1. 先关闭掉所有的防火墙(master和所有slave)
2. 配置yarn-site.xml文件(配置所有机器,此时没有启动hadoop服务)
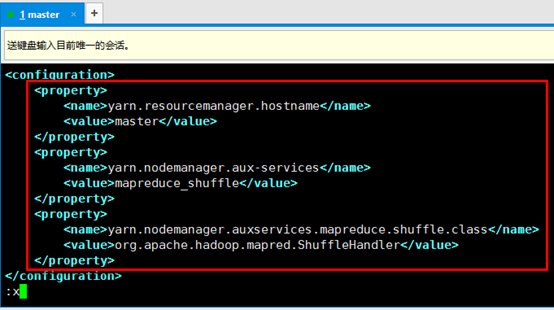
3. 启Yarn,输入要命令start-yarn.sh,用jps检测,看到如下情况表示启动成功
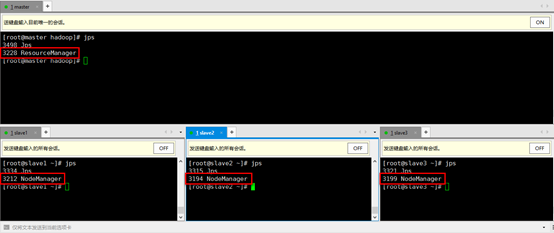
4. 在宿主机浏览器上进行查看,输入地址master:8088,可以看到Yarn的相关情况:
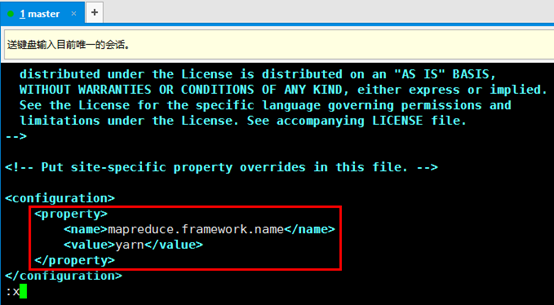
5. 下面我们在Yarn上跑一个计算,由于我们需要计算的文档存放的hdfs上,因此我们首先需要启动hadoop服务。然后需要指定MapReduce跑在Yarn上,配置mapred-site.xml(听老师讲的时候,配置的是这个文件,可是我的机器上没有这个文件,只有mapred-queues.xml.template,于是我copy了它一份,把名字改成了mapred-queues.xml)
6. 首先在本地创建一个文件,用于计算的时候使用:
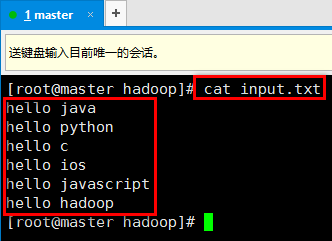
7. 在hadoop根目录下创建一个文件夹input,并将上述创建的文件上传到该目录下:

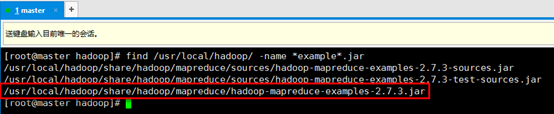
8. 计算的功能是,计算该文件中有多少个单词,每个单词出现的次数。查找一下该例子程序:
9. 运行该例子程序,输入命令:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/input.txt /output
hadoop jar为运行jar包,后面跟的是jar包的完全路径,wordcount为指定该jar中的方法,/input/input.txt为要操作的文件,也可以指定一个目录,那就hadoop就会统计目录下的所有文件内容,再后边的/output为执行结果的输出目录。
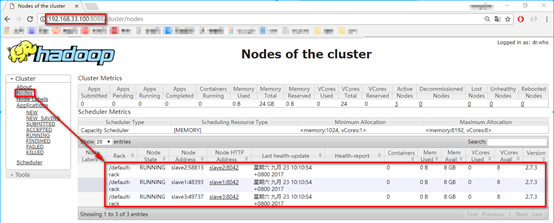
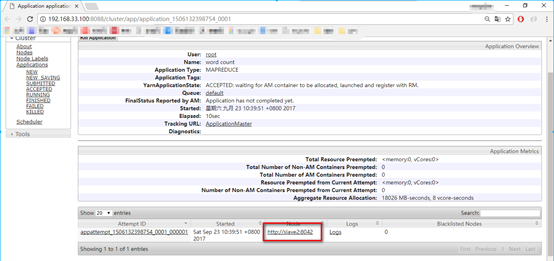
10. 在宿主机浏览器中查看,点击Applicatons,发现有一个任务了

11. 点击该任务的ID,进入查看该任务的详情,发现该任务在slave2上运行,点击该链接进入查看(打不开的话尝试使用slave2的ip加端口8082)
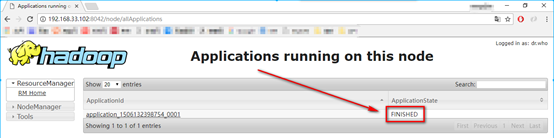
12. 进入slave2后,点击List of,发现该任务已经完成了
13. 查看一下刚才任务的输出目录

14. 查看这个输出文件
