分析性能测试结果图
正常情况下,并发越多,页面点击数(服务器每秒处理请求的能力),吞吐(服务器每秒返回数据量),tps(每秒通过的业务量)同步提高
遇到性能瓶颈时,并发越多,页面点击,吞吐,事务关系开始不同步,并开始出错情况,这种不同步情况就是拐点
首先并发上入手,如果并发很小情况下,比如就10个并发,指标上不去,很可能和网络带宽有关系,压测时候最好在局域网内部压测,这样可以忽略网络问题,不过就算内部网络,同时也要注意是否被其他人占用或者网管限速情况
其次,测试服务器性能有关系了,可以到服务器打开资源管理器,一般linux系列,直接到命令行用 top -c 可以准确看到具体程序资源占用情况,有的公司硬件自身配置比较低,或者部署了一堆软件,被压测应用性能肯定会受影响,有时候仅仅多分配些内存,程序的指标就能提高, 所以在不同软硬件环境下出现拐点位置都不太一样
最后,可以从程序自身优化入手,这时候需要分析压测的每个事物指标对应的时间结果,如果一个事物里面有5个接口,其中一个接口返回时间比较长,可以让开发针对该接口做程序优化,也是性能测试报告最后的重点。
图中的3条曲线,分别表示资源的利用情况(Utilization,包括硬件资源和软件资源)、吞吐量(Throughput,这里是指每秒事务数)以及响应时间(Response Time)。
曲线图主要分为3个区域,分别是:light load :轻压力区;heavy load :重压力区;和bockle load 。
图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。
在进行性能测试的时候,我们需要对图中曲线进行分析。分开来看的时候,相应时间(RT)、吞吐量(TPS)和资源利用率的变化情况分别是:
响应时间:随着并发用户数的增加,在前两个区,响应时间基本平稳,小幅递增。在第三个区域:急剧递增。在第三个区的点为拐点。
吞吐量:随着并发用户数的增加,在前两个区,对于一个良好的系统来说,并发用户数的增加,请求增加,吞吐量增加,中间的区域,处理达到顶点。
资源利用率:在第三个区呈直线,表示饱和。
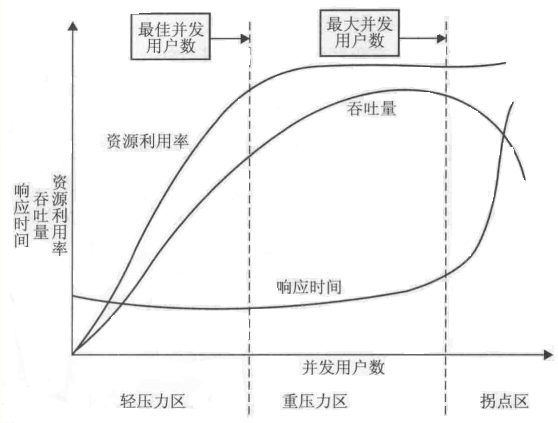
3条曲线合起分析:吞吐量下降,出现排队现象,服务器宕机,响应时间越来越大。
整体的分析思路:
当系统的负载等于最佳并发用户数时,系统的整体效率最高,没有资源被浪费,用户也不需要等待;
当系统负载处于最佳并发用户数和最大并发用户数之间时,系统可以继续工作,但是用户的等待时间延长,满意度开始降低,并且如果负载一直持续,将最终会导致有些用户无法忍受而放弃;
而当系统负载大于最大并发用户数时,将注定会导致某些用户无法忍受超长的响应时间而放弃。
如何去寻找性能负载测试中的拐点
1.逐步逼近法
先设定一个预估值进行测试,观察系统的响应情况,然后增加一定的数量,观察系统的变化,直到系统超出我们所预估的值。
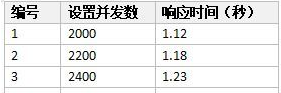
比如,在并发测试的时候,我们先预估设置并发用户为2000,然后以200的速度递增,检查系统的响应时间是否小与3秒,从而找出并发测试的系统拐点,数据如下:
。。。。。。
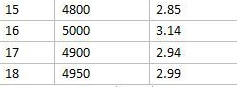
设置并发数为5000的时候,系统响应时间为3.14秒,超出了可接受范围,不继续增加了,在5000到4800中寻找一个中间值4900进行测试,测试结果为2.94秒,仍旧在可接受的范围之内,寻找4900与5000中的中间点4950进行测试,得到2.99这个结果,非常接近3了,且两次测量值的间隔在50之内(4950-5900=50)。
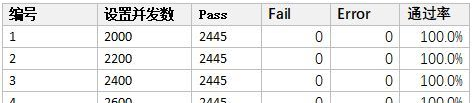
当我们对系统响应时间没有或者无法预估的时候,我们也往往采取系统通过率是否在可接受范围之内来评测。一般系统通过率可接受范围 = 通过的事务数(Pass)/全体事务数(All) = 通过的事务数(Pass)/(通过的事务数(Pass)+错误事务数(Error)+失败事务数(Fail))*100%,是否在95%以上(含95)。同样我们拿上一个例子作为参考。
。。。。。。

在这里系统的拐点为7150(一般设置通过的事务数在可接受的范围内,系统的拐点值回比其他方式高)。
2.二分逼近法
先预估两个值m和n,其中m<n,取值公式为一个二元函数f (m,n)。
1.先用m来进行测试,如果测试不通过,我们可以确定,拐点值小于m,也可以说在0到m之间,所以我们以m/2 为a来作为最小值,重新递归二元函数f (m/2,n)即f(a,n)。
2.如果m通过测试了,我们就用n值来进行测试,如果n值测试不通过,我们可以确定拐点在m与n之间,于是取(m+n)/2作为k值,重新递归二元函数f((m+n)/2,n)即f(k,n)。
3.如果n值测试通过了,我们拐点比n大,找一个比n大的数字x,重新递归二元函数f (n,x)。
4.当最大值与最小值在500内,认为找到拐点
在这里我们用这个方法来检查系统的响应时间是否小与3秒,从而找出并发测试的系统拐点。我们取初始的m为1000,n为5000,即f (1000, 5000)
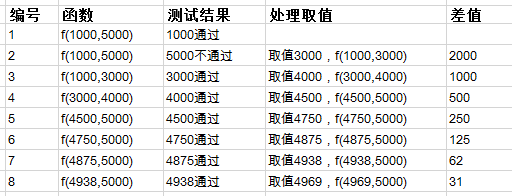
认为拐点值为4969,与第一次方法获得的值4950应该比较接近。在第一种方法中我们测试了18步,而采用这种方法仅仅用了8步。
对于并发测试,拐点是不太明晰的,所以第一次找到拐点的时候最好做二到三次的确认。