A. Toy Train
- 时间限制:2 seconds
- 内存限制:256 megabytes
题意
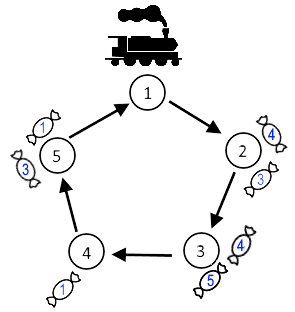
有编号~的车站顺时针呈环排列,有个糖果需要运送到指定位置。每个糖果由表示,其中,指这个糖果最初位置和需要运送到的位置。列车只能顺时针行驶,行驶到相邻站台所用时间为。每到一个站台,最多只能取走一个糖果放在车上,这个糖果可以随便选。而卸下糖果的数量不限制。询问列车从每个位置出发把所有糖果都运送到指定位置的最短时间。
下图中蓝色的数字就表示该糖果要去的位置。
分析
假设第个车站有个糖果,显然对于这个车站必须要至少经过次。那么决定最后在哪个地方停止一定是最后一个糖果。根据贪心的策略,我们只要把最近的糖果最后取就行了。
所以我们枚举起始点,再枚举每一个车站,如果车站有糖果的话,取完车站的至少需要走的时间就是。所有的取最大值就是答案了。
表示从走到的距离,具体值等于
代码如下
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 5005;
int n, m, sz[MAXN], mn[MAXN];
inline int dist(const int &A, const int &B) { return B >= A ? B-A : n+B-A; }
int main () {
scanf("%d%d", &n, &m);
memset(mn, 0x7f, sizeof mn);
for(int x, y, i = 1; i <= m; ++i) {
scanf("%d%d", &x, &y); ++sz[x];
mn[x] = min(mn[x], dist(x, y));
}
for(int i = 1; i <= n; ++i) {
int ans = 0;
for(int j = 1; j <= n; ++j) if(sz[j])
ans = max(ans, dist(i, j) + n*(sz[j]-1) + mn[j]);
printf("%d ", ans);
}
}
B. Wrong Answer
- 时间限制:1 seconds
- 内存限制:256 megabytes
这题目好啊
题意
有这样一个问题,给出长度为的整数序列,求。
其中。
同学玩够各类博弈游戏发现自己老是输给,决定卧薪尝胆好好刷题。她遇到了这个问题,然后写了这样一个代码:
function find_answer(n, a)
# Assumes n is an integer between 1 and 2000, inclusive
# Assumes a is a list containing n integers: a[0], a[1], ..., a[n-1]
res = 0
cur = 0
k = -1
for i = 0 to i = n-1
cur = cur + a[i]
if cur < 0
cur = 0
k = i
res = max(res, (i-k)*cur)
return res
显然这个代码是的。举个例子,假设 且 。那么 得到的答案是 , 然正确答案是。
给出,你要构造一组数据,使得的答案和正确答案相差恰好为。你构造的序列必须也满足上面所说的。如果不存在请输出。
分析
可以看出的程序只统计了非负数的区间。那么我们只需要搞一个在最前面,然后让后面序列的和尽量的大。这是的答案一定是的和乘以后面的长度,但是多取这个会让答案变成。我们只要保证就行了,即。
那么我们构造出来的序列除去前面的-1就是长度为,和为的序列。因为我们实际上是可以补0的,那么要让后面的个数和为。只要前面尽量放,就行了。不过由于这个的限制,要求,因为,,所以随便取个就行了。
代码如下
#include <bits/stdc++.h>
using namespace std;
int main () {
int k;
scanf("%d", &k);
//sum*1200 = (sum-1)*1201 - k
//sum = k + 1201
int sum = k + 1201;
printf("1201
-1");
for(int i = 1; i <= 1200; ++i) {
int ans = min(1000000, sum);
sum -= ans;
printf(" %d", ans);
}
}
C. Morse Code
- 时间限制:2 seconds
- 内存限制:256 megabytes
题意
把二十六个字母的摩尔斯电码用二进制表示就是一些串。摩尔斯电码长度从~不等,但是这样算出来是,那么就有个串没有所代表的字母。它们分别是"","","",和""。
最初你有一个空串,有次添加,每次添加,每添加一次都要输出当前得到的串的所有子串能够翻译出的不同的字母串的数量,答案膜输出。比如"111"能够翻译出的就是这些:
“T” (translates into “1”)
“M” (translates into “11”)
“O” (translates into “111”)
“TT” (translates into “11”)
“TM” (translates into “111”)
“MT” (translates into “111”)
“TTT” (translates into “111”)
分析
假设你有一个固定的串,求它能够翻译出的不同字母串的dp还是很好想的。时间复杂度是。那么一个暴力的想法就是枚举每个不同子串做dp,这样dp的总时间复杂度是。
然而我们发现当左端点固定的时候,右端点递增时其实可以一起dp的。那么对于左端点固定的子串,dp就是的。
然而这个是每一次在最后添加一个字符。不能固定左端点。
怎么办呢?
那就固定右端点倒着dp呗。
然后我判重用,多了一个再加上dp有个的常数就了。
怎么办呢,这时候又用到上面那个共用的思想(…),我们用trie树来判串的重,如果到最后一个字符的个节点已经有值了那么已经算过,就不加到答案里面;否则就统计答案。右端点固定的话左端点递减的串在trie树上是一条路径,这样的话插入这些右端点固定的子串时间复杂度就是的了。
右端点有个,那么总时间复杂度就是的了。
代码如下
#include <bits/stdc++.h>
using namespace std;
const int MAXN = 3010;
const int mod = 1e9 + 7;
int n, x[MAXN], dp[MAXN], ans, trie[MAXN*MAXN][2];
inline bool chk(int i) {
if(!x[i-3] && !x[i-2] && x[i-1] && x[i]) return 0;
if(!x[i-3] && x[i-2] && !x[i-1] && x[i]) return 0;
if(x[i-3] && x[i-2] && x[i-1] && !x[i]) return 0;
if(x[i-3] && x[i-2] && x[i-1] && x[i]) return 0;
return 1;
}
inline void add(int &x, int y) { x += y; if(x >= mod) x -= mod; }
int main () {
scanf("%d", &n);
for(int i = 1; i <= n; ++i)
scanf("%d", &x[i]);
int rt = 1, cnt = 1;
for(int i = 1; i <= n; ++i) {
dp[i+1] = 1;
int r = rt;
for(int j = i; j; --j) {
dp[j] = 0;
add(dp[j], dp[j+1]);
add(dp[j], dp[j+2]);
add(dp[j], dp[j+3]);
if(chk(j+3)) add(dp[j], dp[j+4]);
if(!trie[r][x[j]]) trie[r][x[j]] = ++cnt, add(ans, dp[j]);
r = trie[r][x[j]];
}
printf("%d
", ans);
}
}
D. Isolation
- 时间限制:3 seconds
- 内存限制:256 megabytes
题意
给出长度为的数组。给出。求把这个序列分成若干块的方案,使得对于每个区间,只出现一次的数字不超过个。
分析
首先暴力dp很好想的,转移方程式为:
中只出现一次的数不超过个
我们看看怎么记录只出现一次的数的个数,就是从后往前扫,遇到数的第一次+1,第二次-1,然后做一个后缀和就行了。那么对于后缀和的位置,就能够当作决策点。为了方便我们把的下标同时加一就行了。
这样的话每往后移动就修改两个区间(画画就知道了),区间修改可以用线段树,但是穿插着查询的话无法处理,于是分块做。每个块存一下后缀和为每个值的值的和,也要存一下后缀和的值的和,也就是这个块内的答案。也要维护懒标记。
时间复杂度
代码如下
#include<bits/stdc++.h>
using namespace std;
typedef long long LL;
const int mod = 998244353;
const int MAXN = 100005;
const int Blocks = 405;
int n, qk, a[MAXN], pre[MAXN], lst[MAXN], dp[MAXN], f[MAXN];
int sum[Blocks][MAXN], ans[Blocks], lz[Blocks], l[Blocks], r[Blocks], bl[MAXN];
inline void add(int &x, int y) { x += y; x = x >= mod ? x - mod : x; }
inline void sub(int &x, int y) { x -= y; x = x < 0 ? x + mod : x; }
inline void Rebuild(int x) {
for(int k = l[x]; k <= r[x]; ++k) sum[x][f[k]] = 0, f[k] += lz[x];
lz[x] = ans[x] = 0;
for(int k = l[x]; k <= r[x]; ++k) {
add(sum[x][f[k]], dp[k]);
if(f[k] <= qk) add(ans[x], dp[k]);
}
}
inline void Update(int k, int val) {
int x = bl[k];
sub(sum[x][f[k]], dp[k]);
if(f[k] <= qk) sub(ans[x], dp[k]);
f[k] += val;
add(sum[x][f[k]], dp[k]);
if(f[k] <= qk) add(ans[x], dp[k]);
}
inline void Modify(int x, int y, int val) {
int L = bl[x], R = bl[y];
if(L == R) {
Rebuild(L);
for(int k = x; k <= y; ++k)
Update(k, val);
}
else {
Rebuild(L);
for(int k = x; k <= r[L]; ++k) Update(k, val);
Rebuild(R);
for(int k = l[R]; k <= y; ++k) Update(k, val);
for(int i = L+1; i < R; ++i)
if(val == 1) {
int tmp = qk - (lz[i]++);
sub(ans[i], sum[i][tmp]);
}
else {
int tmp = qk - (--lz[i]);
add(ans[i], sum[i][tmp]);
}
}
}
inline int Query(int x) {
int re = 0;
Rebuild(bl[x]);
for(int k = l[bl[x]]; k <= x; ++k)
if(f[k] <= qk) add(re, dp[k]);
for(int i = 1; i < bl[x]; ++i) add(re, ans[i]);
return re;
}
int main() {
scanf("%d%d", &n, &qk);
for(int i = 1; i <= n; ++i) {
scanf("%d", &a[i]);
pre[i] = lst[a[i]];
lst[a[i]] = i;
}
dp[1] = 1;
int m = sqrt(n);
for(int i = 1; i <= n; ++i) {
bl[i] = (i-1)/m + 1;
r[bl[i]] = i;
if(!l[bl[i]])
l[bl[i]] = i;
}
for(int i = 1; i <= n; ++i) {
Modify(pre[i]+1, i, 1);
if(pre[i])
Modify(pre[pre[i]]+1, pre[i], -1);
dp[i+1] = Query(i);
}
printf("%d
", dp[n+1]);
}
写加法减法的时候用问号语句600ms,用if语句1400ms。。
E. Legendary Tree
- 时间限制:3 seconds
- 内存限制:256 megabytes
题意
给出树的节点数,你的任务是确定树的结构。
你可以询问次,每次查询,格式如下
表示询问从集的某个点经过走到集的某个点的简单路径条数。其中
分析
先把1设为根
那么我们只要查询次 就能得到的子树大小。
我们的目标是找到所有个节点的父亲
显然父亲的比儿子大
我们把2~n的节点按排序
用一个vector存储到目前还没有找到父亲的点,这些点实际上可以看做叶节点,因为那些找到了父亲的点已经被我们从vector内删去。
按从小到大考虑,当前考虑到第个点,如果它有儿子,那么一定存在于vector中。如果是的父亲,那么一定存在从的路径,反之一定不存在(不可能有隔代的路径,因为我们是按从小到大考虑,隔代的情况不会出现 因为中间那一代小会被先考虑)。所以我们可以用一次查询来判断叶节点集内是否有的儿子。那么我们二分找到最左边的一个儿子,将它删去,并把它的父亲设为。这样一直做下去,就行了。一个点只会被删一次,查询次。
总查询次数是
时间复杂度是
#include<bits/stdc++.h>
using namespace std;
vector<int>S, T, vec;
#define pb push_back
const int MAXN = 505;
int n, sz[MAXN], c[MAXN], fa[MAXN];
inline int query(int x) {
printf("%d
", S.size());
for(auto v:S) printf("%d ", v);
printf("
%d
", T.size());
for(auto v:T) printf("%d ", v);
printf("
%d
", x);
fflush(stdout);
int re; scanf("%d", &re);
return re;
}
inline bool chk(int x, int pos) {
T.clear();
for(int i = 0; i <= pos; ++i)
T.pb(vec[i]);
return query(x);
}
inline void getchild(int x) {
while(!vec.empty()) {
int l = 0, r = vec.size()-1, pos = -1;
while(l <= r) {
int mid = (l + r) >> 1;
if(chk(x, mid)) pos = mid, r = mid-1;
else l = mid+1;
}
if(~pos) {
fa[vec[pos]] = x;
swap(vec[pos], vec.back());
vec.pop_back();
}
else return;
}
}
inline bool cmp(int A, int B) { return sz[A] < sz[B]; }
int main() {
scanf("%d", &n);
S.pb(1);
for(int i = 2; i <= n; ++i) T.pb(i), c[i-1] = i;
for(int i = 2; i <= n; ++i) sz[i] = query(i);
sort(c + 1, c + n, cmp);
for(int i = 1; i < n; ++i) {
int x = c[i];
getchild(x);
vec.pb(x);
}
puts("ANSWER");
for(int i = 2; i <= n; ++i)
printf("%d %d
", fa[i]?fa[i]:1, i);
}//最后自动fflush
这道题200组数据又是交互题很慢直接评测了5min。。。