——深度学习的建模、调参思路整合。
写在前面
最近偶尔从师兄那里获取到了吴恩达教授的新书《Machine Learning Yearing》(手稿),该书主要分享了神经网络建模、训练、调节参数时所需要的一些技巧和经验。我在之前的一些深度学习项目中也遇到过模型优化,参数调节之类的问题,由于当时缺少系统化的解决方案,仅仅依靠感觉瞎蒙乱碰。虽然有时也能获得效果不错的网络模型,但对于该模型是否已到达最佳性能、该模型是否能适配更泛化的数据等问题心理没底。通过阅读这本教材,对于数据集的获取、划分;训练模型的评分标准;在模型训练时需要调节哪些参数等有了更加具体、科学的认知。而这些经验在具体的工程应用中弥足珍贵,这里我将学习的一些内容做笔记整理下来。
书籍可以在其官网上进行查看:http://www.mlyearning.org/ (需连接国际互联网)
也有学者对其进行了翻译:https://xiaqunfeng.gitbooks.io/machine-learning-yearning/content/
本书一共由以下11个大的章节组成:
一. Introduction:
包括chapter 1-4,主要介绍了包括这本书的写作目的与使用方式。
二. Setting up development and test sets:
包括 chapter 5-12,主要介绍了数据集的获取及划分,衡量标准的制定,模型算法的训练、调试流程。
三. Basic Error Analysis:
包括 chapter 13-19,主要介绍了错误分析(Error Analysis)的定义,以及如何使用错误分析来为模型训练调试指明方向。
四. Bias and Variance:
包括 chapter 20-27,主要介绍了两种主要的错误来源bias & variance,以及针对不同错误来源的模型优化策略。
五. Learning curves:
包括 chapter 28-32,主要介绍学习曲线(learning curve)的定义与绘制,以及如何使用它来判断当前模型所处的状态。
六. Comparing to human-level performance:
包括 chapter 33-35,主要介绍使用人类的识别能力作为模型算法目标对比的原因及方法。
七. Training and testing on different distributions:
包括 chapter 36-43, 主要介绍在使用不同来源数据做训练时的一些技巧。
八. Debugging inference algorithms:
包括 chapter 44-46,讲解了一些在复杂建模情况下的调试方法。
九. End-to-end deep learning:
包括 chapter 47-52,主要介绍最近兴起的直接学习(end-to-end learning)及其应用场景,并与分步学习的思路进行比较。
十. Error analysis by parts:
包括 chapter 53-57,介绍了如何对机器学习“管道”中的组件进行验证,判断其是否有性能提升的空间。
十一. Conclusion
第一章(Introduction)笔记:
·常规的神经网络模型优化思路(包括但不限于):
1.获取更多训练数据;
2.获取更多种类的训练数据(如图像识别任务中,获取不同角度的目标物体图片);
3.训练更长时间、更多轮次;
4.扩大模型结构(更多神经元,更深的网络);
5.缩小模型结构;
6.使用正则化(regularization);
7.改变网络结构(改变激活函数,参数传播路径设计等)。
第二章(Setting up development and test sets)笔记
·Train set、dev set、test set的定义及使用:
Training set——训练集,对算法模型进行训练的数据集。
Dev set(development set)——开发集,使用该数据集来调节参数,即在使用Training set对模型进行训练后,根据模型在Dev set上展现出来的效果进行深入分析,制定模型参数的调整方向,调整训练策略。
Test set——测试集,根据模型在这个数据集上的表现,来对模型进行评分。注意不要使用这个数据集反映出来的问题来确定训练策略。
·数据来源:
Training set的数据来源限制不是很强,但Dev set 和 Test set的数据一定要贴近实际目标。例如在一个人脸识别项目中,为了扩充训练集的样本数目,可以将手工素描的人像作品作为样本加入Training set,但不要将素描作品加入Dev set 和Test set,应使用真实环境的照片来作为Dev set 和Test set中的样本,因为其更贴近我们模型的真实使用环境。
·数据集的大小:
Dev set的大小没有硬性规定,一般只要求能反映出算法的实际效果即可。如果一个广告推荐算法能将点击率提高0.1%,那么由100个样本所组成的Dev set必定反映不出这种增长。一般来讲,dev set包含1000~10000个样本。
Test set的规模应该足够大,以能产生可信的模型评分为标准。传统的机器学习实践中经常以70%/30%的比例来分割训练集、测试集,但是在现在数据量激增的背景下,该分割方法的适用性并不强,应该具体事例具体分析。
·项目实施流程:
深度学习的项目分为三个步骤,想法(建模思路、样本获取等)→编码→实验。之后根据实验的结果来对想法进行调整,修改代码继续实验。整个工作流程形成一个闭合的环状。
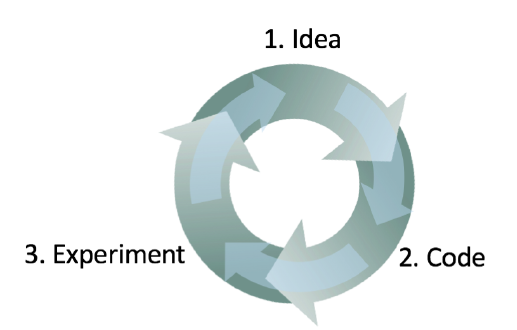
其中,在实验步骤之后,根据Dev set所展现出来的结果,来对模型进行调整,即整个工作流程的展开都是以优化模型在Dev set上面的表现为目标。这有可能导致模型对Dev set过拟合,判断其过拟合的方法为:模型在Dev set上表现良好,而在Test set上表现不佳。一般可以使用增加Dev set的样本数目来对过拟合现象进行纠正。
·单一标准评价体系:
在评定模型效果的时候使用单一标准的评分。很多时候多个模型在不同的方面各有优劣,例如有的样本精确率比较高,有的样本召回率比较高。为了能更快的对这些模型进行比较,以提高我们项目实施流程循环的速度,我们需要一个单一标准的衡量体系,可以为每一项指标赋予一个权重,将其进行加权形成单一标准评价体系。
多标准评价矩阵:
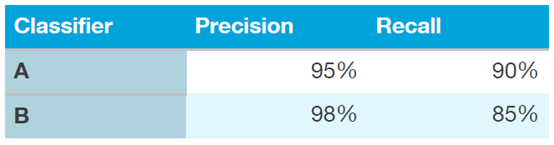
单一标准评价矩阵(Single-number evaluation metric):

当然,在感觉这个单一评价矩阵的权重分配不合适的时候,可以在项目组内部进行讨论,来对各指标的权重进行修改。
·过拟合,数据分布不一致,衡量指标有偏差时的应对措施:
Dev set过拟合时:增加Dev set的样本数;Dev/Test set中包含的数据与所关心数据来源不一致时:获取新的Dev/Test set数据;衡量指标有偏差时:即该单一评价标准无法正确的对各指标进行衡量的时候,可以对单一评价标准的权重进行修改。
第三章(Basic Error Analysis)笔记:
·有了想法之后快速的进行实现:
不要想着一下能设计出来一个最优的建模方式、得到最好的算法模型。有了想法之后快速的上手进行实现,在动手实施项目的时候,往往会产生新的想法来帮助你寻找到更有可能的优化改进方向,之后根据这些优化方向来不断迭代,以第二章所展示的工作流程对项目进行推进,以获得更好的算法模型。
一般来讲快速实现的第一个版本需要在一周之内做出来。
·错误分析(Error Analysis):
定义:在Dev set中找出一定数量的错分样本(模型对其进行了错误的分类),对错误类型进行手动分析。(注意:错误分析仅仅针对Dev set,不要将其应用在Test set中)
目的:理解模型出错的原因,提出针对性的改进意见。
·错误统计表:
在错误分析时,列出一个统计表格以统计不同类型的错误,对错误情况有一个直观印象。如下表:
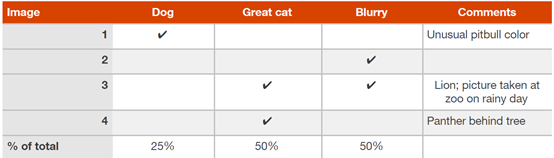
该表即猫咪图像识别项目中,对部分样本进行错误分析的统计表,注意一个错误样本可以有多个错误原因。
根据错误统计表,可以提出针对性的改进方案,如在上述猫咪图像识别任务中,有两个优化方案:
1.增加一个分类器以区分猫和狗;
2.增加一个分类器以区分宠物猫和其他大型猫科动物。
通过错误统计表,可以很容易的知道方案2将会带来更大的效果提升。
·Dev set的分割:
当Dev set过大时,可以将其进行分割以减少手工错误分析的工作量。将Dev set分割为两个部分:Eyeball dev set 和 Blackbox dev set。
Eyeball dev set(开发集-观测):即需要手动对其进行错误分析的部分。
Blackbox dev set(开发集-黑盒):即不需要手动进行错误分析的部分,只对其错误率进行统计。
用法:使用Eyeball dev set 进行手动分析,制定优化方案。将优化后的模型同时在Eyeball dev set和Blackbox dev set上进行应用,如两者效果相当,则优化成功;如优化后模型在Eyeball dev set上的表现明显优于blackbox dev set,则说明该优化方案对Eyeball dev set 过拟合,此时需要对eyeball dev set进行修改,可以重新划分或通过对其增加样本的方式进行。
·Eyeball dev set的大小:
一般来讲,手动错误分析需要有足够的错误样本,例如:当Eyeball dev set中仅有10个错误样本的话,你无法准确的评判各种错误类型所占的比例。一般要求Eyeball dev set中含有50个以上的错误样本,100个为佳。因此:
![]()
如一个模型的分类准确率为90%,要求Eyeball dev set中具有100个错误样本,即Eyeball dev set 中需要100/(1-90%)=1000个样本。在Dev set规模不大的时候,将Dev set整个作为Eyeball dev set也是可行的,即手动分析Dev set中的所有错误样本。
第四章(Bias and Variance)笔记:
·Bias 和 Variance的定义:
(注:直接将Bias和Variance翻译为偏差和方差不能准确的表明其在本书中的含义,这里直接使用其英文名称了。)
Bias:测试集(Training set)的错误率。
Variance:开发集(Dev set)的错误率减去Bias,即模型在Dev set上的表现比其在Training set上表现更差的程度。
Avoidable bias:表示可以优化的bias,使用Bias减去最优情况下的错误率得到。如一个语音识别的项目中,部分样本有杂音,人类识别的错误率为14%,可定义最优情况的错误率为14%,模型识别错误率为15%,即bias=15%,此时Avoidable bias=15%-14%=1%。
·根据Bias 和 Variance来调整优化方向:
Bias小、Variance大:即模型对训练集过拟合。
优化策略:扩充训练样本数目,或简化模型结构,或减少训练时间。其中,扩充训练样本数目最为常用、效果最好。
例——Training set的错误率为1%,Dev set的错误率为11%,此时bias=1%,variance=10%,即bias小,variance大,可判断为对训练集过拟合。
Bias大、Variance小:即模型对训练集欠拟合。
优化策略:增加网络复杂度(可同时使用正则化或dropout,以减少增加variance的风险),改变网络结构,增加训练轮次(增长训练时间)。
例——Training set的错误率为15%,Dev set的错误率为16%,此时bias=15%,variance=1%,即模型展现出的效果不佳,判断其为欠拟合。
Bias大、Variance大:即模型在训练集合开发集上均表现不佳,其中开发集更差。
优化策略:同时使用上面的两种情况的优化策略对模型进行优化,或者通过深入分析,改变模型结构以同时减小bias 和 variance。
·减少Bias 的方法总结:
1.增加模型复杂度。
2.对Training set 进行错误分析,根据分析结果,调整输入样本的特征,尽量增加输入特征数目来使模型进行更准确的判断。
3.避免使用正则化或Dropout。正则化和Dropout的使用会增加bias,减少variance。
4.修改模型结构。
·减少Variance的方法总结:
1.增加更多训练数据。
2.增加正则化或Dropout。(该方法有可能在减少variance的同时增大bias)
3.设置训练停止阈值,即在loss减少不明显的情况下终止训练,防止训练迭代轮次过多而产生过拟合。
4.对输入样本的特征进行筛选,减少特征数目。
5.降低模型复杂度。
6.对Dev set进行错误分析,调整样本特征,可增加有利于提升模型表现的特征。
7.改变模型结构。
第五章(Learning Curves)笔记:
·学习曲线(Learning Curve):
定义:训练样本数目(训练集规模)与Dev set错误率的对应关系图像。
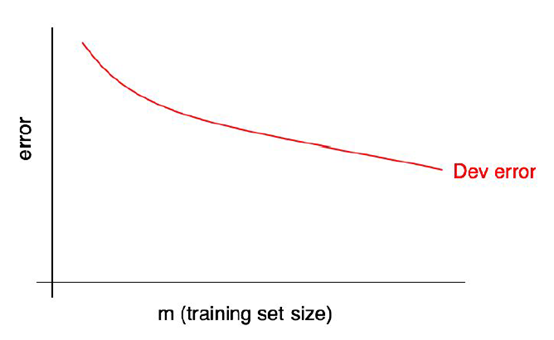
上图即一个学习曲线的示例,随着训练集的增大,Dev set的错误率不断降低。
·包含Bias和最优表现的学习曲线:
定义:在学习曲线的图表中加入模型对训练集的错误率统计(即Bias),和所期待模型达到的最优错误率,即获得该图表。
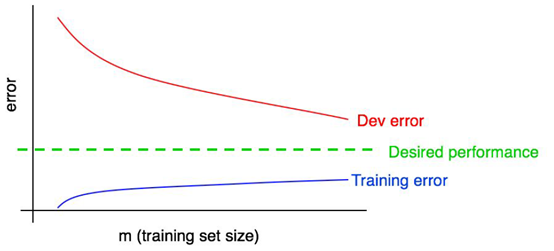
上图即一个一般情况下的学习曲线图。
下方的曲线代表模型在训练集上的误差,可以看出随着样本量的增加,训练集上的误差越来越大。这也很容易理解,当训练样本只有1个的时候,模型肯定会完全拟合,错误率为0。当样本越来越多的时候,网络就越来越难以“记忆”这些样本的特性,因此在其上的误差会越来越大,即Bias越来越大。
上方的曲线代表模型在开发集上的误差,随着训练集样本数目的增加,模型的泛化能力增强,因此模型在Dev set上的误差越来越小,最终接近我们所期待的最优效果。
中间的直线代表我们期待模型所能达到的最佳效果。它是一个固定的错误率。一般来讲,随着样本数目的增加,模型训练效果会越来越接近这条直线,但不会与之交叉,一旦越过这条直线,可以判定:①最佳效果的错误率制定有误;②模型对训练集/开发集过拟合。
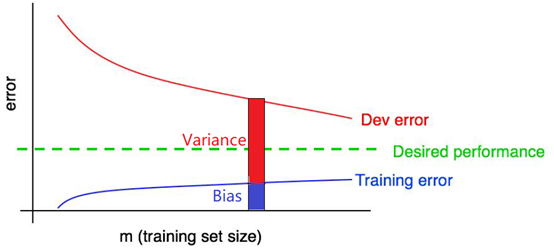
·使用学习曲线观测Bias和Variance:
根据Bias和Variance的定义,Train Error的值即为Bias,Dev Error和Train Error的差值即为Variance。
·使用学习曲线决定模型优化方向:
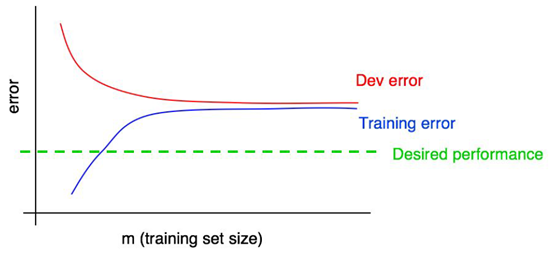
在上图这种情况下,Bias很大,Variance很小,并且两者均大于最优错误率。可以判定模型对训练集欠拟合,而且随着训练集的增大(训练样本增多),模型并没有展现出更进一步的情况。此时,需要对模型的结构进行改变,增加模型的复杂度。
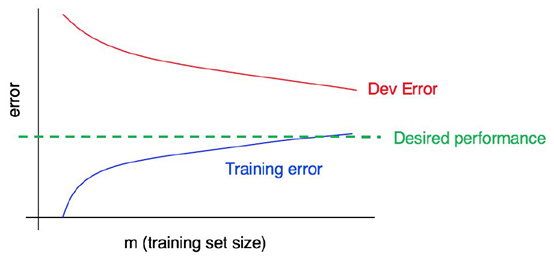
在上图这种情况下,Bias虽然比较大,但它的Avoidable Bias(即Training Error减去 Desired Performance)比较小,因此可以判定其Bias较小,Variance较大。可以使用增加训练样本的方法来降低Dev Error。
·学习曲线的弊端:
将模型在不同数量的训练集下进行训练,会消耗较大的计算量。
第六章(Comparing to human-level performance)笔记:
·定义及作用:
定义:使用人类的能力来和模型进行比对,包括错误率比对(以方便判断该算法模型是否还具有继续提升的空间),和错误分析比对(使用人类直觉以判断分析模型在哪些方面容易出问题)。
作用:获取标记样本;错误分析时作比对,找出正确改进方向;设置最优错误率(Desired error rate)。
·定义效果超出人类所达到的能力:
可以对模型分类错误的样本进行错误分析(Error Analysis),将错误进行分类,如果在某种错误类型上,人类依然拥有更加优秀的表现,那么就可以朝这个方向继续优化,以使模型达到超越人类的表现。
如:在猫咪图片识别任务中,模型与人类整体表现相当。其中,模型对模糊图像的识别效果更好,人类对大型猫科动物的区分度更高。此时可以通过优化模型对猫科动物的区分能力,以使模型的整体表现优于人类。
第七章(Training and testing on different distributions)笔记:
·使用不同来源的数据进行训练:
情境:当真实环境中的数据量不够的时候,可以将一些模拟数据、生成数据、网络上相关数据加入到训练集中进行训练。以扩展模型识别潜在特征的能力,增强泛化性,使其更好的在未来的实际应用场景中工作。
问题:由于数据来源不同,可能导致模型的效果不佳。以人脑来进行比喻,人脑的记忆空间有限,如果外部来源的数据使用过多,有可能会弱化对目标来源数据的判断。
·使用权重来调节不同来源数据所造成的影响:
具体方法是在计算损失函数的时候,加入权重,以增大真实环境数据对网络的影响。
例子:在猫咪识别任务中,假设我们有有200,000个来自互联网的样本图片,以及5000张来自真实环境(手机上传)的样本图片,其比例为40:1。
不使用权重时的损失函数计算公式(此时互联网样本和真实样本对模型的影响比例为40:1):
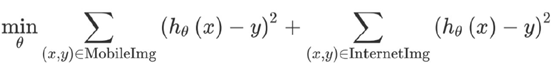
加入权重的损失函数计算公式:
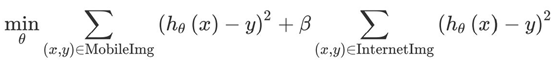
其中,β是用户设计的权重值,在上述猫咪识别的例子中,β=1/40时,可以使来自互联网的样本和真实样本对模型产生1:1的影响。
·数据不匹配误差(Data Mismatch Error):
定义:由训练集和开发集的数据来源分布不一致所造成的误差。假设训练集的数据来源是50%的互联网数据+50%的真实数据。
判定:从训练集中分出一部分,保持和训练集的数据分布相同,将其称作训练-开发集(Training dev set)。该数据集不参与模型训练,仅在训练完成之后用于和训练集、开发集的错误率进行比较。当训练集和训练-开发集的误差相似,而开发集(dev set)的误差比两者要大得多的时候,即可判定出现了数据不匹配误差(Data Mismatch Error)。
解决方法:①通过错误分析等方法判断训练样本和Dev set中样本的差异,针对这些差异性对模型进行改进。②获取更多真实数据来增加训练集中真实数据的比例。
人工数据合成:另外还有手动数据合成的方法来实现增加真实数据样本的目的。如在语音识别任务中,为清晰的语音样本(来自互联网)人为的注入噪声影响,以模拟真实数据。
第八章(Debugging inference algorithm)笔记:
本章讲解了一些在复杂建模情况下的调试方法
·映射函数:
映射函数:在某些不好直接数值化建模的情况下,我们需要一个函数将原始输入转换成一个数值或数值向量,这个函数就叫做映射函数。(书中将这个函数称为Scoring function)
例如:在语音识别任务中,我们有一个输入语音A,以及一个对应的语句字符串S。现在需要通过一个映射函数ScoreA(S)来计算出一个得分,这个得分能正确的反映字符串S与语音A的匹配程度,匹配程度越高,得分越高。
基于映射函数的AI设计模式:很多任务里面,可以使用映射函数对一个输出进行评分,之后使用相关机器学习算法来优化这个评分,使其得到最大值。
·优化验证测试(optimization verification test):
目的:在对具有映射函数的模型进行建模训练时,会面临一个问题,当训练效果不佳时,建模人员不清楚是映射函数不合理还是机器学习算法模型有误。为解决这个问题,引入优化验证测试。
方法:拿出一个错误样本,对其算法模型的输出S_out和正确样本输出S_true分别使用映射函数计算得分,如果 得分(S_out)>=得分(S_true),则说明映射函数无法正确的对这个样本的输出进行评判。抽取一些错误样本进行测试,当有相当部分的错误样本在映射函数上出了问题时,考虑更换映射函数。
第九章(End-to-end deep learning)笔记:
·机器学习“管道”(machine learning pipeline):
概念:这里的“管道”指的是机器学习的建模流程。管道左侧为输入,可以是一个语音片段,一张图片或一行文字等等;管道右侧为输出,可以是一行文字,一个识别结果或一个情感分析结果(积极情感、消极情感)等等。
示例:下方图片是一个语音识别项目的机器学习管道,由三个组件组成:特征提取,音素识别器,末端识别器。

·端到端学习(End-to-end learning):
概念:一个机器学习管道中,可以由多个组件按照某种顺序组合而成;也可以由一个单一的学习算法构成。其中由单一学习算法构成的管道称为端到端学习。
例-包含多组件的学习管道(车辆自动驾驶项目):
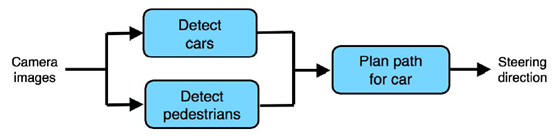
例-端到端学习(车辆自动驾驶项目):

近年来,在数据样本十分丰富的条件下,端到端学习展现出了非常强大的能力,取得了相当的成功。
·端到端学习的优缺点:
优点:过多“手工设计”的管道组件在进行编码、映射时有可能会丢失部分输入信息,而端到端学习将原始样本进行输入可以将信息全部保留;部分“手工设计”的管道组件并不是一个完美的模型,也许存在部分系统缺陷,端到端学习可以避免引入这部分缺陷;此外,端到端学习在可以应用在人类先验知识较为缺乏的领域。
缺点:由于没有“手工设计”管道组件的预处理步骤,端到端学习的过程相对复杂,需要更长的学习时间,使用更大的数据量。
·学习管道的组件(component)选择:
很多时候我们在数据量缺乏的时候,不能使用端到端学习,因此需要手工设计一个由多组件(模块)组成的学习管道。关于组件(模块)的选择,有以下两个注意事项:
数据可用性:如需将某个组件加入管道,要保证能够较为容易的获取相关数据来对这个组件进行训练。
任务简易性:即对于单个组件,避免使其执行复杂任务。
如在语音识别任务中,将特征提取工作分解成特征计算组件和音素识别两个组件;分别使用现有的MFCC特征提取法和基于语言学的音素识别算法,能够较为容易完成这两个组件的工作,保证了整个学习管道的易用性。
第十章(Error analysis by parts)笔记:
·分部错误分析:
在使用多组件管道进行深度学习任务的时候,一旦整体效果不佳,就需要对管道里的各个组件筛查,以确定哪些组件出了问题。这个筛查的过程就称作分部错误分析(Error analysis by parts)
方法:使用错误样本,输出每一个组件中间步骤的结果,人工对其进行判读,以确定哪些组件问题较大,有继续优化的空间。
例:在暹罗猫识别任务中,设计如下的学习管道:

第一个组件使用原始输入图片对猫咪进行识别,获取猫咪的部分传入第二个组件,第二个组件来判别猫咪是否为暹罗猫。
对于一个错误样本,如果第一个组件(猫咪识别组件)没有正确的将猫咪进行识别,得到类似下图(左)的结果,则可以判定第一个组件有问题;如果第一个组件能够正确识别出猫咪所在区域,得到类似下图(右)的结果,则可以判定第二个组件有问题。

取多个样本进行分部错误分析,对分析结果进行统计,可以判断出哪些组件需要优化提升。
·分部错误分析的一般流程:
错误组件定位流程概括:即从输入至输出的顺序对每个组件逐个排查。使用完美的(正确的)输出对该组件的输出进行替代,如经过替代后该组件可以最终得到正确输出,则判断该组件有问题。
例:对于汽车自动驾驶问题,学习管道如下。
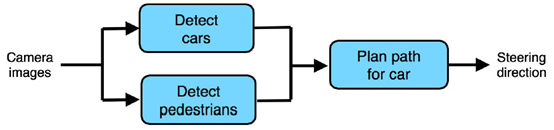
对于这个管道,错误组件定位的方式为:
步骤1:使用该错误样本进行输入,对汽车探测器组件的输出进行修改,使其变成正确的输出,行人探测器组件的输出结果不变,将这两个输出结果传入路径规划组件,如果能够输出正确的汽车运行路线,则说明汽车探测器组件存在问题。如果不能输出正确路线,则进入步骤2。
步骤2:使用该错误样本进行输入,对行人探测器的输出进行修改,使其变成完美的(正确的)输出,看管道能否生成正确的路线,能正确输出的话则说明行人探测器组件存在问题;如依然不能输出正确路线,转至步骤3。
步骤3:路径规划组件存在问题。
·使用人类的水平来对比每一个组件:
为了获得更加准确的输出结果和更强的鲁棒性,我们可以对管道中的每一个组件进行分析,以人类的水准来进行对比,尽可能多的强化学习管道的能力。
例如:在暹罗猫识别任务中,

①先看第一个组件,猫咪探测器的输出如下:

使用人类的水平进行对比,这个输出结果明显是不合格的,说明该组件拥有巨大的提升空间。
②再看第二个组件,猫咪类型探测器的输入:

对于一个猫咪爱好者来说,完全可以根据这个图片判断出来这是一只暹罗猫。证明第二个组件也没有达到人类的识别水平,依然拥有性能提升空间。
注意:一旦管道中所有的组件都达到了接近人类的水准,但管道依然无法提供正确的输出,则说明管道的设计存在问题,需要进行重新设计(新增组件或删改组件)。