有表t_lock:
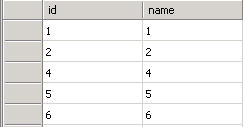
ID是主键,表中有5行数据,1~2,4~6
可重复读:
begin tran
select * from t_lock where id between 1 and 6
执行这个查询后,会在表ID为1,2,4,5,6的行上加上共享锁(s)
执行插入语句
执行成功,原因是插入的是ID为3的数据行并加上排他锁(x),插入语句不会去1,2,4,5,6行申请排它锁,否则就发生阻塞了
序列化:
begin tran
select * from t_lock where id between 1 and 6
根据序列化级别的定义执行查询后会在ID为1~6的范围上RangeS-S范围共享锁,虽然ID为3的行在数据库并不存在,但是由于这里在ID为1~6加上的是范围锁,所以实际上ID为3的行也被加上了RangeS-S锁,一定要记住范围锁是连续的范围,并不因为数据库里数据不存在就不加锁,比如你可以同样执行插入ID为3的sql语句:
结果发生了阻塞,原因就是ID为1~6的行(不管是否存在)都被加上了范围为共享锁,在这个范围除了查询什么也做不了,而上面的插入语句要对ID为3的数据行申请排它锁,肯定会被阻塞.
序列化的小陷阱:
按道理来说执行了以下sql:
begin tran
select * from t_lock where id between 1 and 6
然后插入ID大于6和ID小于1的数据行应该不会被阻塞,因为插入数据的ID位于1~6的范围之外了,可是你可以试着执行以下插入语句:
insert into t_lock values(-1,'-1')
无论是插入ID为-1的行还是ID为9的行都被阻塞,这是为什么?明明插入数据的ID在范围之外啊?
让我们更改数据库中的数据,再来看看两种情况就明白了
首先如果在事务中使用序列化查询后,数据库里的数据是这样:

执行insert into t_lock values(9,'9')不会阻塞
但是执行insert into t_lock values(-1,'-1')会被阻塞
如果在事务中使用序列化查询后,数据库里的数据是这样:
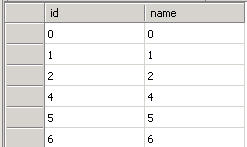
执行insert into t_lock values(-1,'-1')不会阻塞
但是执行insert into t_lock values(9,'9')会被阻塞
如果在事务中使用序列化查询后,数据库里的数据是这样:
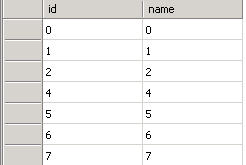
执行insert into t_lock values(-1,'-1')或insert into t_lock values(9,'9')都不会被阻塞
看出点眉目来了吗?
原来SqlServer在对行加范围锁的时候会先去探测数据库中加锁范围外是否还有其他数据行,如果没有,会对加锁范围外的其它行也加上范围锁,比如本文中范围锁会对ID为1~6的数据行加范围锁,它会先去查看数据库中是否存在ID小于1的数据行,如果不存在它会将ID小于1和ID为1~6的行全加上范围锁,同样它也会去看数据库中是否有ID大于6的数据行,如果没有它会将ID大于6和ID为1~6的行全加上范围锁
- 所以在最后一个图中因为SqlServer发现数据库中既有ID小于1的数据行(ID=0)也有ID大于6的数据行(ID=7),所以只在ID为1~6的范围上加范围锁,所以执行insert into t_lock values(-1,'-1')或insert into t_lock values(9,'9')都不会被阻塞
- 倒数第二个图的情况是SqlServer在数据库中只发现了有小于1的数据行(ID=0),所以将ID大于1的行都加上了范围锁,执行insert into t_lock values(9,'9')被阻塞
- 倒数第三个图的情况是SqlServer在数据库中只发现了有大于6的数据行(ID=7),所以将ID小于6的行都加上了范围锁,执行insert into t_lock values(-1,'-1')被阻塞