技术人如果经常线上操作DB,河边走久了,难免出现纰漏:
(1)update错数据;
(2)delete错数据;
(3)drop错数据;
从“从库”恢复数据。
一般来说数据库集群是主从架构: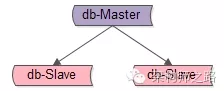
如果人为执行“删库”操作,命令会同步给其他从库,导致所有库上的数据全被删除,无法恢复,故这种方案不可取。
一、如果DBA没有做功课,最常见的处理方案是什么?
如果没有做数据安全方案,应对“删库”最常见的操作是,跑路。删掉了公司最重要的资产,还不快闪。
二、如果DBA日常做了全量备份+增量备份,应该怎么处理?
DBA最常见的技能是:全量备份+增量备份。
全量备份:定期(例如一个月)将库文件全量备份。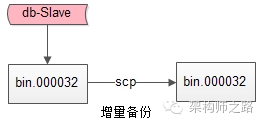
增量备份:定期(例如每天)将binlog增量备份。
如果不小心“删库”,可以这么恢复:
(1)将最近一次全量备份的全库找到,拷贝回来(文件一般比较大),解压,应用;
(2)将最近一次全量备份后,每一天的增量binlog找到,拷贝回来(文件较多),依次重放;
(3)将最近一次增量备份后,到执行“删全库”之前的binlog找到,重放;
恢复完毕。
为了保证方案的可靠性,需要定期进行演练。
咦,怎么好像没听过DBA定期做过这类演练?
很有可能只是做了理论上的方案,如果真出了问题,效果也只是理论上能恢复。此时回归方案一,跑路。
全量备份+增量备份的恢复周期也非常长,可能是天级别。
画外音:把几T的数据传输过来都用了好长时间。
三、如果DBA做了“1小时延时从库”,应该怎么处理?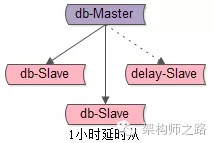
什么是1小时延时从库?
如上图,增加一个从库,这个从库不是实时与主库保持同步的,而是每隔1个小时同步一次主库,同步完之后立马断开1小时,这个从库会与主库保持1个小时的数据差距。
当“删全库”事故发生时,如何利用“1小时延时从库”快速恢复数据?
(1)应用1小时延时从;
(2)将1小时延时从最近一次同步时间到,执行“删全库”之前的binlog找到,重放
快速恢复完毕。
这个方案的优点是,能够快速找回数据。潜在不足是,万一“1小时延时从库”正在连上主库进行同步的一小段时间内,发生了“删库”事故,也无法恢复。
四、如果DBA做了“双份1小时延时从库”,应该怎么处理?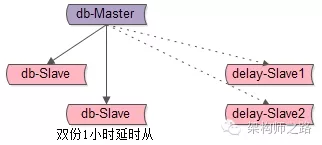
什么是双份1小时延时从?
如上图,两个1小时延时从库,它们连主库同步数据的时间“岔开半小时”。
这样,即使一个延时从连上主库进行同步的一小段时间内,发生了“删库”事故,依然有另一个延时从保有半小时之前的数据,可以实施快速恢复。
这个方案的优点是,没有万一,一定能快速恢复数据。潜在的不足是,资源利用率有点低,为了保证数据的安全性,多了2台延时从,降低了从库利用率。
如何提高从库利用效率?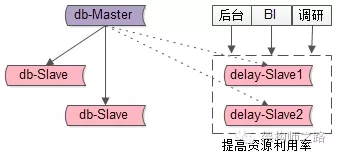
对于一些“允许延时”的业务,可以使用1小时延时从,例如:
(1)运营后台,产品后台;
(2)BI进行数据同步;
(3)研发进行数据抽样,调研;
但需要注意的是,毕竟这是从库,只能够提供“只读”服务哟。
五 总结
保证数据的安全性是DBA第一要务:
(0)理论上可以恢复+跑路;
(1)全量备份+增量备份+定期演练;
(2)1小时延时从库;
(3)双份1小时延时从库+提高资源利用率;