1. 查看VM的网络配置
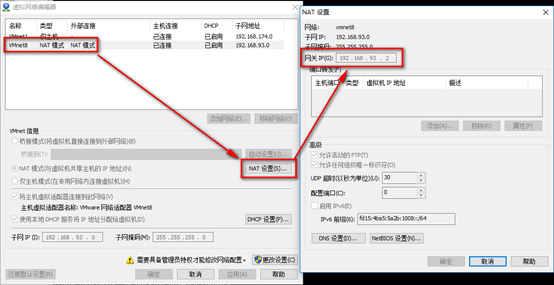
2. 打开虚拟机,配置网络:
a). vim /etc/sysconfig/network-scripts/ifcfg-eno16777736
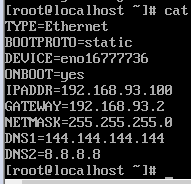
注意:这里的192.168.93.2必须安装步骤1里的网关IP,100为自己设置的IP,但是192.168.93不能变!
b). 重启网络service network restart,ping宿主机检查是否可以ping通。若ping不通,尝试关闭宿主机和虚拟机的防火墙。
systemctl stop firewalld(关闭防火墙)
systemctl disable firewalld(禁用防火墙)
3. 修改主机名称hostnamectl set-hostname master(注意:主机名千万不能有下划线!)
4. 使用Xshell将jdk和hadoop安装文件传至虚拟机/usr/local目录下。
5. 安装jdk
rpm -ivh hadoop-2.7.3.tar.gz,输入java -version检查是否安装成功。
6. 解压hadoop: tar -zxvf hadoop-2.7.3.tar.gz
修改hadoop目录名:mv hadoop-2.7.3 hadoop
7. 修改hadoop-env.sh
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改export JAVA_HOME为export JAVA_HOME=/usr/java/default
8. 配置hadoop环境变量
vim /etc/profile
末尾追加
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
重启环境变量
source etc/profile
9. 测试hadoop命令是否可以直接执行,任意目录下敲hadoop
10. 关闭虚拟机,给该虚拟机拍快照,并复制该虚拟机三分。验证四台虚拟机,使其可以互相ping通。
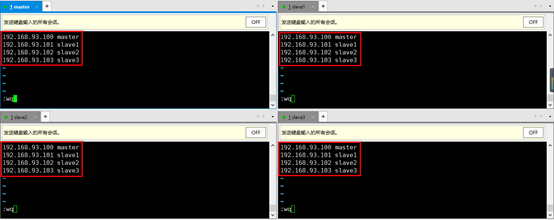
11. 修改四台机器的host文件vim /etc/hosts(同时操作4台机器)
12. 在4台机器上配置core-site.xml,使4台机器知道namenode位于哪台机器上。vim /usr/local/hadoop/etc/hadoop/core-site.xml
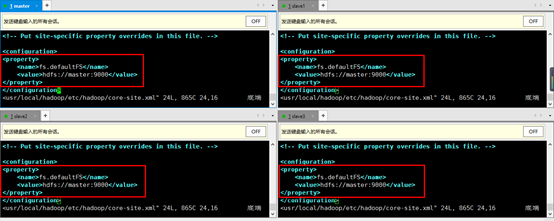
hadoop有namenode和datanode,此处的master虚拟机就是一个namenode,namenode记录了所有存储到集群当中文件的信息,包括文件名,文件被分成了几块,每一块具体存放在哪一台datanode上等等一系列信息,而datanode就是存放的具体的文件。
13. 格式化存储namenode的文件(只在master机器上操作)
hdfs namenode -format,看到如下表示成功
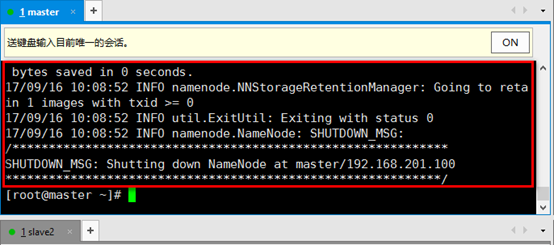
14. 启动namenode,只在master机器上操作
hadoop-daemon.sh start namenode
检查是否启动成功,输入命令jps,出现以下内容表示启动成功
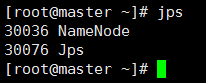
15. 启动datanode,在另外三台机器上同时操作
hadoop-daemon.sh start datanode
检查是否启动成功,输入命令jps,出现以下内容表示启动成功
