一、接口与归一化设计
Java接口是一系列方法的声明,是一些方法特征的集合,一个接口只有方法的特征没有方法的实现,因此这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的行为(功能)。
由于python中没有Interface方法,根据Java接口的定义,可以抽象出python中的接口:一个类所具有的方法的特征集合。
可以通过继承来实现接口方法,在python中,继承有两种用途:
- 继承基类的方法,并且做出自己的改变或者扩展(代码重用)
- 声明某个子类兼容于某基类,定义一个接口类Interface,接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子类继承接口类,并且实现接口中的功能
1 class Interface:#定义接口Interface类来模仿接口的概念,python中压根就没有interface关键字来定义一个接口。
2 def read(self): #定接口函数read,不实现功能
3 pass
4
5 def write(self): #定义接口函数write,不实现功能
6 pass
7
8
9 class Text(Interface): #文本,具体实现read和write
10 def read(self):
11 print('文本数据的读方法')
12
13 def write(self):
14 print('文本数据的写方法')
15
16 class Sata(Interface): #磁盘,具体实现read和write
17 def read(self):
18 print('硬盘数据的读方法')
19
20 def write(self):
21 print('硬盘数据的写方法')
22
23 class Process(Interface):
24 def read(self):
25 print('进程数据的读方法')
26
27 def write(self):
28 print('进程数据的写方法')
实践中,继承的第一种含义意义并不很大,甚至常常是有害的。因为它使得子类与基类出现强耦合。
继承的第二种含义非常重要。它又叫“接口继承”。
接口继承实质上是要求“做出一个良好的抽象,这个抽象规定了一个兼容接口,使得外部调用者无需关心具体细节,可一视同仁的处理实现了特定接口的所有对象”——这在程序设计上,叫做归一化。
归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合——就好象linux的泛文件概念一样,所有东西都可以当文件处理,不必关心它是内存、磁盘、网络还是屏幕(当然,对底层设计者,当然也可以区分出“字符设备”和“块设备”,然后做出针对性的设计:细致到什么程度,视需求而定)。
在python中根本就没有一个叫做interface的关键字,上面的代码只是看起来像接口,其实并没有起到接口的作用,子类完全可以不用去实现接口 ,如果非要去模仿接口的概念,可以借助第三方模块:
http://pypi.python.org/pypi/zope.interface
twisted的twistedinternetinterface.py里使用zope.interface
文档https://zopeinterface.readthedocs.io/en/latest/
设计模式:https://github.com/faif/python-patterns
二、抽象类
与java一样,python也有抽象类的概念但是同样需要借助模块实现,抽象类是一个特殊的类,它的特殊之处在于只能被继承,不能被实例化。
如果说类是从一堆对象中抽取相同的内容而来的,那么抽象类就是从一堆类中抽取相同的内容而来的,内容包括数据属性和函数属性。
比如我们有香蕉的类,有苹果的类,有桃子的类,从这些类抽取相同的内容就是水果这个抽象的类,你吃水果时,要么是吃一个具体的香蕉,要么是吃一个具体的桃子……你永远无法吃到一个叫做水果的东西。
从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。
从实现角度来看,抽象类与普通类的不同之处在于:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。
1 #_*_coding:utf-8_*_
2 __author__ = 'Linhaifeng'
3 #一切皆文件
4 import abc #利用abc模块实现抽象类
5
6 class All_file(metaclass=abc.ABCMeta):
7 all_type='file'
8 @abc.abstractmethod #定义抽象方法,无需实现功能
9 def read(self):
10 '子类必须定义读功能'
11 pass
12
13 @abc.abstractmethod #定义抽象方法,无需实现功能
14 def write(self):
15 '子类必须定义写功能'
16 pass
17
18 # class Text(All_file):
19 # pass
20 #
21 # t1=Text() #报错,子类没有定义抽象方法
22
23 class Text(All_file): #子类继承抽象类,但是必须定义read和write方法
24 def read(self):
25 print('文本数据的读取方法')
26
27 def write(self):
28 print('文本数据的读取方法')
29
30 class Sata(All_file): #子类继承抽象类,但是必须定义read和write方法
31 def read(self):
32 print('硬盘数据的读取方法')
33
34 def write(self):
35 print('硬盘数据的读取方法')
36
37 class Process(All_file): #子类继承抽象类,但是必须定义read和write方法
38 def read(self):
39 print('进程数据的读取方法')
40
41 def write(self):
42 print('进程数据的读取方法')
43
44 wenbenwenjian=Text()
45
46 yingpanwenjian=Sata()
47
48 jinchengwenjian=Process()
49
50 #这样大家都是被归一化了,也就是一切皆文件的思想
51 wenbenwenjian.read()
52 yingpanwenjian.write()
53 jinchengwenjian.read()
54
55 print(wenbenwenjian.all_type)
56 print(yingpanwenjian.all_type)
57 print(jinchengwenjian.all_type)
抽象类的本质还是类,指的是一组类的相似性,包括数据属性(如all_type)和函数属性(如read、write),而接口只强调函数属性的相似性。
抽象类是一个介于类和接口之间的一个概念,同时具备类和接口的部分特性,可以用来实现归一化设计。
三、继承顺序
python的类可以继承多个类,Java和C#中则只能继承一个类
python的类如果继承了多个类,那么其寻找方法的方式有两种:深度优先和广度优先
- 当类是经典类时,多继承情况下,深度优先
- 当类是新式类时,多继承情况下,广度优先
1 #在python2中,区分新式类和经典类
2 class C1(object): #当前类或者父类继承了‘object’类,该类为新式类
3 pass
4
5 class C2(C1): #父类是新式类,子类也是新式类
6 pass
7
8
9 class C3: #经典类,未继承'object'类
10 pass
11
12 class C4(C3): #父类是经典类,子类也是经典类
13 pass
14
15
16 #在python3中,不区分新式类和经典类,所有类都是新式类,默认继承‘object’类
17 class C5:
18 pass
19
20 class C6(object):
21 pass
继承顺序实例:
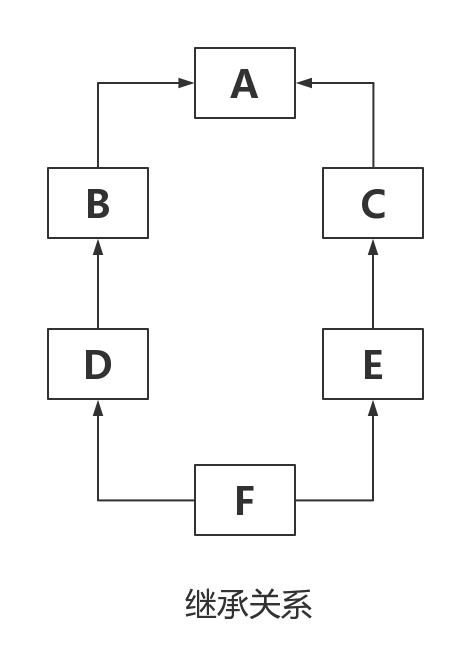


1 class A(object):
2 def test(self):
3 print('from A')
4
5 class B(A):
6 def test(self):
7 print('from B')
8
9 class C(A):
10 def test(self):
11 print('from C')
12
13 class D(B):
14 def test(self):
15 print('from D')
16
17 class E(C):
18 def test(self):
19 print('from E')
20
21 class F(D,E):
22 # def test(self):
23 # print('from F')
24 pass
25 f1=F()
26 f1.test()
27 print(F.__mro__) #只有新式类才有这个属性可以查看线性列表,经典类没有这个属性
28
29 #新式类继承顺序:F->D->B->E->C->A
30 #经典类继承顺序:F->D->B->A->E->C
31 #python3中统一都是新式类
32 #pyhon2中才分新式类与经典类
继承原理:
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如:
>>> F.mro() #等同于F.__mro__
[<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
- 子类会先于父类被检查
- 多个父类会根据它们在列表中的顺序被检查
- 如果对下一个类存在两个合法的选择,选择第一个父类
四、子类调用父类
子类继承了父类的方法,然后想进行修改,注意了是基于原有的基础上修改,那么就需要在子类中调用父类的方法
方法一:父类名.父类方法()
1 class A:
2 def __init__(self, name, age):
3 self.name = name
4 self.age = age
5
6 def test(self):
7 print('test function')
8
9 class B(A): #新建类B继承类A,类A中的属性全部被类B继承
10 def __init__(self, name, age, country):
11 A.__init__(self, name, age) #引用父类的属性
12 self.country = country #增加自身独有的属性
13
14 def test(self):
15 print('test function B')
16 pass
17
18 b1 = B('jack', 21, 'China') #类B的实例可引用父类B的属性,如果有重名属性,以自身类的属性优先
19 print(b1.name)
20 print(b1.age)
21 print(b1.country)
22 b1.test()
23
24 #运行结果
25 #jack
26 #21
27 #China
28 #test function B
方法二:super()
1 #super的用法:只能在新式类中使用
2 #python3中:
3 class People:
4 def __init__(self, name, sex, age):
5 self.name = name
6 self.sex = sex
7 self.age = age
8
9 def walk(self):
10 print('%s is walking' %self.name)
11
12 class Chinese(People):
13 country = 'China'
14 def __init__(self, name, sex, age, language = 'Chinese'):
15 super().__init__(name, sex, age) #super().
16 self.language = language
17 def walk(self,x):
18 super().walk() #super().
19 print('subclass: %s' % x)
20
21 c = Chinese('egon', 'male', 18)
22 print(c.name, c.sex, c.age, c.language)
23 c.walk('walk')
24
25 #python2中:
26 class People(object):
27 def __init__(self, name, sex, age):
28 self.name = name
29 self.sex = sex
30 self.age = age
31
32 def walk(self):
33 print('%s is walking' %self.name)
34
35 class Chinese(People):
36 country = 'China'
37 def __init__(self, name, sex, age, language = 'Chinese'):
38 super(Chinese, self).__init__(name, sex, age) #super(当前类名,self)
39 self.language = language
40 def walk(self,x):
41 super(Chinese, self).walk() #super(当前类名,self)
42 print('subclass: %s' % x)
43
44 c = Chinese('egon', 'male', 18)
45 print c.name, c.sex, c.age, c.language
46 c.walk('walk')
当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用一次(注意注意注意:使用super调用的所有属性,都是从MRO列表当前的位置往后找,千万不要通过看代码去找继承关系,一定要看MRO列表)
五、多态与多态性
1. 多态指的是一类事物有多种形态,(一个抽象类有多个子类,因而多态的概念依赖于继承)。——类的定义阶段
- 序列类型有多种形态:字符串,列表,元组。
- 动物有多种形态:人,狗,猪
- 文件有多种形态:文本文件,可执行文件
2. 多态性是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用不同内容的函数。——类的调用阶段
在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息,不同的对象在接收时会产生不同的行为(即方法)。也就是说,每个对象可以用自己的方式去响应共同的消息。所谓消息,就是调用函数,不同的行为就是指不同的实现,即执行不同的函数。
3. 多态性的好处
- 增加了程序的灵活性,以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal)
- 增加了程序的可扩展性,通过继承animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用
实例1:
1 import abc
2 class Animal(metaclass=abc.ABCMeta): #同一类事物:动物
3 @abc.abstractmethod
4 def talk(self):
5 pass
6
7 class People(Animal): #动物的形态之一:人
8 def talk(self):
9 print('say hello')
10
11 class Dog(Animal): #动物的形态之二:狗
12 def talk(self):
13 print('say wangwang')
14
15 class Pig(Animal): #动物的形态之三:猪
16 def talk(self):
17 print('say aoao')
18 #------------------------------------------------------------------------------------------
19 >>> def func(animal): #参数animal就是对态性的体现
20 ... animal.talk()
21 ...
22 >>> people1=People() #产生一个人的对象
23 >>> pig1=Pig() #产生一个猪的对象
24 >>> dog1=Dog() #产生一个狗的对象
25 >>> func(people1)
26 say hello
27 >>> func(pig1)
28 say aoao
29 >>> func(dog1)
30 say wangwang
接着创建Cat类,继承Animal类,func方法的调用不需要任何修改
1 >>> class Cat(Animal): #属于动物的另外一种形态:猫
2 ... def talk(self):
3 ... print('say miao')
4 ...
5 >>> def func(animal): #对于使用者来说,自己的代码根本无需改动
6 ... animal.talk()
7 ...
8 >>> cat1=Cat() #实例出一只猫
9 >>> func(cat1) #甚至连调用方式也无需改变,就能调用猫的talk功能
10 say miao
11
12 '''
13 这样我们新增了一个形态Cat,由Cat类产生的实例cat1,使用者可以在完全不需要修改自己代码的情况下。使用和人、狗、猪一样的方式调用cat1的talk方法,即func(cat1)
14 '''
参考资料:
1. http://www.cnblogs.com/linhaifeng/articles/6182264.html#_label10