我们知道在SqlServer中,索引对查询语句的优化起着巨大的作用,一般来说在执行计划中出现了Index Seek的步骤,我们就认为索引命中了。但是Index Seek中有两个部分是值得我们注意的,我们来查看下面一个查询语句:
select [Title],[FirstName],[MiddleName],[LastName] from [dbo].[DimCustomer] where [MaritalStatus]=N'M' and [Gender]=N'F' and [NumberChildrenAtHome]>0 and [TotalChildren]=3
该语句从表[DimCustomer]查询列[Title],[FirstName],[MiddleName],[LastName], 查询条件用到了列[MaritalStatus],[Gender],[NumberChildrenAtHome],[TotalChildren]。我们知道建立索引的原则一般是把where条件中的列作为索引列(SqlServer对Where条件中列的使用方式也有要求,如果Where条件中的列使用不当,将导致索引不会被命中,但这不是本文讨论的重点),将在select后面的查询列作为Include列,所以根据这个原则我们建立如下非聚集索引[IX_MaritalStatus_Gender_TotalChildren_NumberChildrenAtHome]
CREATE NONCLUSTERED INDEX [IX_MaritalStatus_Gender_TotalChildren_NumberChildrenAtHome] ON [dbo].[DimCustomer] ( [MaritalStatus] ASC, [Gender] ASC, [NumberChildrenAtHome] ASC, [TotalChildren] ASC ) INCLUDE ( [Title], [FirstName], [MiddleName], [LastName])
然后我们运行最上面的查询语句得到如下执行计划:
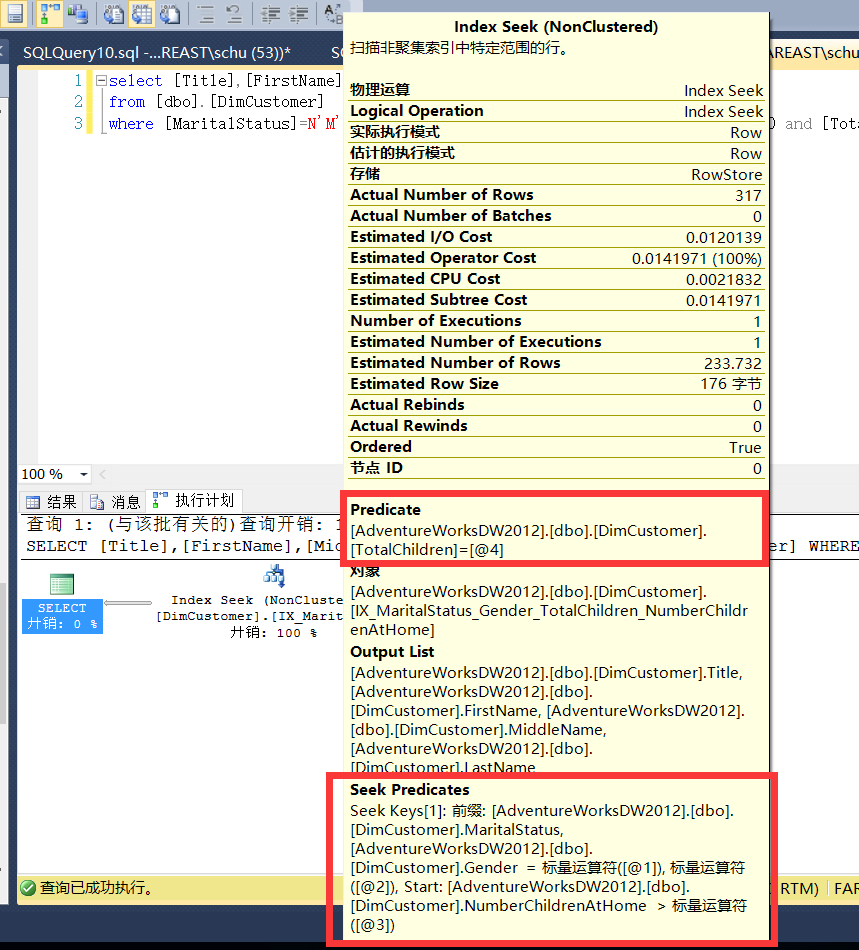
我们可以看到该执行计划中,出现了Index Seek的步骤,并且正是我们创建的索引[IX_MaritalStatus_Gender_TotalChildren_NumberChildrenAtHome],在Index Seek有两个非常重要的部分,上图中用红线标出,一个是Seek Predicates,另一个是Predicate。Seek Predicates是索引中对性能提升最大的因素,因为SqlServer会使用Seek Predicates中出现的列直接去索引B树上做快速查找,也就是Seek Predicates所包含的列越多那么对整个查询性能的提升就越大,当SqlServer通过Seek Predicates中的列筛选出数据后,会用Predicate中的列在此基础上做二次筛选,所以Predicate实际上是在Seek Predicates筛选后的数据上再做筛选。
所以我们知道了在Index Seek中Seek Predicates中出现的列越多,那么对查询性能的提升就会越大,那么问题是如何让执行计划将尽可能多的列放入Seek Predicates中呢?答案就是在Sql语句的where条件中的列,必须是索引列中第一列的相邻顺序列。
那这是什么意思呢?拿本例建立的索引[IX_MaritalStatus_Gender_TotalChildren_NumberChildrenAtHome]来说,那么4个索引列按从左到右的顺序是
[MaritalStatus] , [Gender] , [NumberChildrenAtHome] , [TotalChildren]
- 那么在Select查询的where条件中就必须出现[MaritalStatus] 列,因为[MaritalStatus]是索引的第一个索引列(索引中的第一索引列相当重要,它包含了索引的统计信息,详细信息可以查阅相关文档),所以它必须出现在Where条件中,这时Seek Predicates中就会包含列[MaritalStatus]了。
- 接下来如果你想要Seek Predicates中包含更多的列那么[Gender]列必须也要出现在Where条件中([Gender]在Where条件中的顺序不重要,但是[MaritalStatus]和[Gender]必须都出现在Where条件中),因为在索引中从左到右相邻[MaritalStatus]的列就是[Gender]列,所以这时Seek Predicates就会包含[MaritalStatus]和[Gender]列。
- 如果你想要Seek Predicates中再包含更多的列,那么就该轮到[NumberChildrenAtHome]出现在Where条件中了,原因是在索引中相邻[MaritalStatus]和[Gender]的列是[NumberChildrenAtHome],所以当[NumberChildrenAtHome]列也出现在Where条件之后,Seek Predicates就会包含[MaritalStatus],[Gender]和[NumberChildrenAtHome]列。
- 如果你还想要Seek Predicates中包含更多的列,那么最后就该轮到 [TotalChildren]出现在Where条件中了,原因是在索引中相邻[MaritalStatus],[Gender],[NumberChildrenAtHome]的列只剩下了 [TotalChildren],所以当 [TotalChildren]也出现在Where条件之后,不出意外的话(后面会解释为什么会有意外情况),Seek Predicates就会包含[MaritalStatus],[Gender],[NumberChildrenAtHome]和 [TotalChildren]这四列。
那么执行本文最上面的查询语句看看,结果和我们上面说的是否一致。查看执行计划的Index Seek步骤,我们惊讶的发现尽管[MaritalStatus],[Gender],[NumberChildrenAtHome]列和我们上面说的一样出现在了Seek Predicates中,但是最后一个索引列[TotalChildren]却出现在了Predicate中,这是因为我们对[NumberChildrenAtHome]列使用了范围性条件([NumberChildrenAtHome]>0),所以SqlServer判定查找[NumberChildrenAtHome]列的值时,会查找多个关于[NumberChildrenAtHome]列的B树节点,所以在Seek Predicates中的列就只能到[NumberChildrenAtHome]了,最后的索引列[TotalChildren]只能放在Predicate中进行二次筛选。

所以我们在这里总结下,由于索引[IX_MaritalStatus_Gender_TotalChildren_NumberChildrenAtHome]的索引列的顺序依次是
[MaritalStatus] , [Gender] , [NumberChildrenAtHome] , [TotalChildren]
所以要让上面四列出现在Index Seek步骤的Seek Predicates中,必须让Sql语句的Where条件列是如下几种组合之一
[MaritalStatus] 此时出现在Seek Predicates中的列为[MaritalStatus]
[MaritalStatus] , [Gender] 此时出现在Seek Predicates中的列为[MaritalStatus] , [Gender]
[MaritalStatus] , [Gender] , [NumberChildrenAtHome] 此时出现在Seek Predicates中的列为[MaritalStatus] , [Gender] , [NumberChildrenAtHome]
[MaritalStatus] , [Gender] , [NumberChildrenAtHome] , [TotalChildren] 此时出现在Seek Predicates中的列为[MaritalStatus] , [Gender] , [NumberChildrenAtHome](由于[NumberChildrenAtHome]列使用了范围性条件,导致SqlServer会在B树中查找[NumberChildrenAtHome]列的多个节点,所以[NumberChildrenAtHome]之后的索引列[TotalChildren],最终被查询优化器判定为无法出现在Seek Predicates中,只能在Predicate中进行二次筛选)
除此之外的任何情况都会导致Seek Predicates中不包含预期的索引列,例如如果我们只在Where中包含[MaritalStatus]列和 [NumberChildrenAtHome]列
select [Title],[FirstName],[MiddleName],[LastName] from [dbo].[DimCustomer] where [MaritalStatus]=N'M' and [NumberChildrenAtHome]>0
那么我们会发现Index Seek步骤的Seek Predicates中只包含了[MaritalStatus],因为按照[MaritalStatus] , [Gender] , [NumberChildrenAtHome] , [TotalChildren]从左到右的顺序只有列[MaritalStatus]能匹配上,而 [NumberChildrenAtHome]列前面的[Gender]没有出现在Where条件中,所以[NumberChildrenAtHome]被放到了Predicate中。
又如下面的语句,Where中只包含了[Gender]和[NumberChildrenAtHome]列
select [Title],[FirstName],[MiddleName],[LastName] from [dbo].[DimCustomer] where [Gender]=N'F' and [NumberChildrenAtHome]>0
最后执行计划中的Index Seek步骤中的Seek Predicates没有包含任何列,因为按照[MaritalStatus] , [Gender] , [NumberChildrenAtHome] , [TotalChildren]从左到右的顺序,在[Gender]和[NumberChildrenAtHome]列之前有[MaritalStatus]列,但是[MaritalStatus]列并没有出现在上面Sql语句的Where条件当中,所以[Gender]和[NumberChildrenAtHome]列都不符合Seek Predicates的匹配规则,最终都被放到了Predicate中。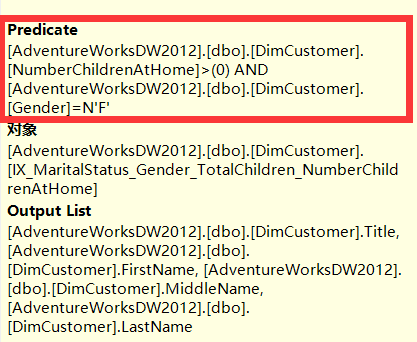
SqlServer执行计划中Index Seek步骤的匹配规则非常复杂,索引会不会被命中(Index Seek)及Seek Predicates中是否是预期的列,还和Sql语句中Where条件的写法有关,例如Where条件中如果有索引列用到了Sql函数那么索引命中的概率就会大大降低。本文只是对本人当前了解到的情况做了一些归纳和总结,如果后面发现了更多的奥秘,我会接着写新的文章来分享。