利用百度搜集子域名--爬虫技巧
问题引入:
1. 何为子域名?
答:子域名是相对于网站的主域名的。比如百度的主域名为:baidu.com,这是一个顶级域名,而在顶级域名前由”.”隔开加上不同的字符,比如zhidao.baidu.com,那么这就是一个二级域名,同理,继续扩展主域名的主机名,如jian.news.baidu.com,这就是一个三级域名,依次类推。
2. 手动收集子域名是怎样的一种过程?
举个例子,比如我们要收集qq.com这个主域名,在百度搜索引擎能够搜索到的所有子域名。
首先,使用搜索域名的语法 搜索~
搜索域名语法:site:qq.com
然后,在搜索结果中存在我们要的子域名信息,我们可以右键,查看元素,复制出来。
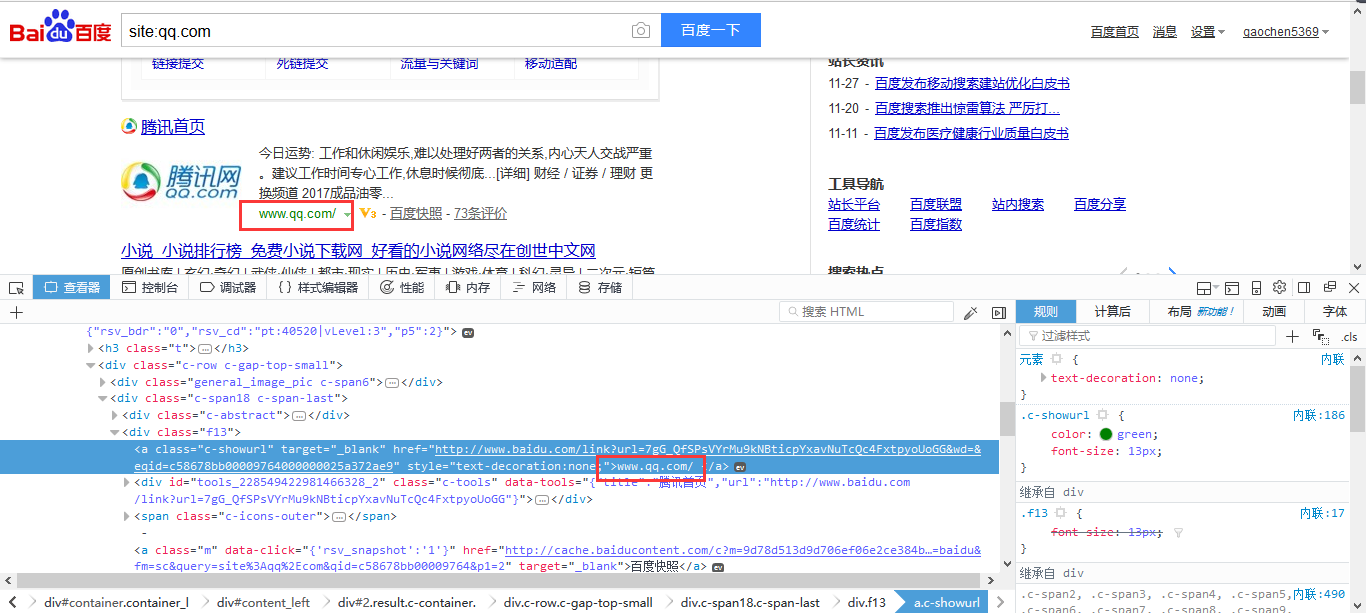
3. 如何用python替代手工的繁琐操作?
其实就是将手工收集用代码来实现自动化,手工收集的步骤:
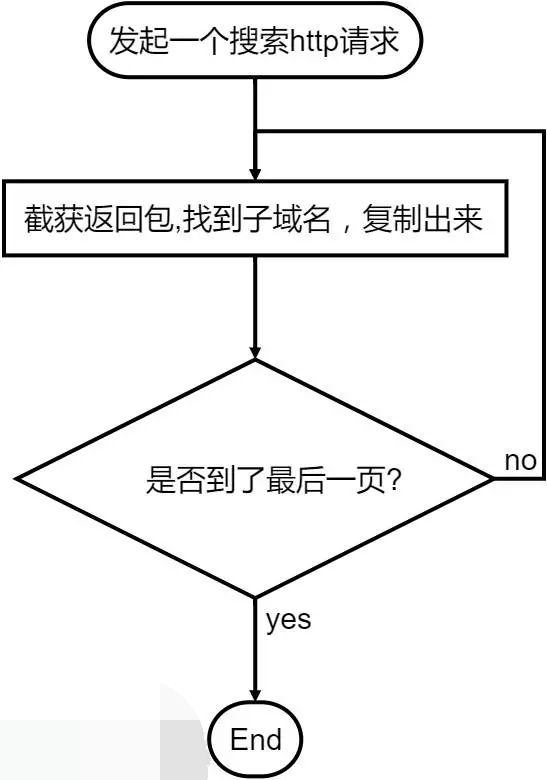
下面就是利用爬虫技巧把查询到的子域名都给爬下来。
1. 发起一个搜索的http请求
请求我们使用python的第三方http库,requests
需要额外安装,可以使用pip进行安装 pip install requests
requests 基本使用-example:
help(requests) 查看requests的帮助手册 。
dir(requests) 查看requests这个对象的所有属性和方法 。
requests.get(‘http://www.baidu.com‘)发起一个GET请求。
好了,补充基础知识,我们来发起一个请求,并获得返回包的内容。
#coding=utf-8
import re
import requests
url = 'http://www.baidu.com/s?wd=site:qq.com' #设定url请求
response = requests.get(url).content #get请求,content获取返回包正文
print response

返回包的内容实在太多,我们需要找到我们想要的子域名,然后复制出来。
从查看元素我们可以发现,子域名被一段代码包裹着,如下:
style=”text-decoration:none;”>www.qq.com/ </a>
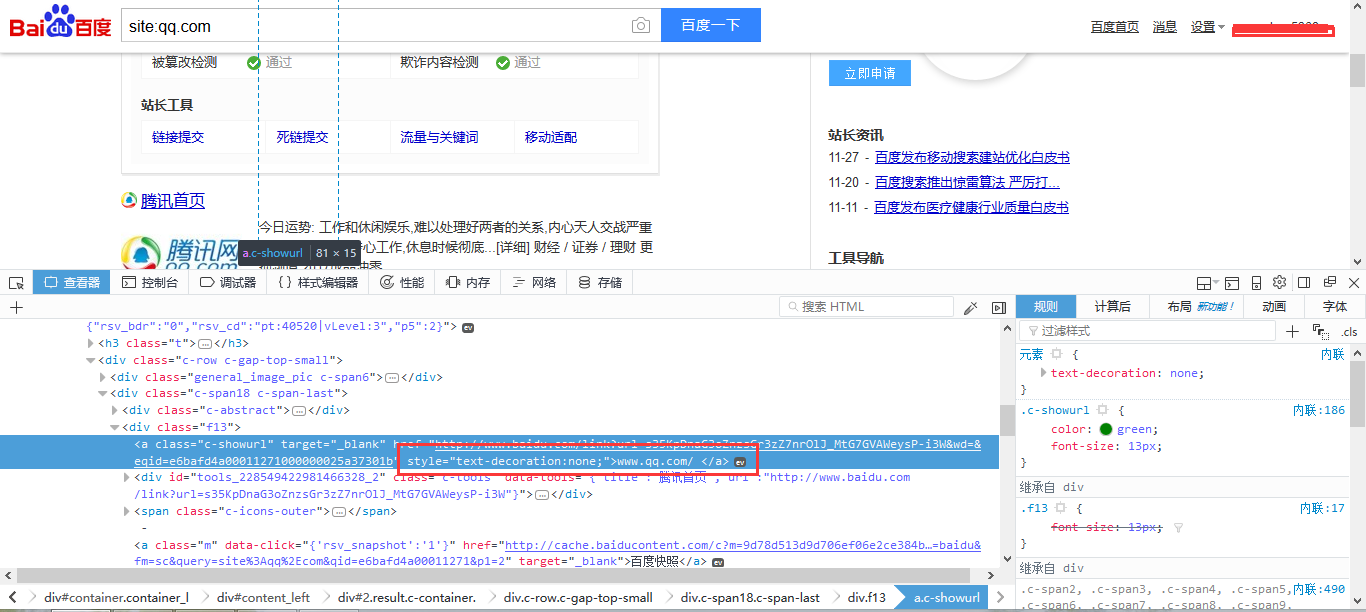
2. 正则表达式——(.*?)
正则 规则:style=”text-decoration:none;”>(.*?)/
正则表达式难吗?难。复杂吗?挺复杂的。
然而最简单的正则表达式,我们把想要的数据用(.*?)来表示即可。
re 基本使用-example:
假设我们要从一串字符串’123xxIxx123xxLikexx123xxStudyxx’取出ILike Study,我们可以这么写:
eg=’123xxIxx123xxLikexx123xxStudyxx’
print re.findall(‘xx(.*?)xx’,eg)
#打印结果
['I', 'Like', 'Study']
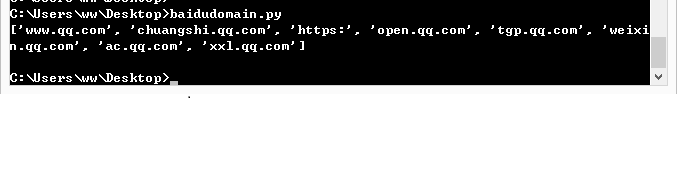
基于上述例子,获取子域名。
#coding=utf-8
import re
import requests
url = 'http://www.baidu.com/s?wd=site:qq.com' #设定url请求
response = requests.get(url).content #get请求,content获取返回包正文
baidudomain = re.findall('style="text-decoration:none;">(.*?)/',response)
print baidudomain
3. 翻页的处理
上面获得的子域名,仅仅只是返回结果的第一页内容,如何获取所有页面的结果?
url=”http://www.baidu.com.cn/s?wd=site:qq.com&pn=0″
url=”http://www.baidu.com.cn/s?wd=site:qq.com&pn=10″
url=”http://www.baidu.com.cn/s?wd=site:qq.com&pn=20″
...
#pn=0为第一页,pn=10为第2页,pn=20为第3页…
这个时候用循环来实现。
for i in range(100): #假设有100页
i=i*10
url="http://www.baidu.com.cn/s?wd=site:qq.com&pn=%s" %i
4. 重复项太多?想去重?
基础知识:
python的数据类型: set
set持有一系列的元素,但是set的元素没有重复项,且是无序的。
创建set的方式是调用set()并传入一个list,list的元素将作为set的元素。
sites=list(set(sites)) #用set实现去重
正则表达式匹配得到的是一个列表list,我们调用set()方法即可实现去重。
5. 完整代码&&总结
下面是百度搜索引擎爬取子域名的完整代码。
#coding=utf-8
import re
import requests
sites = []
for i in range(0,10): #10页为例
i = i*10
url = 'http://www.baidu.com/s?wd=site:qq.com&pn=%s' %i #设定url请求
response = requests.get(url).content #get请求,content获取返回包正文
baidudomain = re.findall('style="text-decoration:none;">(.*?)/',response)
sites += list(baidudomain)
site = list(set(sites)) #set()实现去重
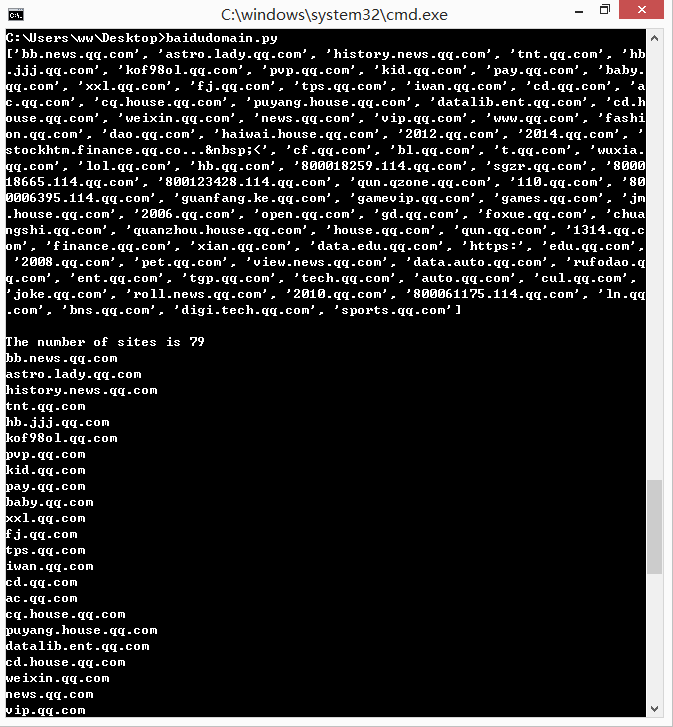
print site
print "
The number of sites is %d" %len(site)
for i in site:
print i
一个小小的爬虫,只不过我们是用百度的引擎来爬取,不过呢,用bing引擎爬去的数据量会比百度更多,所以建议大家使用bing,google的引擎,代码的编写方法和百度的大同小异就不放代码了,给个小tip,bing搜索域名用的是domain:qq.com这个的语法哦。上面的还可以进行文件操作,直接把得到的结果输入 txt 文件,如果有兴趣还可以进行下面的操作。比如 sql 注入,用百度进行搜索,形如index.php?id=1 ,按照上面的脚本修改一下,把url链接都爬下来,就像上面一样,然后写入文件,再读取刚刚写入的文件的url,用进行and 1=1 ///and 1=2 进行简单的注入检测。这只是简单的,当然可以在这个基础上进行刚深入的研究,逐步实现自动化。
任重而道远!