目录
在pandas中针对字符串配备了一套方法,使其容易对数组的每个元素进行操作。
1.字符串调用属性:str
# 通过str属性操作,会自动排除丢失NaN值
import numpy as np
import pandas as pd
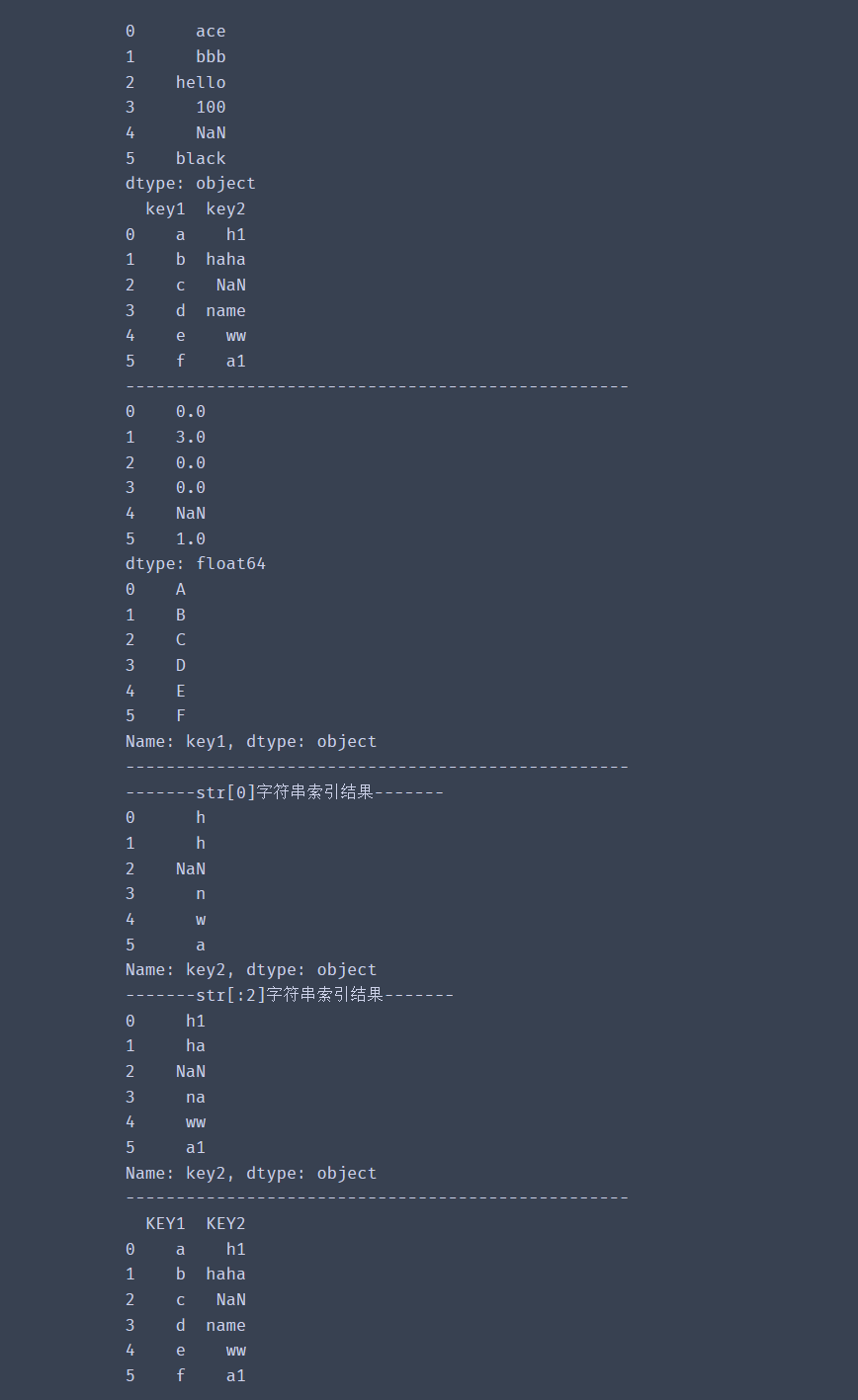
s = pd.Series(['ace','bbb','hello','100',np.nan,'black'])
df = pd.DataFrame({'key1':list('abcdef'),
'key2':['h1','haha',np.nan,'name','ww','a1']
})
print(s)
print(df)
print('-' * 50)
print(s.str.count('b')) # 统计每个字符串中含有b字母的数量
print(df['key1'].str.upper()) # 将字符串转化为大写
print('-' * 50)
# 字符串索引
print('-------str[0]字符串索引结果-------')
print(df['key2'].str[0]) # 取第一个字符
print('-------str[:2]字符串索引结果-------')
print(df['key2'].str[:2]) # 取前2个字符
print('-' * 50)
# df.columns可以直接使用str属性,并且df.columns返回的对象可以直接使用list或者tolist()转化为字典.
df.columns = df.columns.str.upper()
print(df)
输出结果:
2.字符串常用方法:lower,upper,len,startswith,endswith
- lower:字母转化为小写
- upper:字母转化为大写
- len:求每个字符串的长度
- startswith:判断起始是否为某个指定字母
- endswith:判断结束是否为某个指定字母
import pandas as pd
s = pd.Series(['A','bd','110',np.nan,'123','hello','wd'])
print(s.str.lower(),'------全部小写
')
print(s.str.upper(),'------全部大写
')
print(s.str.len(),'------求每个字符串的长度
')
print(s.str.startswith('h'),'------判断起始是否为h
')
print(s.str.endswith('d'),'------判断结束是否为d
')

3.字符串去空格:strip,rstrip,lstrip
- strip:去除字符串两边的空格
- rstrip:去除字符串左边的空格
- lstrip:去除字符串右边的空格
import pandas as pd
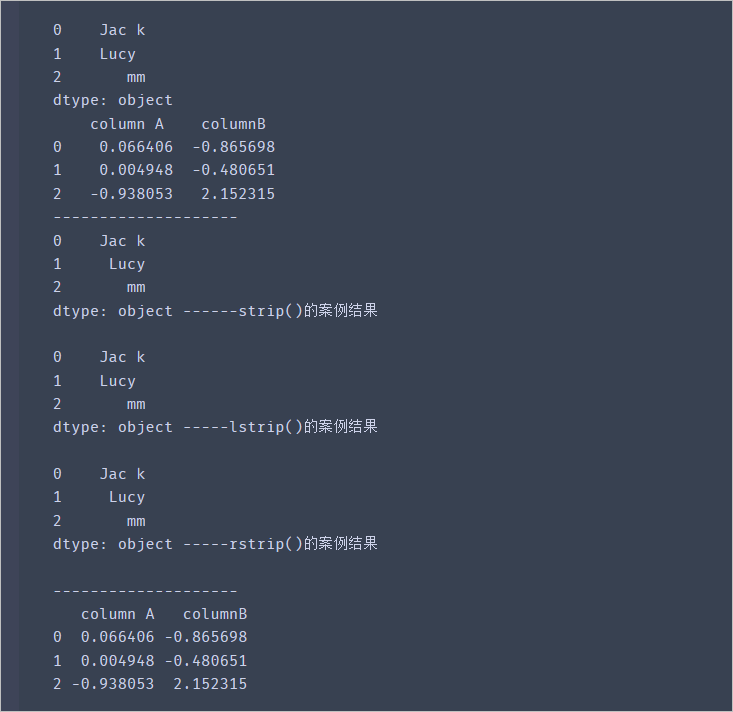
s = pd.Series(['Jac k ','Lucy ',' mm '])
df = pd.DataFrame(np.random.randn(3,2),columns=[' column A ',' columnB '],
index=range(3))
print(s)
print(df)
print('--------------------')
print(s.str.strip(),"------strip()的案例结果
") # 去除字符串两边的空格
print(s.str.lstrip(),"-----lstrip()的案例结果
") # 去除字符串左边的空格
print(s.str.rstrip(),"-----rstrip()的案例结果
") # 去除字符串右边的空格
print('--------------------')
df.columns = df.columns.str.strip() # 去掉列名两边的空格,中间的空格没去掉
print(df)
输出结果:
4.替换:replace
# 替换replace
import pandas as pd
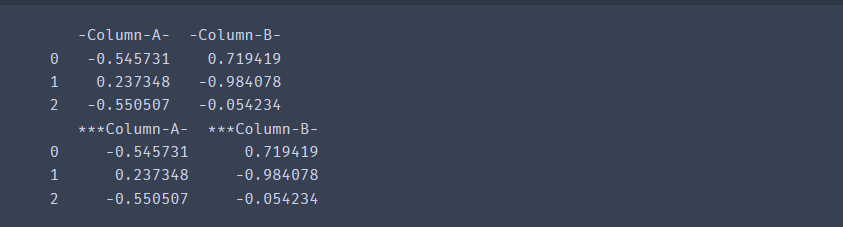
df = pd.DataFrame(np.random.randn(3, 2), columns=[' Column A ', ' Column B '],
index=range(3))
df.columns = df.columns.str.replace(' ','-')
print(df)
# 替换
df.columns = df.columns.str.replace('-','***',n=1) # n:替换个数
print(df)
输出结果:
5.字符串分割:split,rspilt
- split:根据指定的分隔符对字符串进行分割
- rsplit:类似于split,反向工作,即从字符串的末尾到字符串的开头
import pandas as pd
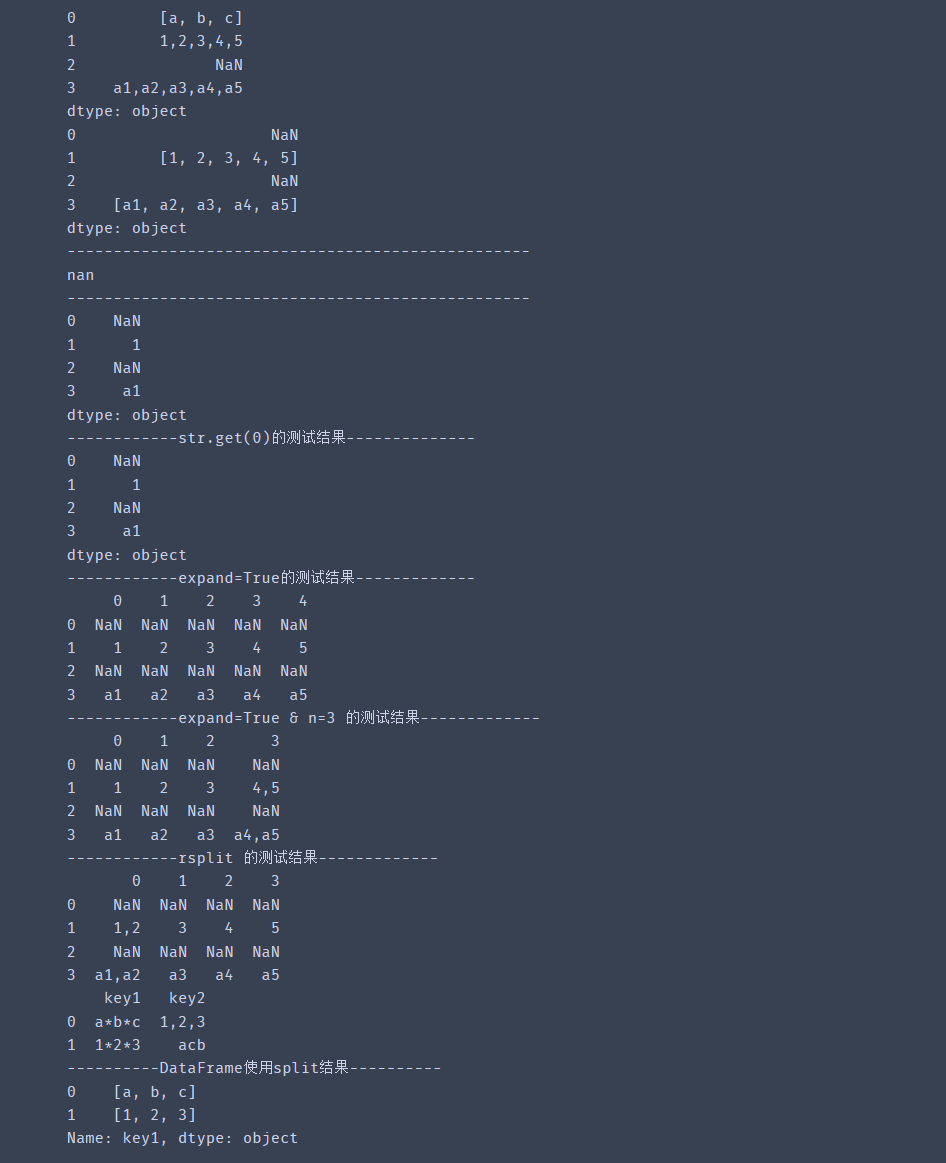
s = pd.Series([['a','b','c'],'1,2,3,4,5',np.nan,'a1,a2,a3,a4,a5'])
print(s)
print(s.str.split(',')) # 分割
print('-' * 50 )
# 获取分割后的第一个list
print(s.str.split(',')[0])
print('-' * 50 )
#使用get或[]符号访问拆分列表中的元素
print(s.str.split(',').str[0])
print('------------str.get(0)的测试结果--------------')
print(s.str.split(',').str.get(0))
print('------------expand=True的测试结果-------------' )
print(s.str.split(',',expand=True))
print('------------expand=True & n=3 的测试结果-------------' )
print(s.str.split(',',expand=True,n=3)) # n参数限制分割数,n=3表示对前3列分割,后面的全部作为一列
print('------------rsplit 的测试结果-------------' )
print(s.str.rsplit(',',expand=True,n=3)) # rsplit类似于split,反向工作,即从字符串的末尾到字符串的开头
# DataFrame使用字符分割
df = pd.DataFrame({'key1':['a*b*c','1*2*3'],
'key2':['1,2,3','acb']})
print(df)
print('----------DataFrame使用split结果----------')
# 对key2列使用split
print(df['key1'].str.split('*'))