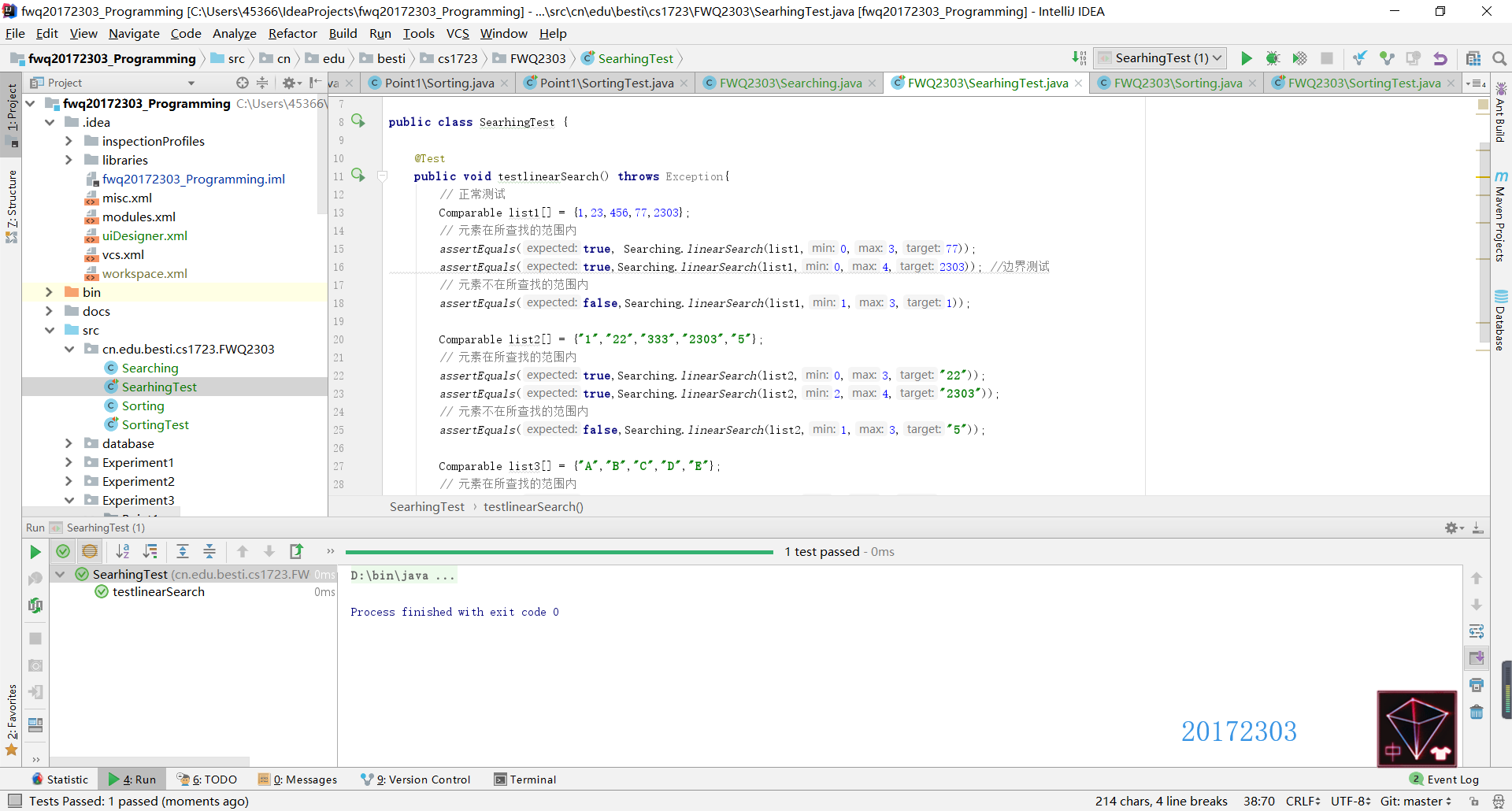
- Sorting类测试
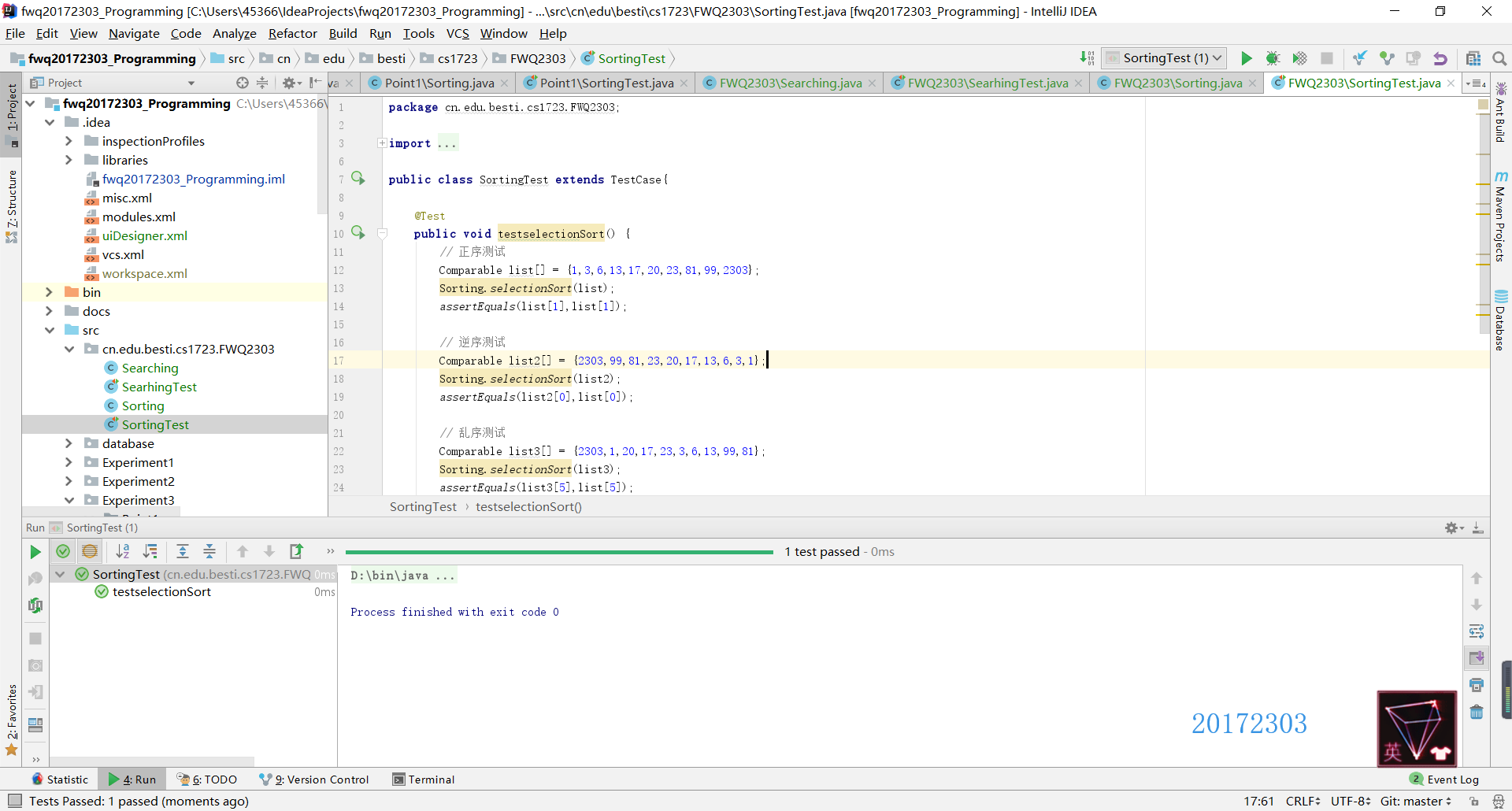
在命令行在重构
- 在命令行中重构的重点是要熟悉Linux命令行和vi编辑器命令行,经过将近一年基本都忘的差不多了,再次复习一下一些本次实验中用到的命令行:
- Linux
| 命令 |
用途 |
| cd |
切换目录,其中cd.或cd~是回到上一级目录,cd..是返回根目录 |
| ls |
列出文件夹内容 |
| mkdir |
创建目录 |
| mv file1 file2 |
移动file1到file2 |
| rm |
删除文件 |
| man command |
查看命令的参考手册 |
| vi file.java |
创建名为file的java文件 |
| javac file.java |
创建名为file的class文件 |
| java file |
运行java文件 |
| 操作 |
用途 |
| i |
进入插入模式 |
| wq |
保存并退出 |
| q |
强制退出 |
- 只要掌握命令行在Linux中重构就也很简单了,因为在Linux中使用JUnit的话还需要下载,这里我就直接用测试类来进行测试了。
- Searching类测试

- Sorting类测试

节点三
- 在题目给出的博客中我选择了三种查找方法:二分查找、插值查找、斐波那契查找。
二分查找
- 概念:也称折半查找,在一个已排序的项目组中,从列表的中间开始查找,如果中间元素不是要找的指定元素,则削减一半查找池,从剩余一半的查找池(可行候选项)中继续以与之前相同的方式进行查找,多次循环直至找到目标元素或确定目标元素不在查找池中。
- 其实这个查找方法在书上也有给出相应的方法,博客中的方法与书上的方法的不同之处在于书上的方法使用的是递归,而博客中的方法使用的是循环,其余的原理等方面都是一样的。
// 二分查找(书上的方法)
public static <T extends Comparable<T>> boolean binarySearch(T[] data, int min, int max, T target)
{
boolean found = false;
int midpoint = (min + max) / 2; // determine the midpoint
if (data[midpoint].compareTo(target) == 0) {
found = true;
} else if (data[midpoint].compareTo(target) > 0)
{
if (min <= midpoint - 1) {
found = binarySearch(data, min, midpoint - 1, target);
}
}
else if (midpoint + 1 <= max) {
found = binarySearch(data, midpoint + 1, max, target);
}
return found;
}
// 二分查找(博客中的方法)
public static Comparable binarySearch(Comparable[] data, Comparable target) {
Comparable result = null;
int first = 0, last = data.length - 1, mid;
while (result == null && first <= last) {
mid = (first + last) / 2;
if (data[mid].compareTo(target) == 0) {
result = data[mid];
} else if (data[mid].compareTo(target) > 0) {
last = mid - 1;
} else {
first = mid + 1;
}
}
return result;
}
插值查找
- 概念:插值查找的算法与二分查找类似,它基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。
- 二分查找:mid = low + 1/2 * (high - low)
- 插值查找:mid = low + (key - a[low])/(a[high] - a[low])* (high - low)
- 对于查找元素较多,且关键字分布较均匀时,使用插值查找将比二分查找的效率快很多。插值查找的时间复杂度为O(logn)。
// 插值查找
public static int InsertionSearch(int[] a, int value, int low, int high) {
int mid = low + (value - a[low]) / (a[high] - a[low]) * (high - low);
if (a[mid] == value) {
return mid;
}
if (a[mid] > value) {
return InsertionSearch(a, value, low, mid - 1);
} else {
return InsertionSearch(a, value, mid + 1, high);
}
}
斐波那契查找
- 想要弄清斐波那契查找,首先先要搞清楚斐波那契数列。
- 斐波那契数列:又称黄金分割数列,指的是这样一个数列:0、1、1、2、3、5、8、13、21、34.....在数学上,斐波纳契数列以如下被以递归的方法定义:F(0)=0,F(1)=1,F(n)=F(n-1)+F(n-2)(n≥2,n∈N*)
- 斐波那契查找:斐波那契查找同样是基于二分查找实现的,只不过它是根据斐波那契数列的特点对数组进行划分,将key值与temp[mid](mid = low + Fibonacci(k - 1) - 1)进行比较,分为三种情况:当key=temp[mid]时,mid即为查找元素在数组中的索引值;当key>temp[mid]时,在temp数组的左边继续进行查找;当key<temp[mid]时,在temp数组的右边继续进行查找。
// 斐波那契查找
// 使用递归建立斐波那契数列
public static int Fibonacci(int n) {
if(n == 0) {
return 0;
}
if(n == 1) {
return 1;
}
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
public static int FibonacciSearch(int[] data,int n,int key) {
int low = 1;
int high = n;
int mid;
// 寻找k值,k值要求k值能使得F[k]-1恰好大于或等于n
int k = 0;
while(n > Fibonacci(k) - 1)
{
k++;
}
//因为无法直接对原数组增加长度,所以定义一个新的数组
//采用System.arraycopy()进行数组间的赋值
int[] temp = new int[Fibonacci(k)];
System.arraycopy(data, 0, temp, 0, data.length);
//对数组中新增的位置进行赋值
for(int i = n + 1;i <= Fibonacci(k) - 1;i++)
{
temp[i]=temp[n];
}
while(low <= high) {
mid = low + Fibonacci(k - 1) - 1;
// 在temp的左边进行查找
if(temp[mid] > key) {
high = mid - 1;
k = k - 1;
}
// 在temp的右边进行查找
else if(temp[mid] < key) {
low = mid + 1;
k = k - 2;
}else {
if(mid <= n) {
return mid;
}
//当mid位于新增的数组中时,返回n
else {
return n;
}
}
}
return 0;
}
测试结果
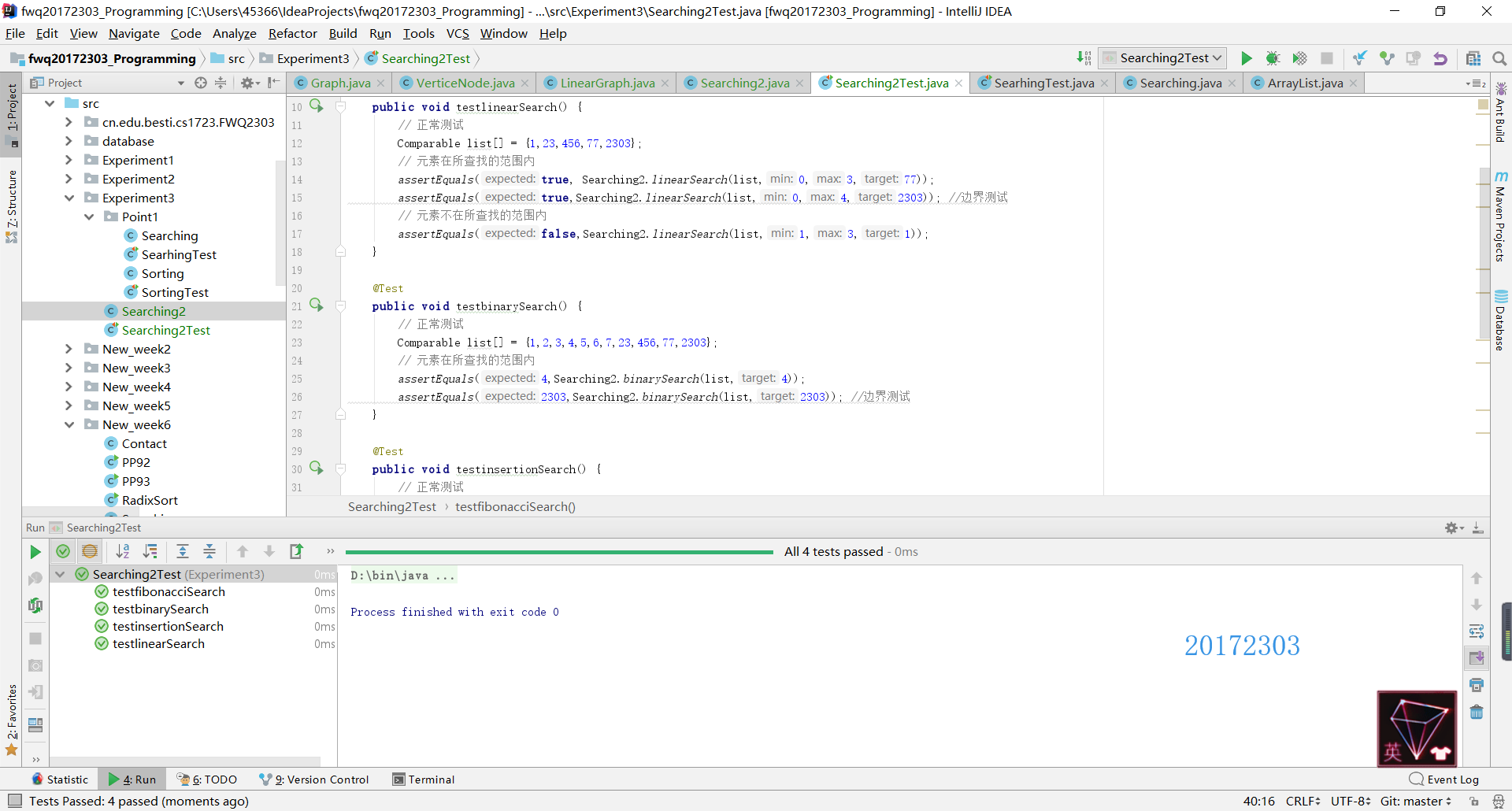
节点四
- 节点四的要求是再实现几种排序方法,我一共实现了七种排序算法:插入排序、冒泡排序、归并排序、快速排序、堆排序、希尔排序和二叉树排序。其中前五种排序都是书上直接实现的(堆排序在第十二章,其余在第九章),主要说一下希尔排序和二叉树排序的实现。
希尔排序
- 概念:希尔排序是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素,希尔排序又叫缩小增量排序。
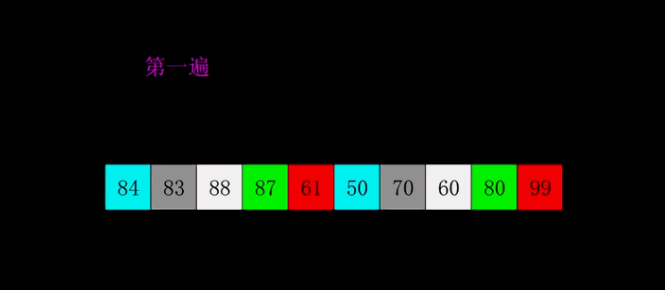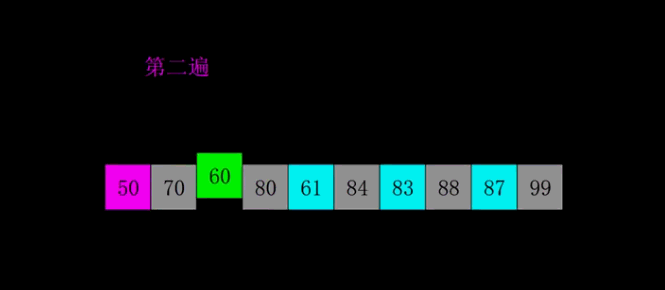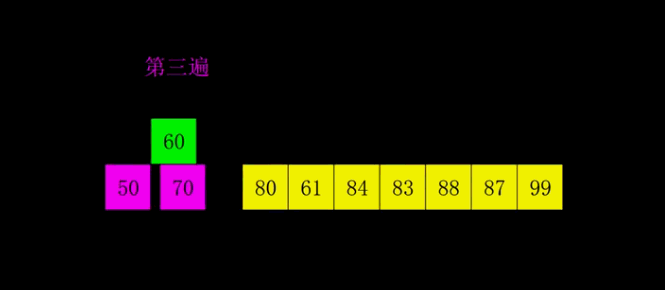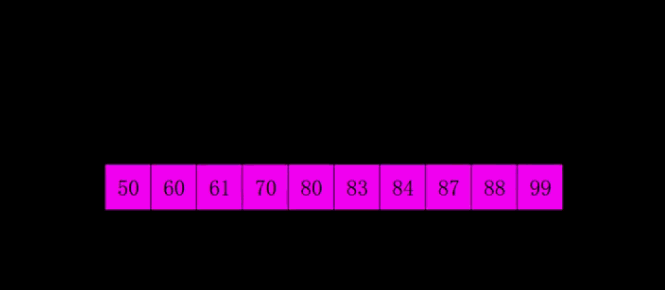
- 代码分析:希尔排序的核心在于间隔序列的设定。既可以提前设定好间隔序列,也可以动态的定义间隔序列。我在实现的过程中设置的是动态定义间隔,每次循环时新的间隔等于原间隔的一般。
public static void ShellSort(int[] data, int length){
int i = length;
while (i > 1){
// 动态定义间隔
i = (i + 1) / 2;
for (int j = 0;j < length - i;j++){
// 当对应比较的两个数中前者大于后者时进行交换
if (data[j + i] < data[j]){
int temp = data[j + i];
data[j + i] = data[j];
data[j] = temp;
}
}
}
}
二叉树查找
- 概念:二叉树查找的实际其实是使用二叉查找树来实现排序。
- 代码分析:实现的方法是将目标数组中的数打乱顺序随机添加到二叉查找树中,之后将树中的元素按照层序遍历的顺序输出形成一个新的数组,将新数组的元素与原数组的元素进行比较。
public void testBinaryTreeSort(){
String list[] = {"1","3","6","13","17","20","23","81","99","2303"};
LinkedBinarySearchTree tree = new LinkedBinarySearchTree();
tree.addElement(2303);
tree.addElement(99);
tree.addElement(81);
tree.addElement(23);
tree.addElement(20);
tree.addElement(17);
tree.addElement(13);
tree.addElement(6);
tree.addElement(3);
tree.addElement(1);
int a = tree.size();
String[] b = new String[a];
for (int i = 0;i < a;i++){
b[i] = String.valueOf(tree.findMin());
tree.removeMin();
}
// 正常测试+边界测试
assertEquals(b[0],list[0]);
}
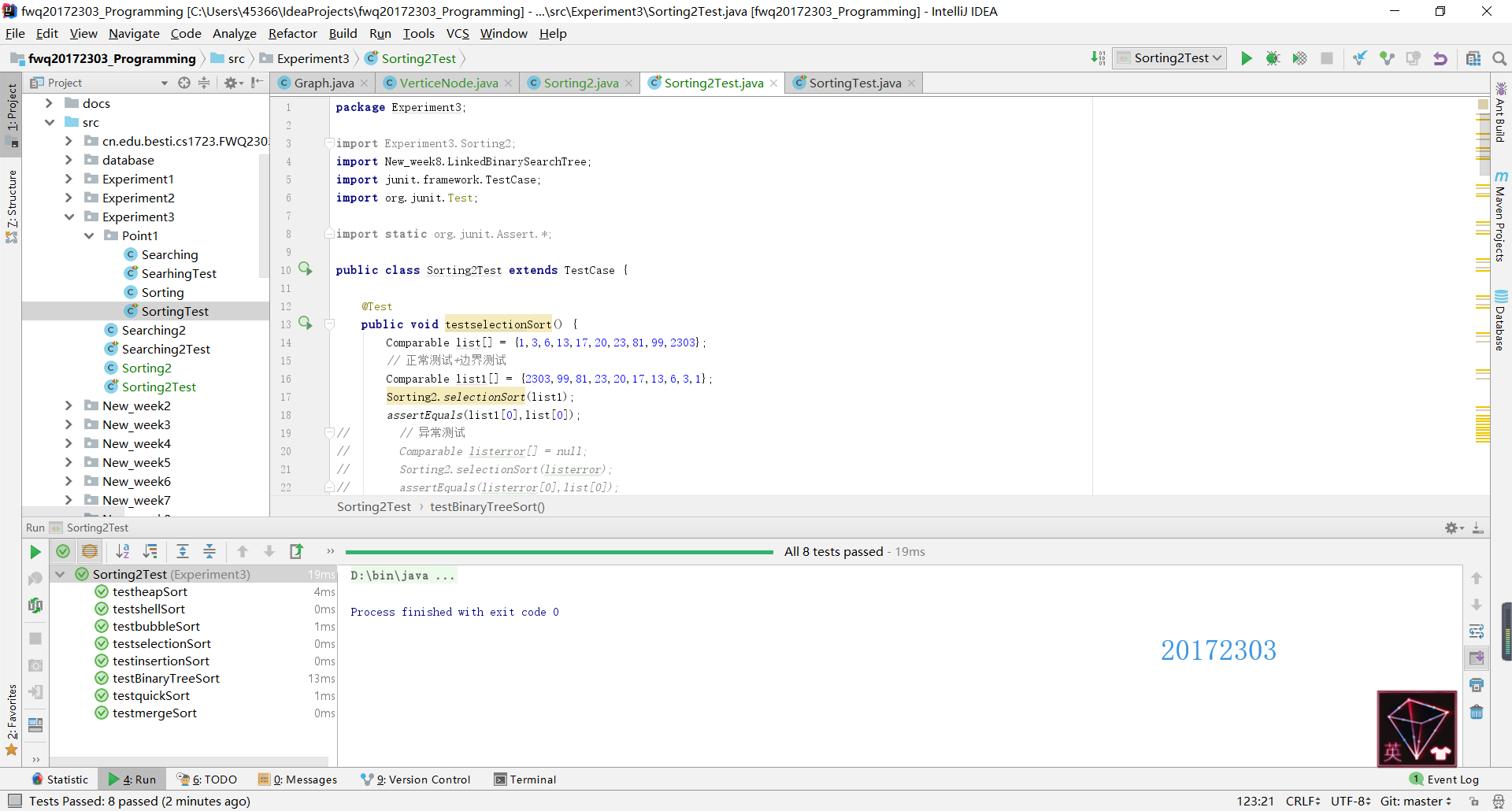
测试结果
- 正常测试
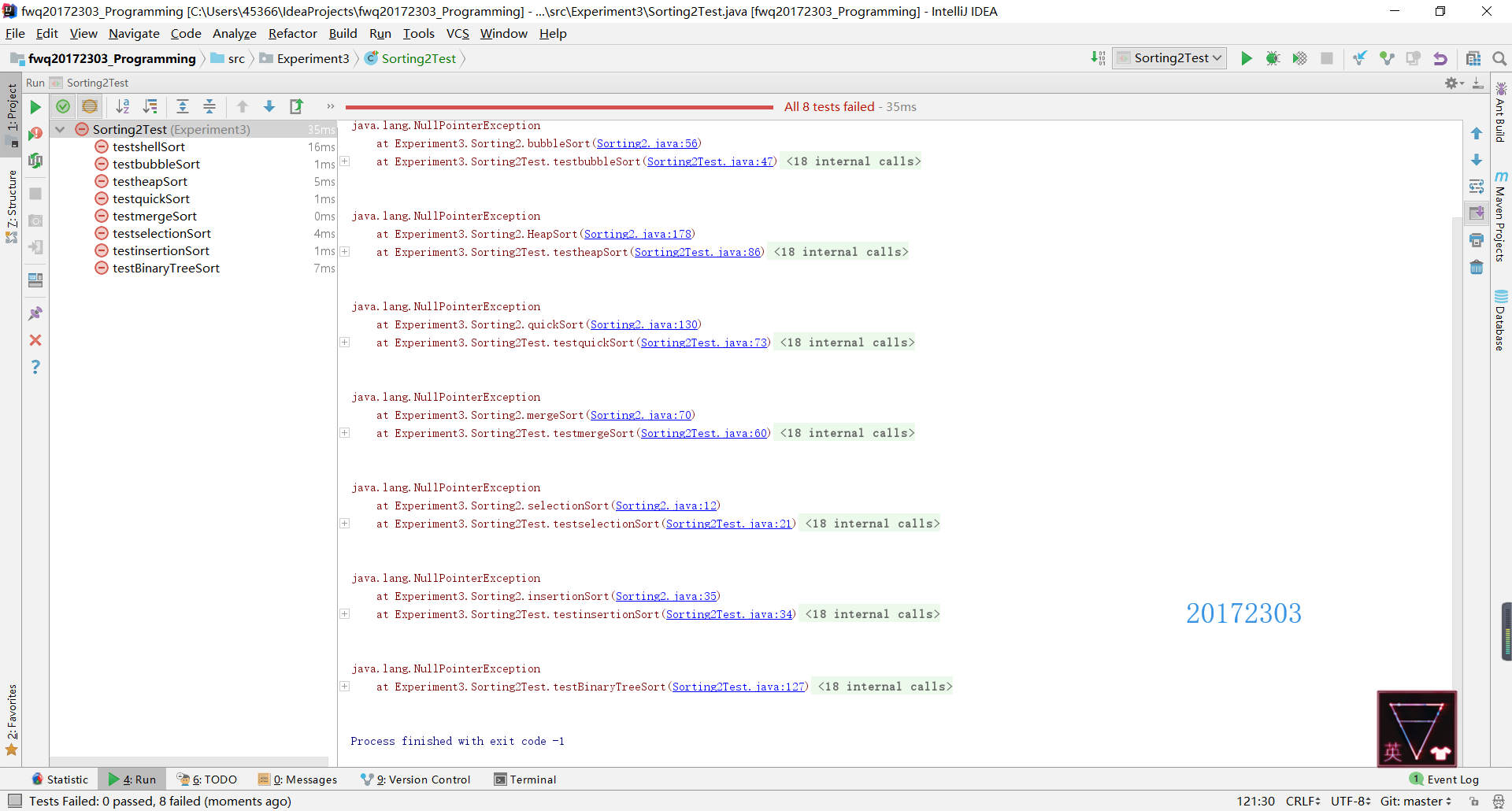
- 异常测试
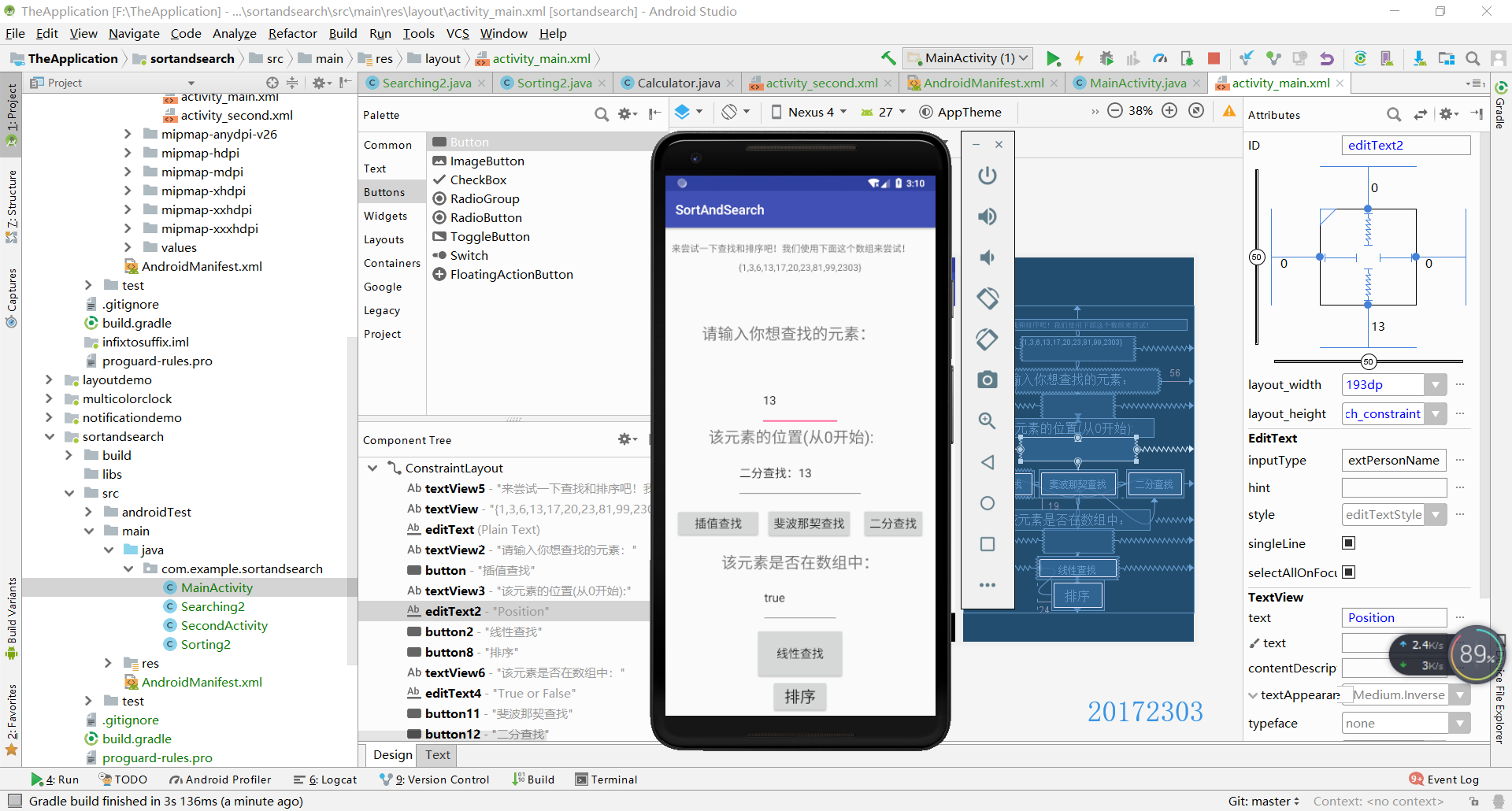
节点五(选做)
- 刚开始在AS里实现查找和排序时因为没有想好,所以就直接设定了一个数组进行测试,但是后来做完实验之后想到了其实可以让用户输入一系列数字的字符串再用StringTokenizer或者split进行拆分即可。
- 我设置了两个Activity,第一个Activity中实现查找,第二个Activity中实现排序。界面的跳转代码是关键。
button3.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Intent intent = new Intent(MainActivity.this,SecondActivity.class);
startActivity(intent);
}
});
- 这个测试的截图比较多,这里查找和排序各放一个,剩下的可以到蓝墨云班课里去看。
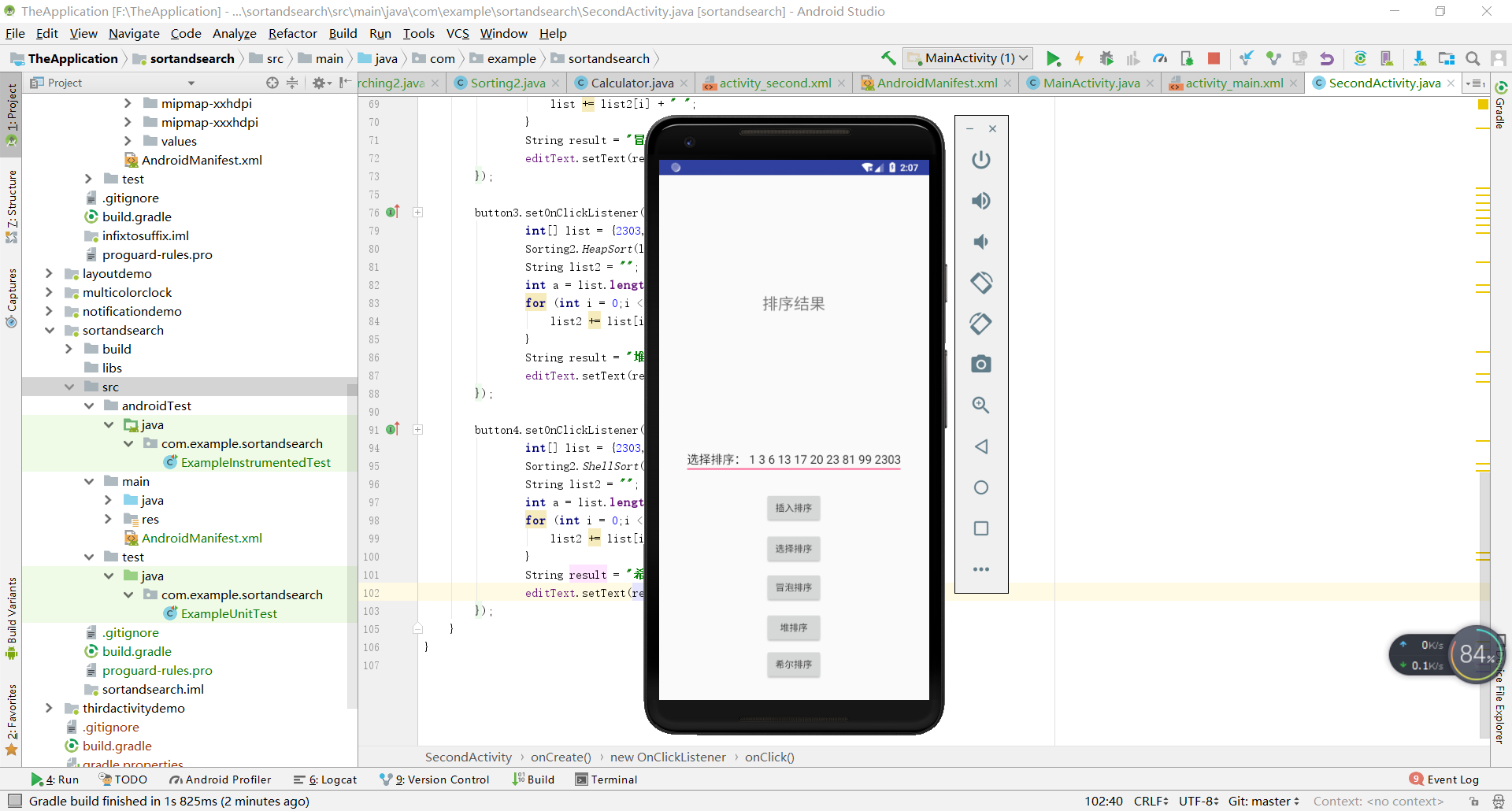
实验过程中遇到的问题和解决过程
- 问题1:JUnit的使用方法?
- 问题1解决情况:将近一个学期没有用过JUnit了,这回重新记起来之后觉得以防之后再次出现相同情况,还是记录一下比较好。
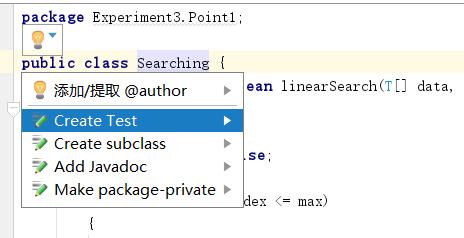
- Step1:选择要进行JUnit测试的类,在类名旁会出现一个小灯泡,点击灯泡后选择
Create Test。
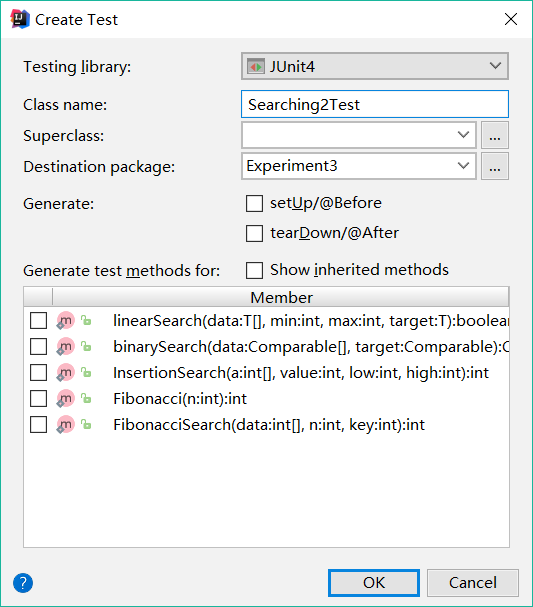
- Step2:在弹出的界面选择
Junit4然后点击OK。
- Step3:然后就创建了一个JUnit的测试类,之后在其中进行正常测试就好,要注意的是测试名中一定要含有test,可以直接编写正常的测试类,也可以用一些常用的JUnit的断言介绍进行测试:
- 用于值判断:assertEquals(String msg, Object expectRes, Object Res)
- 用于地址判断:assertSame(String msg, Object expectRes, Object Res)
- 用于Boolean判断:assertTrue(String msg,Boolean result)
- 用于判断result是否为NULL:assertNull(String msg,Object result)
- 用于地址判断:assertSame(String msg, Object expectRes, Object Res)
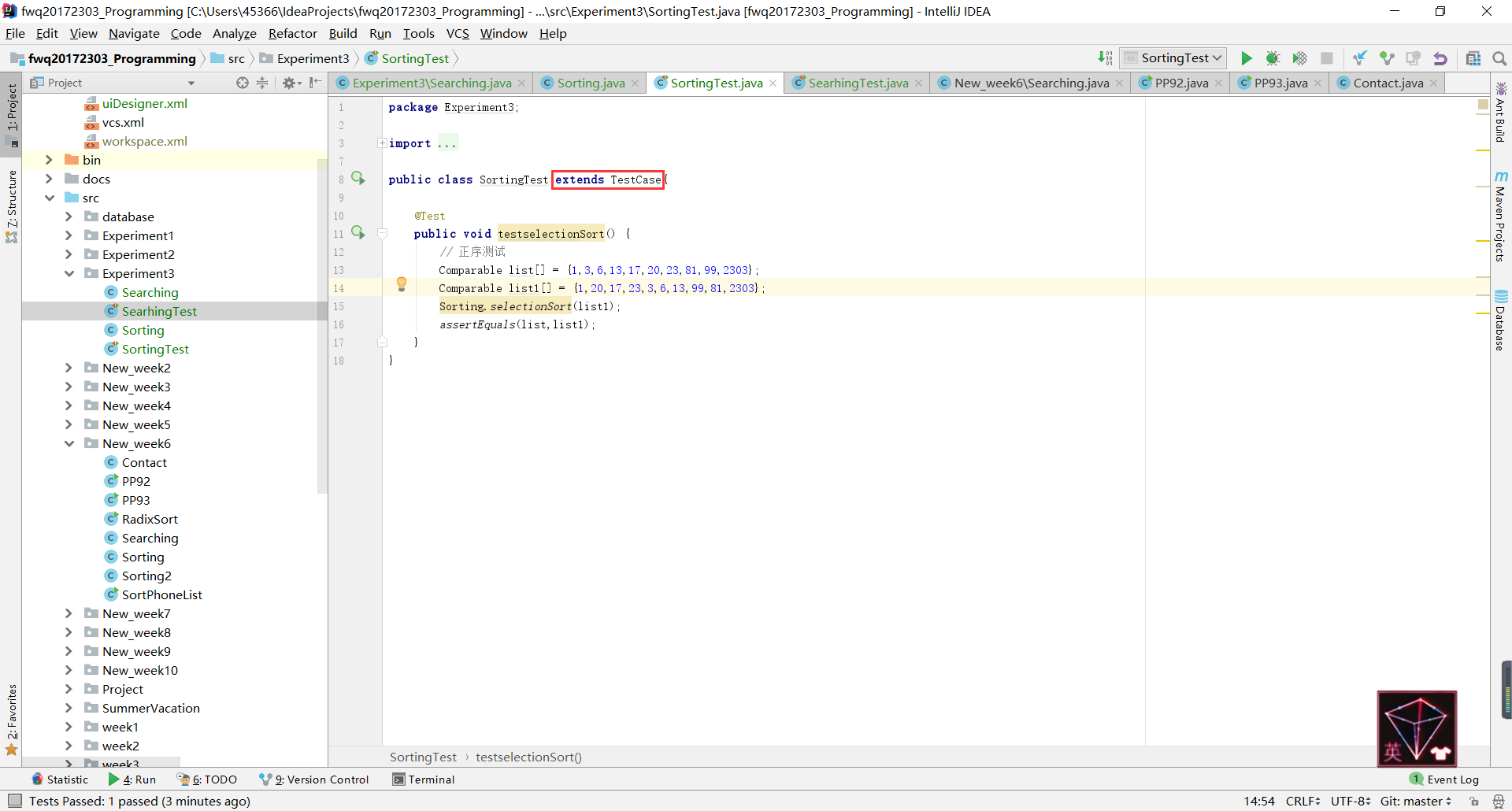
- 问题2:在刚刚开始进行JUnit测试时,显示“
assertEquals”
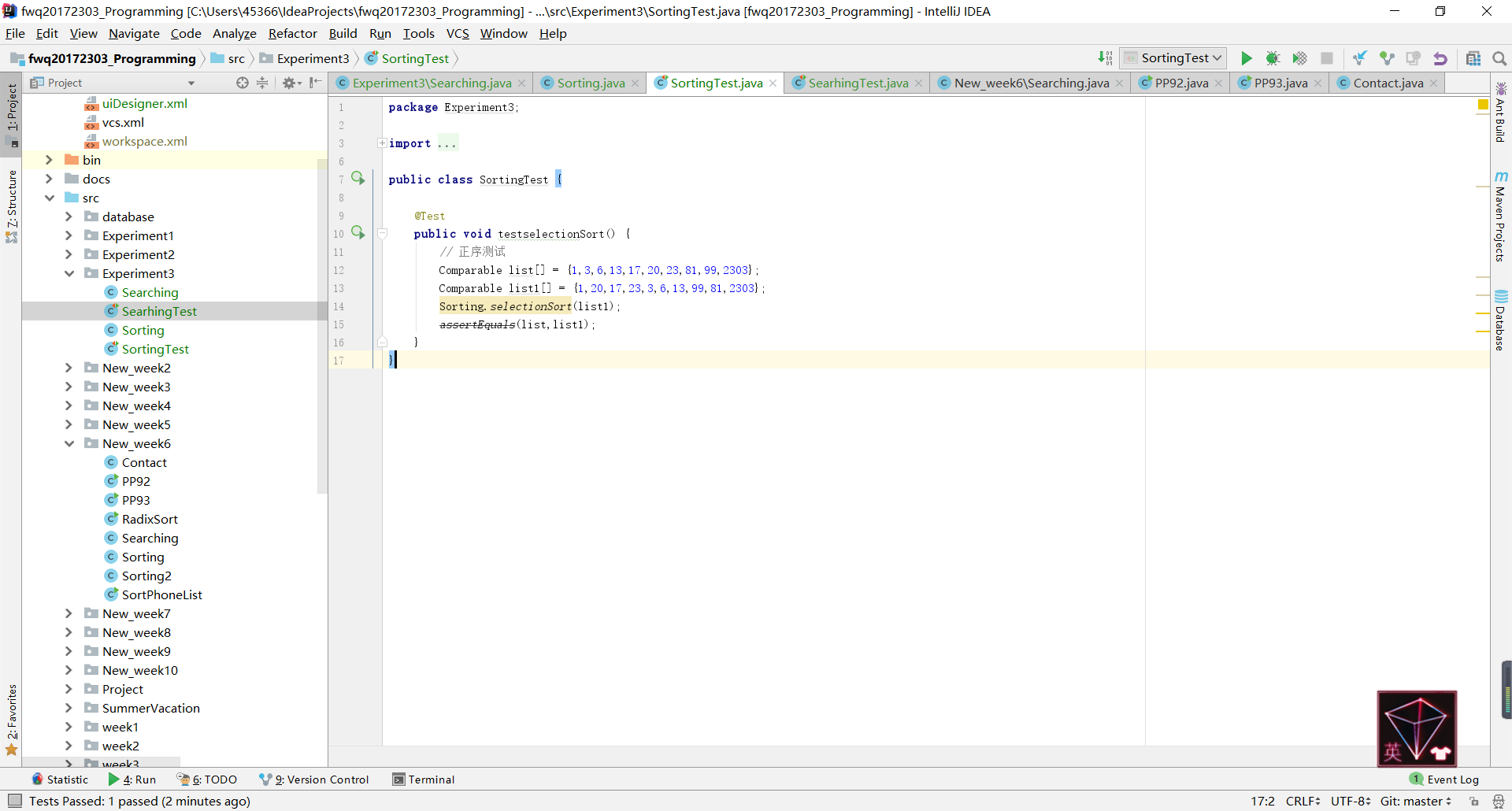
- 问题2解决情况:当时显示的问题是“您使用的方法已过时”,不是很明白为什么,上网查了半天也没有查到解决方法,最后在极为暴躁的情况下询问了结对伙伴张昊然同学,他说是因为我没有
extend TestCase,在尝试之后发现真的没有透印了,就很开心地解决了这个问题并收获了结对伙伴的嘲笑。
其他(感悟、思考等)
- 本次实验和上回实验的感觉差不多,难度并不大,但是需要重新捡起很多东西,在本次实验中又复习了很多知识,开心!

参考资料